Introduction
Welcome to my book for leetcode problems. Here you can find meaningful problems from Leetcode and my explantions of solutions.
Main Programming Languages used in solutions
- Rust
- Java (Sometimes replaced by C++)
Kind Reminder
- There are many solutions, please use search to find solutions.
- The web will be updated very slowly because explaining each solved problem will be time-consuming.
- Some problems do not contain explanation because the code explains itself.
- Some problems do not contain complexity analysis.
Update Notes
Problems sorted by numbers
- 1. Two Sum
- 2. Add Two Numbers
- 3. Longest Substring Without Repeating Characters
- 6. Zigzag Conversion
- 7. Reverse Integer
- 9. Palindrome Number
- 11. Container With Most Water
- 12. Integer to Roman
- 13. Roman to Integer
- 17. Letter Combination of a Phone Number
- 19. Remove Nth Node From End of List
- 20. Valid Parentheses
- 21. Merge Two Sorted Lists
- 22. Generate Parentheses
- 24. Swap Nodes in Pairs
- 26. Remove Duplicates from Sorted Array
- 27. Remove Element
- 31. Next Permutation
- 36. Valid Sudoku
- 39. Combination Sum
- 46. Permutations
- 47. Permutations II
- 48. Rotate Image
- 50. Pow(../x, n)
- 54. Spiral Matrix
- 55. Jump Game
- 58. Length of Last Word
- 59. Spiral Matrix II
- 60. Permutation Sequence
- 62. Unique Paths
- 64. Minimum Path Sum
- 65. Valid Number
- 66. Plus One
- 70. Climbing Stairs
- 78. Subsets
- 83. Remove Duplicates from Sorted List
- 94. Binary Tree Inorder Traversal
- 98. Validate Binary Search Tree
- 100. Same Tree
- 104. Maximum Depth of Binary Tree
- 111. Minimum Depth of Binary Tree
- 112. Path Sum
- 113. Path Sum II
- 118. Pascal's Triangle
- 119. Pascal's Triangle II
- 125. Valid Palindrome
- 136. Single Number
- 141. Linked List Cycle
- 143. Reorder List
- 144. Binary Tree Preorder Traversal
- 145. Binary Tree Postorder Traversal
- 150. Evaluate Reverse Polish Notation
- 151. Reverse Words in a String
- 155. Min Stack
- 167. Two Sum II - Input Array Is Sorted
- 175. Combine Two Tables
- 176. Second Highest Salary
- 177. Nth Highest Salary
- 178. Rank Scores
- 179. Largest Number
- 180. Consecutive Numbers
- 181. Employees Earning More Than Their Managers
- 182. Duplicate Emails
- 183. Customers Who Never Order
- 184. Department Highest Salary
- 185. Department Top Three Salaries
- 191. Number of 1 Bits
- 193. Valid Phone Numbers
- 195. Tenth Line
- 196. Delete Duplicate Emails
- 197. Rising Temperature
- 198. House Robber
- 199. Binary Tree Right Side View
- 203. Remove Linked List Elements
- 206. Reverse Linked Lists
- 207. Course Schedule
- 208. Implement Trie (../Prefix Tree)
- 210. Course Schedule II
- 215. Kth Largest Element in an Array
- 216. Combination Sum III
- 217. Contains Duplicate
- 226. Invert Binary Tree
- 231. Power of Two
- 234. Palindrome Linked List
- 237. Delete Node in a Linked List
- 238. Product of Array Except Self
- 239. Sliding Window Maximum
- 242. Valid Anagram
- 262. Trips and Users
- 279. Perfect Squares
- 283. Move Zeroes
- 292. Nim Game
- 295. Find Median from Data Stream
- 322. Coin Change
- 328. Odd Even Linked List
- 334. Increasing Triplet Subsequence
- 338. Counting Bits
- 344. Reverse String
- 345. Reverse Vowels of a String
- 347. Top K Frequent Elements
- 371. Sum of Two Integers
- 374. Guess Number Higher or Lower
- 375. Guess Number Higher or Lower II
- 392. Is Subsequence
- 435. Non-overlapping Intervals
- 443. String Compression
- 452. Minimum Number of Arrows to Burst Balloons
- 511. Game Play Analysis I
- 518. Coin Change II
- 547. Number of Provinces
- 550. Game Play Analysis IV
- 570. Managers with at Least 5 Direct Reports
- 577. Employee Bonus
- 584. Find Customer Referee
- 585. Investments in 2016
- 586. Customer Placing the Largest Number of Orders
- 595. Big Countries
- 596. Classes More Than 5 Students
- 601. Human Traffic of Stadium
- 602. Friend Requests II: Who Has the Most Friends
- 607. Sales Person
- 608. Tree Node
- 610. Triangle Judgement
- 619. Biggest Single Number
- 620. Not Boring Movies
- 626. Exchange Seats
- 627. Swap Salary
- 643. Maximum Average Subarray I
- 700. Search in a Binary Search Tree
- 709. To Lower Case
- 724. Find Pivot Index
- 739. Daily Temperatures
- 746. Min Cost Climbing Stairs
- 790. Domino and Tromino Tiling
- 841. Keys and Rooms
- 872. Leaf-Similar Trees
- 876. Middle of the Linked List
- 897. Increasing Order Search Tree
- 901. Online Stock Span
- 933. Number of Recent Calls
- 1004. Max Consecutive Ones III
- 1045. Customers Who Bought All Products
- 1050. Actors and Directors Who Cooperated At Least Three Times
- 1068. Product Sales Analysis I
- 1070. Product Sales Analysis III
- 1071. Greatest Common Divisor of Strings
- 1075. Project Employees I
- 1084. Sales Analysis III
- 1137. N-th Tribonacci Number
- 1141. User Activity for the Past 30 Days I
- 1143. Longest Common Subsequence
- 1148. Article Views I
- 1158. Market Analysis I
- 1161. Maximum Level Sum of a Binary Tree
- 1164. Product Price at a Given Date
- 1174. Immediate Food Delivery II
- 1179. Reformat Department Table
- 1193. Monthly Transactions I
- 1204. Last Person to Fit in the Bus
- 1207. Unique Number of Occurrences
- 1211. Queries Quality and Percentage
- 1220. Count Vowels Permutation
- 1251. Average Selling Price
- 1268. Search Suggestions System
- 1280. Students and Examinations
- 1286. Iterator for Combination
- 1290. Convert Binary Number in a Linked List to Integer
- 1318. Minimum Flips to Make a OR b Equal to c
- 1321. Restaurant Growth
- 1327. List the Products Ordered in a Period
- 1341. Movie Rating
- 1378. Replace Employee ID With The Unique Identifier
- 1393. Capital Gain/Loss
- 1407. Top Travellers
- 1431. Kids With the Greatest Number of Candies
- 1448. Count Good Nodes in Binary Tree
- 1456. Maximum Number of Vowels in a Substring of Given Length
- 1484. Group Sold Products By The Date
- 1486. XOR Operation in an Array
- 1493. Longest Subarray of 1's After Deleting One Element
- 1517. Find Users With Valid E-Mails
- 1527. Patients With a Condition
- 1581. Customer Who Visited but Did Not Make Any Transactions
- 1587. Bank Account Summary II
- 1633. Percentage of Users Attended a Contest
- 1657. Determine if Two Strings Are Close
- 1661. Average Time of Process per Machine
- 1667. Fix Names in a Table
- 1683. Invalid Tweets
- 1693. Daily Leads and Partners
- 1704. Determine if String Halves Are Alike
- 1729. Find Followers Count
- 1731. The Number of Employees Which Report to Each Employee
- 1732. Find the Highest Altitude
- 1741. Find Total Time Spent by Each Employee
- 1757. Recyclable and Low Fat Products
- 1768. Merge Strings Alternately
- 1789. Primary Department for Each Employee
- 1795. Rearrange Products Table
- 1822. Sign of the Product of an Array
- 1873. Calculate Special Bonus
- 1890. The Latest Login in 2020
- 1907. Count Salary Categories
- 1926. Nearest Exit from Entrance in Maze
- 1929. Concatenation of Array
- 1934. Confirmation Rate
- 1965. Employees With Missing Information
- 1967. Number of Strings That Appear as Substrings in Word
- 1978. Employees Whose Manager Left the Company
- 1991. Find the Middle Index in Array
- 2095. Delete the Middle Node of a Linked List
- 2130. Maximum Twin Sum of a Linked List
- 2215. Find the Difference of Two Arrays
- 2235. Add Two Integers
- 2331. Evaluate Boolean Binary Tree
- 2336. Smallest Number in Infinite Set
- 2352. Equal Row and Column Pairs
- 2356. Number of Unique Subjects Taught by Each Teacher
- 2390. Removing Stars From a String
- 2703. Return Length of Arguments Passed
- 2723. Add Two Promises
- 2807. Insert Greatest Common Divisors in Linked List
- 3220. Odd and Even Transactions
My Picks - SQL
Join
- 184. Department Highest Salary
- 550. Game Play Analysis IV
- 1158. Market Analysis I
- 1251. Average Selling Price
- 1280. Students and Examinations
- 1407. Top Travellers
- 1661. Average Time of Process per Machine
Grouping
LIMIT and OFFSET
Subquery
A very good example for Subquery. Especially for EXISTS and NOT EXISTS:
- 183. Customers Who Never Order
- 1084. Sales Analysis III
- 1978. Employees Whose Manager Left the Company
These are very difficult but worth to do:
Advanced Functions
- 178. Rank Scores
- 1193. Monthly Transactions I
- 1204. Last Person to Fit in the Bus
- 1321. Restaurant Growth
- 1484. Group Sold Products By The Date
- 1934. Confirmation Rate
Some "Creativity" and "Tricks"
- 180. Consecutive Numbers
- 262. Trips and Users
- 601. Human Traffic of Stadium
- 608. Tree Node
- 626. Exchange Seats
- 627. Swap Salary
- 1164. Product Price at a Given Date
- 1341. Movie Rating
- 1965. Employees With Missing Information
SQL 50
SELECT
- 1757. Recyclable and Low Fat Products
- 584. Find Customer Referee
- 595. Big Countries
- 1148. Article Views I
- 1683. Invalid Tweets
Basic Joins
- 1378. Replace Employee ID With The Unique Identifier
- 1068. Product Sales Analysis I
- 1581. Customer Who Visited but Did Not Make Any Transactions
- 197. Rising Temperature
- 1661. Average Time of Process per Machine
- 577. Employee Bonus
- 1280. Students and Examinations
- 570. Managers with at Least 5 Direct Reports
- 1934. Confirmation Rate
Basic Aggregate Functions
- 620. Not Boring Movies
- 1251. Average Selling Price
- 1075. Project Employees I
- 1633. Percentage of Users Attended a Contest
- 1211. Queries Quality and Percentage
- 1193. Monthly Transactions I
- 1174. Immediate Food Delivery II
- 550. Game Play Analysis IV
Sorting and Grouping
- 2356. Number of Unique Subjects Taught by Each Teacher
- 1141. User Activity for the Past 30 Days I
- 1070. Product Sales Analysis III
- 596. Classes More Than 5 Students
- 1729. Find Followers Count
- 619. Biggest Single Number
- 1045. Customers Who Bought All Products
Advanced Select and Joins
- 1731. The Number of Employees Which Report to Each Employee
- 1789. Primary Department for Each Employee
- 610. Triangle Judgement
- 180. Consecutive Numbers
- 1164. Product Price at a Given Date
- 1204. Last Person to Fit in the Bus
- 1907. Count Salary Categories
Subqueries
- 1978. Employees Whose Manager Left the Company
- 626. Exchange Seats
- 1341. Movie Rating
- 1321. Restaurant Growth
- 602. Friend Requests II: Who Has the Most Friends
- 585. Investments in 2016
- 185. Department Top Three Salaries
Advanced String Functions / Regex / Clause
- 1667. Fix Names in a Table
- 1527. Patients With a Condition
- 196. Delete Duplicate Emails
- 176. Second Highest Salary
- 1484. Group Sold Products By The Date
- 1327. List the Products Ordered in a Period
- 1517. Find Users With Valid E-Mails
LeetCode 75 (In Progress)
Array / String
- 1768. Merge Strings Alternately
- 1071. Greatest Common Divisor of Strings
- 1431. Kids With the Greatest Number of Candies
-
- Can Place Flowers
- 345. Reverse Vowels of a String
- 151. Reverse Words in a String
- 238. Product of Array Except Self
- 334. Increasing Triplet Subsequence
- 443. String Compression
Two Pointers
- 283. Move Zeroes
- 392. Is Subsequence
- 11. Container With Most Water
-
- Max Number of K-Sum Pairs
Sliding Window
- 643. Maximum Average Subarray I
- 1456. Maximum Number of Vowels in a Substring of Given Length
- 1004. Max Consecutive Ones III
- 1493. Longest Subarray of 1's After Deleting One Element
Prefix Sum
Hash Map / Set
- 2215. Find the Difference of Two Arrays
- 1207. Unique Number of Occurrences
- 1657. Determine if Two Strings Are Close
- 2352. Equal Row and Column Pairs
Stack
- 2390. Removing Stars From a String
- 735. Asteroid Collision
-
- Decode String
Queue
- 933. Number of Recent Calls
-
- Dota2 Senate
Linked List
- 2095. Delete the Middle Node of a Linked List
- 328. Odd Even Linked List
- 206. Reverse Linked Lists
- 2130. Maximum Twin Sum of a Linked List
Binary Tree - DFS
- 104. Maximum Depth of Binary Tree
- 872. Leaf-Similar Trees
- 1448. Count Good Nodes in Binary Tree
-
- Path Sum III
-
- Longest ZigZag Path in a Binary Tree
-
- Lowest Common Ancestor of a Binary Tree
Binary Tree - BFS
Binary Search Tree
- 700. Search in a Binary Search Tree
-
- Delete Node in a BST
Graphs - DFS
- 841. Keys and Rooms
- 547. Number of Provinces
-
- Reorder Routes to Make All Paths Lead to the City Zero
-
- Evaluate Division
Graphs - BFS
Heap / Priority Queue
- 215. Kth Largest Element in an Array
- 2336. Smallest Number in Infinite Set
-
- Maximum Subsequence Score
-
- Total Cost to Hire K Workers
Binary Search
- 374. Guess Number Higher or Lower
-
- Successful Pairs of Spells and Potions
-
- Find Peak Element
-
- Koko Eating Bananas
Backtracking
DP - 1D
- 1137. N-th Tribonacci Number
- 746. Min Cost Climbing Stairs
- 198. House Robber
- 790. Domino and Tromino Tiling
DP - Multidimensional
- 62. Unique Paths
- 1143. Longest Common Subsequence
-
- Best Time to Buy and Sell Stock with Transaction Fee
-
- Edit Distance
Bit Manipulation
Trie
Intervals
Monotonic Stack
1. Two Sum
Description of the Problem
Given an array of integers nums and an integer target, return indices of the two numbers such that they add up to target.
You may assume that each input would have exactly one solution, and you may not use the same element twice.
You can return the answer in any order.
Example 1:
Input: nums = [2,7,11,15], target = 9
Output: [0,1]
Explanation: Because nums[0] + nums[1] == 9, we return [0, 1].
Example 2:
Input: nums = [3,2,4], target = 6
Output: [1,2]
Example 3:
Input: nums = [3,3], target = 6
Output: [0,1]
Constraints:
2 <= nums.length <= 10^4-10^9 <= nums[i] <= 10^9-10^9 <= target <= 10^9- Only one valid answer exists.
Follow-up: Can you come up with an algorithm that is less than \(O(n^2)\) time complexity?
Solution
Tags: HashMap
Explanation
if num[i]+num[j]==target then return [i,j];
<===>
if num[i]==target-num[j] then return [i,j];
Code (Rust)
#![allow(unused)] fn main() { use std::collections::HashMap; impl Solution { pub fn two_sum(nums: Vec<i32>, target: i32) -> Vec<i32> { let mut hashMap = HashMap::new(); for i in 0..nums.len(){ let complement = target - nums[i]; if hashMap.contains_key(&complement){ return vec![ i as i32 , hashMap[&complement] as i32 ]; } hashMap.insert(nums[i], i); } return vec![]; } } }
Code (Java)
import java.util.HashMap;
public class Solution_2 {
public int[] twoSum(int [] nums, int target){
// It stores (num->index)
HashMap <Integer,Integer> hashmap = new HashMap();
for(int i = 0; i < nums.length; i++){
int complement = target - nums[i];
if ( hashmap.containsKey(complement) ){
return new int[] { hashmap.get(complement), i};
}
hashmap.put(nums[i], i);
}
return null;
}
}
Complexity
- n is length of the array
Time complexity:
- \( T(n) = O(n) \)
- Assume hashMap get/put use constant time
Auxiliary Space:
- \( S(n) = O(2n) \)
- It store at most 2n (key and value) elements in HashMap
9. Palindrome Number
Description
Given an integer x, return true if x is a palindrome, and false otherwise.
Example 1:
Input: x = 121
Output: true
Explanation: 121 reads as 121 from left to right and from right to left.
Example 2:
Input: x = -121
Output: false
Explanation: From left to right, it reads -121. From right to left, it becomes 121-. Therefore it is not a palindrome.
Example 3:
Input: x = 10
Output: false
Explanation: Reads 01 from right to left. Therefore it is not a palindrome.
Constraints:
-2^31 <= x <= 2^31 - 1
Follow up: Could you solve it without converting the integer to a string?
Solution
Explanation
In order to solve the problem without converting the integer to a string, we use numerical way to solve the problem.
If the number is negative, it can never be palindrome. If the number is positive, we can mirror the number to see whether it is equal to the original number.
Code (Rust)
impl Solution {
// Numerical Way
pub fn is_palindrome(x: i32) -> bool {
if x < 0 {
return false;
}
else{
let mut sum = 0;
let mut x_copy = x;
while x_copy > 0{
sum *= 10; // Sum shifts left by 1
sum += x_copy % 10; // Extract digit
x_copy /= 10; // x_copy shifts right by 1
}
return sum == x;
}
}
}
Complexity
- n is the number of digits of input number
Time complexity:
- \( T(n) = O(n) \)
Auxiliary Space:
- \( S(n) = O(1) \)
13. Roman to Integer
Description of the Problem
Roman numerals are represented by seven different symbols: I, V, X, L, C, D and M.
Symbol Value
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
For example, 2 is written as II in Roman numeral, just two ones added together. 12 is written as XII, which is simply X + II. The number 27 is written as XXVII, which is XX + V + II.
Roman numerals are usually written largest to smallest from left to right. However, the numeral for four is not IIII. Instead, the number four is written as IV. Because the one is before the five we subtract it making four. The same principle applies to the number nine, which is written as IX. There are six instances where subtraction is used:
Ican be placed beforeV(5) andX(10) to make 4 and 9.Xcan be placed beforeL(50) andC(100) to make 40 and 90.Ccan be placed beforeD(500) andM(1000) to make 400 and 900. Given a roman numeral, convert it to an integer.
Example 1:
Input: s = "III"
Output: 3
Explanation: III = 3.
Example 2:
Input: s = "LVIII"
Output: 58
Explanation: L = 50, V= 5, III = 3.
Example 3:
Input: s = "MCMXCIV"
Output: 1994
Explanation: M = 1000, CM = 900, XC = 90 and IV = 4.
Constraints:
1 <= s.length <= 15scontains only the characters('I', 'V', 'X', 'L', 'C', 'D', 'M').- It is guaranteed that s is a valid roman numeral in the range
[1, 3999].
Solution
Explanation
The solution is less intutive. We observe that the subtraction only occurs when there is 2 characters; otherwise, it is addition.
Thus, the solution use two pointers method to scan over the string. If it is addition, add the current number and move the pointers to right by 1; otherwise, compute the subtraction and move the pointers to right by 2.
Code (Rust)
impl Solution {
#[inline(always)]
fn get_int(c : char) -> i32 {
return match c {
'I' => 1,
'V' => 5,
'X' => 10,
'L' => 50,
'C' => 100,
'D' => 500,
'M' => 1000,
_ => 0,
};
}
pub fn roman_to_int(s: String) -> i32 {
let n = s.len();
let array : Vec<_> = s.chars().collect();
let (mut p1, mut p2) = (0,1);
let mut sum = 0;
while p1 < n {
let n1 = Solution::get_int(array[p1]);
let n2 = if p2 < n { Solution::get_int(array[p2]) } else { 0 };
if n1 >= n2 {
sum += n1;
p1 +=1; p2 +=1;
}else{
sum += n2 - n1;
p1 +=2; p2 +=2;
}
}
return sum;
}
}
Complexity
- n is length of string
Time complexity:
- \( T(n) = O(n) \)
Auxiliary Space:
- \( S(n) = O(1) \)
20. Valid Parentheses
Description of the Problem
Given a string s containing just the characters '(', ')', '{', '}','[' and ']', determine if the input string is valid.
An input string is valid if:
- Open brackets must be closed by the same type of brackets.
- Open brackets must be closed in the correct order.
- Every close bracket has a corresponding open bracket of the same type.
Example 1:
Input: s = "()"
Output: true
Example 2:
Input: s = "()[]{}"
Output: true
Example 3:
Input: s = "(]"
Output: false
Constraints:
1 <= s.length <= 10^4sconsists of parentheses only'()[]{}'.
Solution
Tags: Stack
Code(Rust)
impl Solution {
pub fn is_valid(s: String) -> bool {
let mut stack = Vec::new();
for i in s.chars() {
match i {
'{' => stack.push('}'),
'(' => stack.push(')'),
'[' => stack.push(']'),
'}'|')'|']' if Some(i) != stack.pop() => return false,
_ => (),
}
}
return stack.is_empty();
}
}
Complexity
- n is the length of string
Time complexity:
- \( T(n) = O(n) \)
Auxiliary Space:
- \( S(n) = O(n) \)
21. Merge Two Sorted Lists
Description of the Problem
You are given the heads of two sorted linked lists list1 and list2.
Merge the two lists into one sorted list. The list should be made by splicing together the nodes of the first two lists.
Return the head of the merged linked list.
Example 1:
Input: list1 = [1,2,4], list2 = [1,3,4]
Output: [1,1,2,3,4,4]
Example 2:
Input: list1 = [], list2 = []
Output: []
Example 3:
Input: list1 = [], list2 = [0]
Output: [0]
Constraints:
- The number of nodes in both lists is in the range
[0, 50]. -100 <= Node.val <= 100- Both
list1andlist2are sorted in non-decreasing order.
Solution 1 (Java and C++)
Tags: Sorting, LinkedList
Explantion
Since two lists are sorted. By comparing the smallest elements of each array, we know the smallest element of the merged list.
Code (Java)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
ListNode dummyHead = new ListNode(0);
ListNode curr = dummyHead;
while(list1 != null && list2 != null){
if(list1.val < list2.val){
curr.next = list1;
list1 = list1.next;
}
else{
curr.next = list2;
list2 = list2.next;
}
curr = curr.next;
}
if(list1 != null){
curr.next = list1;
}else{
curr.next = list2;
}
return dummyHead.next;
}
}
Code (C++)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
ListNode * dummyHead = new ListNode();
ListNode * curr = dummyHead;
while (list1 != nullptr && list2 != nullptr){
if(list1->val <= list2->val){
curr->next = list1;
list1 = list1->next;
}
else{
curr->next = list2;
list2 = list2->next;
}
curr = curr->next;
}
while (list1 != nullptr){
curr->next = list1;
list1 = list1->next;
curr = curr->next;
}
while (list2 != nullptr){
curr->next = list2;
list2 = list2->next;
curr = curr->next;
}
return dummyHead->next;
}
};
Complexity
- m and n are the number of elements of lists
Time complexity:
- \( T(n) = O(m+n) \)
Auxiliary Space:
- \( S(n) = O(1) \)
- We added no extra node except the dummy head
Solution 2 - Rust
Tags: Rust LinkedList
Code (Rust)
// Definition for singly-linked list.
// #[derive(PartialEq, Eq, Clone, Debug)]
// pub struct ListNode {
// pub val: i32,
// pub next: Option<Box<ListNode>>
// }
//
// impl ListNode {
// #[inline]
// fn new(val: i32) -> Self {
// ListNode {
// next: None,
// val
// }
// }
// }
impl Solution {
pub fn merge_two_lists(list1: Option<Box<ListNode>>, list2: Option<Box<ListNode>>) -> Option<Box<ListNode>> {
let mut left_head = list1;
let mut right_head = list2;
let mut curr_head = None;
while left_head.is_some() && right_head.is_some() {
if let (Some(mut left_node), Some(mut right_node)) = (left_head.take(), right_head.take()){
if left_node.val < right_node.val {
left_head = left_node.next.take();
right_head = Some(right_node);
if curr_head.is_some(){
left_node.next = curr_head;
}
curr_head = Some(left_node);
}else{
right_head = right_node.next.take();
left_head = Some(left_node);
if curr_head.is_some(){
right_node.next = curr_head;
}
curr_head = Some(right_node);
}
}
}
while let Some(mut left_node) = left_head.take(){
left_head = left_node.next.take();
if curr_head.is_some(){
left_node.next = curr_head;
}
curr_head = Some(left_node);
}
while let Some(mut right_node) = right_head.take(){
right_head = right_node.next.take();
if curr_head.is_some(){
right_node.next = curr_head;
}
curr_head = Some(right_node);
}
return Solution::reverse_list(curr_head);
}
#[inline(always)]
fn reverse_list(head: Option<Box<ListNode>>) -> Option<Box<ListNode>>{
let mut curr = head;
let mut prev = None;
while let Some(mut node) = curr.take(){
curr = node.next;
node.next = prev;
prev = Some(node);
}
return prev;
}
}
Complexity
- m and n are the number of elements of lists
Time complexity:
- \( T(n) = O(m+n) \)
Auxiliary Space:
- \( S(n) = O(1) \)
- We added no extra node except the dummy head
26. Remove Duplicates from Sorted Array
Description of Problem
Given an integer array nums sorted in non-decreasing order, remove the duplicates in-place such that each unique element appears only once. The relative order of the elements should be kept the same. Then return the number of unique elements in nums.
Consider the number of unique elements of nums to be k, to get accepted, you need to do the following things:
- Change the array
numssuch that the firstkelements ofnumscontain the unique elements in the order they were present innumsinitially. The remaining elements ofnumsare not important as well as the size ofnums. - Return
k.
Custom Judge:
The judge will test your solution with the following code:
int[] nums = [...]; // Input array
int[] expectedNums = [...]; // The expected answer with correct length
int k = removeDuplicates(nums); // Calls your implementation
assert k == expectedNums.length;
for (int i = 0; i < k; i++) {
assert nums[i] == expectedNums[i];
}
If all assertions pass, then your solution will be accepted.
Example 1:
Input: nums = [1,1,2]
Output: 2, nums = [1,2,_]
Explanation: Your function should return k = 2, with the first two elements of nums being 1 and 2 respectively.
It does not matter what you leave beyond the returned k (hence they are underscores).
Example 2:
Input: nums = [0,0,1,1,1,2,2,3,3,4]
Output: 5, nums = [0,1,2,3,4,_,_,_,_,_]
Explanation: Your function should return k = 5, with the first five elements of nums being 0, 1, 2, 3, and 4 respectively.
It does not matter what you leave beyond the returned k (hence they are underscores).
Constraints:
1 <= nums.length <= 3 * 10^4-100 <= nums[i] <= 100numsis sorted in non-decreasing order.
Solution
Code (Rust)
impl Solution {
pub fn remove_duplicates(nums: &mut Vec<i32>) -> i32 {
let n = nums.len();
if n == 0 {
return 0;
}
let mut new_len = 1;
let mut prev = nums[0];
for i in 1..n {
if prev != nums[i] {
prev = nums[i];
nums[new_len] = prev;
new_len += 1;
}
}
return new_len as i32;
}
}
Code (Java)
class Solution {
public int removeDuplicates(int[] nums) {
int n = nums.length;
if (n == 0) {
return 0;
}
int newLength = 1;
int prevEle = nums[0];
for(int i = 0; i < n; i++){
int currEle = nums[i];
if ( currEle != prevEle){
nums[newLength] = currEle;
prevEle = currEle;
newLength++;
}
}
return newLength;
}
}
Complexity
- n is number of elements in the array.
Time complexity:
- \( T(n) = O(n) \)
Auxiliary Space:
- \( S(n) = O(1) \)
27. Remove Element
Description of the Problem
Given an integer array nums and an integer val, remove all occurrences of val in nums in-place. The order of the elements may be changed. Then return the number of elements in nums which are not equal to val.
Consider the number of elements in nums which are not equal to val be k, to get accepted, you need to do the following things:
- Change the array
numssuch that the firstkelements ofnumscontain the elements which are not equal toval. The remaining elements ofnumsare not important as well as the size ofnums. - Return
k.
Custom Judge:
The judge will test your solution with the following code:
int[] nums = [...]; // Input array
int val = ...; // Value to remove
int[] expectedNums = [...]; // The expected answer with correct length.
// It is sorted with no values equaling val.
int k = removeElement(nums, val); // Calls your implementation
assert k == expectedNums.length;
sort(nums, 0, k); // Sort the first k elements of nums
for (int i = 0; i < actualLength; i++) {
assert nums[i] == expectedNums[i];
}
If all assertions pass, then your solution will be accepted.
Example 1:
Input: nums = [3,2,2,3], val = 3
Output: 2, nums = [2,2,_,_]
Explanation: Your function should return k = 2, with the first two elements of nums being 2.
It does not matter what you leave beyond the returned k (hence they are underscores).
Example 2:
Input: nums = [0,1,2,2,3,0,4,2], val = 2
Output: 5, nums = [0,1,4,0,3,_,_,_]
Explanation: Your function should return k = 5, with the first five elements of nums containing 0, 0, 1, 3, and 4.
Note that the five elements can be returned in any order.
It does not matter what you leave beyond the returned k (hence they are underscores).
Constraints:
0 <= nums.length <= 1000 <= nums[i] <= 500 <= val <= 100
Solution
You can also see Rust 2-line solution provided by other user.
Code (Rust)
impl Solution {
pub fn remove_element(nums: &mut Vec<i32>, val: i32) -> i32 {
let n = nums.len();
if n == 0 {
return 0;
}
let mut new_len = 0;
for i in 0..n {
if nums[i] != val {
nums[new_len] = nums[i];
new_len+=1;
}
}
return new_len as i32;
}
}
Complexity
- n is number of elements in the array.
Time complexity:
- \( T(n) = O(n) \)
Auxiliary Space:
- \( S(n) = O(1) \)
58. Length of Last Word
Description of the Problem
Given a string s consisting of words and spaces, return the length of the last word in the string.
A word is a maximal substring consisting of non-space characters only.
Example 1:
Input: s = "Hello World"
Output: 5
Explanation: The last word is "World" with length 5.
Example 2:
Input: s = " fly me to the moon "
Output: 4
Explanation: The last word is "moon" with length 4.
Example 3:
Input: s = "luffy is still joyboy"
Output: 6
Explanation: The last word is "joyboy" with length 6.
Constraints:
1 <= s.length <= 10^4sconsists of only English letters and spaces' '. There will be at least one word ins.
Solution
Code (Rust)
impl Solution {
pub fn length_of_last_word(s: String) -> i32 {
let mut count = 0;
for c in s.chars().rev() {
match (c==' ', count == 0) {
(false, _) => count += 1,
(true, false) => return count,
(true, true) => {}
}
}
return count;
}
}
Complexity
- n the length of string
s
Time Complexity:
- \(T(n) = O(n)\)
Auxiliary Space:
- \(T(n) = O(1)\)
66. Plus One
Description of Problem
You are given a large integer represented as an integer array digits, where each digits[i] is the ith digit of the integer. The digits are ordered from most significant to least significant in left-to-right order. The large integer does not contain any leading 0's.
Increment the large integer by one and return the resulting array of digits.
Example 1:
Input: digits = [1,2,3]
Output: [1,2,4]
Explanation: The array represents the integer 123.
Incrementing by one gives 123 + 1 = 124.
Thus, the result should be [1,2,4].
Example 2:
Input: digits = [4,3,2,1]
Output: [4,3,2,2]
Explanation: The array represents the integer 4321.
Incrementing by one gives 4321 + 1 = 4322.
Thus, the result should be [4,3,2,2].
Example 3:
Input: digits = [9]
Output: [1,0]
Explanation: The array represents the integer 9.
Incrementing by one gives 9 + 1 = 10.
Thus, the result should be [1,0].
Constraints:
1 <= digits.length <= 1000 <= digits[i] <= 9digitsdoes not contain any leading0's.
Solution
Code (Java)
class Solution {
public int[] plusOne(int[] digits) {
int carry = 1;
for(int i = digits.length - 1; i >= 0; i--){
int sum = digits[i] + carry;
carry = sum >= 10 ? 1 : 0;
digits[i] = sum % 10;
}
if (carry > 0){
int [] new_digits = new int[digits.length + 1];
new_digits[0] = carry;
/*
for(int i = 0; i < digits.length; i++){
new_digits[i+1] = digits[i];
}
*/
return new_digits;
}else{
return digits;
}
}
}
Complexity
- n is length of
digits
Time Complexity
- \(T(n)=O(n)\)
Auxiliary Space
- \(S(n)=O(1)\)
70. Climbing Stairs
Description of the Problem
You are climbing a staircase. It takes n steps to reach the top.
Each time you can either climb 1 or 2 steps. In how many distinct ways can you climb to the top?
Example 1:
Input: n = 2
Output: 2
Explanation: There are two ways to climb to the top.
1. 1 step + 1 step
2. 2 steps
Example 2:
Input: n = 3
Output: 3
Explanation: There are three ways to climb to the top.
1. 1 step + 1 step + 1 step
2. 1 step + 2 steps
3. 2 steps + 1 step
Constraints:
- 1 <= n <= 45
Solution
Explanation
Consider climbing a n-step stairs, how many possible ways can we climb to the top. We have two possible move; either move 1 step or 2 step.
Thus the problem becomes finding the sum of the number of ways in (n-1)-step staircase and in (n-2)-step staircase. (see the following equations)
\[ \begin{align} w_0 = & \ 1 \\ w_1 = & \ 1 \\ w_n = & \ w_{n-1} + w_{n-2} \\ \end{align} \]
Code (Rust)
impl Solution {
pub fn climb_stairs(n: i32) -> i32 {
let n = n as usize;
let mut dp = vec![0; n + 1];
dp[0] = 1;
dp[1] = 1;
for i in 2..=n{
dp[i] = dp[i-1] + dp[i-2];
}
return dp[n] as i32;
}
}
Complexity
Time complexity:
- \( T(n) = \Theta(n) \)
Auxiliary Space:
- \( S(n) = \Theta(n) \)
83. Remove Duplicates from Sorted List
Description of Problem
Given the head of a sorted linked list, delete all duplicates such that each element appears only once. Return the linked list sorted as well.
Example 1:
Input: head = [1,1,2]
Output: [1,2]
Example 2:
Input: head = [1,1,2,3,3]
Output: [1,2,3]
Constraints:
- The number of nodes in the list is in the range
[0, 300]. -100 <= Node.val <= 100- The list is guaranteed to be sorted in ascending order.
Solution
Tags: LinkedList
Code (Java)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode deleteDuplicates(ListNode head) {
if (head == null || head.next == null){
return head;
}
ListNode node1 = head;
ListNode node2 = head.next;
while(node2 != null){
if(node1.val == node2.val){
node1.next = node2.next;
node2 = node2.next;
}
else{
node1 = node1.next;
node2 = node2.next;
}
}
return head;
}
}
Code (C++)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (head == nullptr || head->next == nullptr){
return head;
}
ListNode* node1 = head;
ListNode* node2 = head->next;
while(node2 != nullptr){
if(node1->val == node2->val){
node1->next = node2->next;
node2 = node2->next;
}
else{
node1 = node1->next;
node2 = node2->next;
}
}
return head;
}
};
Complexity
- n is the number of elements in the linked list
Time Complexity
- \(T(n) = O(n)\)
Auxiliary Space
- \(S(n) = O(1)\)
94. Binary Tree Inorder Traversal
Description of Problem
Given the root of a binary tree, return the inorder traversal of its nodes' values.
Example 1:
Input: root = [1,null,2,3]
Output: [1,3,2]
Example 2:
Input: root = []
Output: []
Example 3:
Input: root = [1]
Output: [1]
Constraints:
- The number of nodes in the tree is in the range
[0, 100]. 100 <= Node.val <= 100
Follow up: Recursive solution is trivial, could you do it iteratively?
Solution (Failed to answer the follow-up)
Tags: Binary Tree Rust
Code (Rust) - Recursion
// Definition for a binary tree node.
// #[derive(Debug, PartialEq, Eq)]
// pub struct TreeNode {
// pub val: i32,
// pub left: Option<Rc<RefCell<TreeNode>>>,
// pub right: Option<Rc<RefCell<TreeNode>>>,
// }
//
// impl TreeNode {
// #[inline]
// pub fn new(val: i32) -> Self {
// TreeNode {
// val,
// left: None,
// right: None
// }
// }
// }
use std::borrow::BorrowMut;
use std::rc::Rc;
use std::cell::RefCell;
impl Solution {
pub fn inorder_traversal(root: Option<Rc<RefCell<TreeNode>>>) -> Vec<i32> {
let mut v : Vec<i32> = Vec::new();
Solution::helper(root, &mut v);
return v;
}
fn helper(node: Option<Rc<RefCell<TreeNode>>>, v : &mut Vec<i32>){
if let Some(node) = node{
let node = node.borrow();
Solution::helper(node.left.clone(), v);
v.push(node.val);
Solution::helper(node.right.clone(), v);
}
}
}
Complexity
- n is the number of elements in the tree
- h is the height of the tree
Time Complexity
- \( T(n) = O(n) \)
- Traverse all nodes in tree
Auxiliary Space
- \( S(h) = O(h) \)
100. Same Tree
Description of Problem
Given the roots of two binary trees p and q, write a function to check if they are the same or not.
Two binary trees are considered the same if they are structurally identical, and the nodes have the same value.
Example 1:
Input: p = [1,2,3], q = [1,2,3]
Output: true
Example 2:
Input: p = [1,2], q = [1,null,2]
Output: false
Example 3:
Input: p = [1,2,1], q = [1,1,2]
Output: false
Constraints:
- The number of nodes in both trees is in the range
[0, 100]. - -10^4 <= Node.val <= 10^4
Solution
Tags: Binary Tree, Rust
Code(Rust)
// Definition for a binary tree node.
// #[derive(Debug, PartialEq, Eq)]
// pub struct TreeNode {
// pub val: i32,
// pub left: Option<Rc<RefCell<TreeNode>>>,
// pub right: Option<Rc<RefCell<TreeNode>>>,
// }
//
// impl TreeNode {
// #[inline]
// pub fn new(val: i32) -> Self {
// TreeNode {
// val,
// left: None,
// right: None
// }
// }
// }
use std::rc::Rc;
use std::cell::RefCell;
impl Solution {
pub fn is_same_tree(p: Option<Rc<RefCell<TreeNode>>>, q: Option<Rc<RefCell<TreeNode>>>) -> bool {
match (p, q) {
(None, None) => return true,
(None, _) => return false,
(_, None) => return false,
(Some(p), Some(q)) => {
let p = p.borrow();
let q = q.borrow();
return p.val == q.val && Self::is_same_tree(p.left.clone(), q.left.clone()) && Self::is_same_tree(p.right.clone(), q.right.clone());
}
}
}
}
Code (C++)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
bool isSameTree(TreeNode* p, TreeNode* q) {
if(p == nullptr && q == nullptr){
return true;
}
else if(p != nullptr && q != nullptr){
return p->val == q->val && isSameTree(p->left, q->left) && isSameTree (p->right, q->right);
}
else{
return false;
}
}
};
Complexity
- n is the number of nodes in the tree
- h is the height of the tree
Time complexity:
- \( T(n) = O(n) \)
Auxiliary Space:
- \( S(n) = O(h) \)
104. Maximum Depth of Binary Tree
Description of Problem
Given the root of a binary tree, return its maximum depth.
A binary tree's maximum depth is the number of nodes along the longest path from the root node down to the farthest leaf node.
Example 1:
Input: root = [3,9,20,null,null,15,7]
Output: 3
Example 2:
Input: root = [1,null,2]
Output: 2
Constraints:
- The number of nodes in the tree is in the range
[0, 10^4]. -100 <= Node.val <= 100
Solution
Tags: Binary Tree Rust
Code (Rust)
// Definition for a binary tree node.
// #[derive(Debug, PartialEq, Eq)]
// pub struct TreeNode {
// pub val: i32,
// pub left: Option<Rc<RefCell<TreeNode>>>,
// pub right: Option<Rc<RefCell<TreeNode>>>,
// }
//
// impl TreeNode {
// #[inline]
// pub fn new(val: i32) -> Self {
// TreeNode {
// val,
// left: None,
// right: None
// }
// }
// }
use std::cmp;
use std::rc::Rc;
use std::cell::RefCell;
impl Solution {
pub fn max_depth(root: Option<Rc<RefCell<TreeNode>>>) -> i32 {
match root {
None => return 0,
Some(node) => {
let node = (*node).borrow();
return 1 + cmp::max(
Self::max_depth( node.left.clone() ),
Self::max_depth( node.right.clone() ),
)
}
}
}
}
Code (C++)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
if (root == nullptr){
return 0;
}
else{
return 1 + std::max( maxDepth(root->left), maxDepth(root->right) );
}
}
};
Complexity
- n is the number of nodes in the tree
- h is the height of the tree
Time complexity:
- \( T(n) = O(n) \)
Auxiliary Space:
- \( S(n) = O(h) \)
111. Minimum Depth of Binary Tree
Description of the Problem
Given a binary tree, find its minimum depth.
The minimum depth is the number of nodes along the shortest path from the root node down to the nearest leaf node.
Note: A leaf is a node with no children.
Example 1:
Input: root = [3,9,20,null,null,15,7]
Output: 2
Example 2:
Input: root = [2,null,3,null,4,null,5,null,6]
Output: 5
Constraints:
- The number of nodes in the tree is in the range
[0, 10^5]. -1000 <= Node.val <= 1000
Solution
Code (C++)
class Solution {
public:
int minDepth(TreeNode* root) {
if (root == nullptr) return 0;
int left = minDepth(root->left);
int right = minDepth(root->right);
return left == 0 ^ right == 0 ?
1 + std::max(left, right) :
1 + std::min(left, right);
}
};
Complexity
- n is the number of nodes in the tree
- h is the height of the tree
Time complexity:
- \( T(n) = O(n) \)
Auxiliary Space:
- \( S(n) = O(h) \)
112. Path Sum
Description of the Problem
Given the root of a binary tree and an integer targetSum, return true if the tree has a root-to-leaf path such that adding up all the values along the path equals targetSum.
A leaf is a node with no children.
Example 1:
Input: root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
Output: true
Explanation: The root-to-leaf path with the target sum is shown.
Example 2:
Input: root = [1,2,3], targetSum = 5
Output: false
Explanation: There two root-to-leaf paths in the tree:
(1 --> 2): The sum is 3.
(1 --> 3): The sum is 4.
There is no root-to-leaf path with sum = 5.
Example 3:
Input: root = [], targetSum = 0
Output: false
Explanation: Since the tree is empty, there are no root-to-leaf paths.
Constraints:
- The number of nodes in the tree is in the range
[0, 5000]. 1000 <= Node.val <= 10001000 <= targetSum <= 1000
Solution
Code (Rust)
// Definition for a binary tree node.
// #[derive(Debug, PartialEq, Eq)]
// pub struct TreeNode {
// pub val: i32,
// pub left: Option<Rc<RefCell<TreeNode>>>,
// pub right: Option<Rc<RefCell<TreeNode>>>,
// }
//
// impl TreeNode {
// #[inline]
// pub fn new(val: i32) -> Self {
// TreeNode {
// val,
// left: None,
// right: None
// }
// }
// }
use std::rc::Rc;
use std::cell::RefCell;
impl Solution {
pub fn has_path_sum(root: Option<Rc<RefCell<TreeNode>>>, target_sum: i32)
-> bool {
match (root) {
None => false,
Some(root) => {
let root = root.borrow();
if root.left.is_none()
&& root.right.is_none()
&& root.val == target_sum {
true
}else {
Solution::has_path_sum(
root.left.clone(), target_sum - root.val
)
|| Solution::has_path_sum(
root.right.clone(), target_sum - root.val
)
}
}
}
}
}
Complexity
- n is the number of nodes in the tree;
- h is the height of the tree
Time complexity:
- \( T(n) = O(n) \)
Auxiliary Space:
- \( S(n) = O(h) \)
118. Pascal's Triangle
Description of the Problem
Given an integer numRows, return the first numRows of Pascal's triangle.
In Pascal's triangle, each number is the sum of the two numbers directly above it as shown:
Example 1:
Input: numRows = 5
Output: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]]
Example 2:
Input: numRows = 1
Output: [[1]]
Constraints:
1 <= numRows <= 30
Solution
Explanation
In case you do not know Pascal Identity \( C^{n}_{r} = C^{n-1} _{r-1} + C^{n-1} _{r} \)
Code (Rust)
impl Solution {
pub fn generate(num_rows: i32) -> Vec<Vec<i32>> {
let mut result : Vec<Vec<i32>> = Vec::new();
for n in 0..num_rows {
let mut row : Vec<i32> = Vec::new();
for i in 0..=n {
row.push(
if i == n || i == 0 {
1
}
else{
result[(n - 1) as usize][(i - 1) as usize]
+ result[(n - 1) as usize][i as usize]
}
)
}
result.push(row);
}
return result;
}
}
Complexity
- n is the number of rows
Time complexity:
- \( T(n) = O(n^2) \)
- \(1+2+3...+n+(n+1) = \frac{(n+1)(n+2)}{2}\)
Auxiliary Space:
- \( S(n) = O(n^2) \)
119. Pascal's Triangle II
Description of Problem
Given an integer rowIndex, return the rowIndexth (0-indexed) row of the Pascal's triangle.
In Pascal's triangle, each number is the sum of the two numbers directly above it as shown:
Example 1:
Input: rowIndex = 3
Output: [1,3,3,1]
Example 2:
Input: rowIndex = 0
Output: [1]
Example 3:
Input: rowIndex = 1
Output: [1,1]
Constraints:
0 <= rowIndex <= 33
Follow up: Could you optimize your algorithm to use only O(rowIndex) extra space?
Solution
Code (Rust)
impl Solution {
pub fn get_row(row_index: i32) -> Vec<i32> {
let row_index = row_index as usize;
let mut curr = vec![0; row_index + 1];
for n in 0..=row_index {
// Do not remove `.rev()` due to data dependency.
for r in (0..=n).rev() {
curr[r] = if r == 0 || r == n { 1 } else { curr[r-1] + curr[r]};
}
}
return curr;
}
}
Complexity
Time Complexity
- \( T(row\_index) = \Theta(row\_index)\)
- 1+2+3+4+...+
row_index
- 1+2+3+4+...+
Auxiliary Space
- \(S(row\_index) = O(row\_index)\)
125. Valid Palindrome
Description of the Problem
A phrase is a palindrome if, after converting all uppercase letters into lowercase letters and removing all non-alphanumeric characters, it reads the same forward and backward. Alphanumeric characters include letters and numbers.
Given a string s, return true if it is a palindrome, or false otherwise.
Example 1:
Input: s = "A man, a plan, a canal: Panama"
Output: true
Explanation: "amanaplanacanalpanama" is a palindrome.
Example 2:
Input: s = "race a car"
Output: false
Explanation: "raceacar" is not a palindrome.
Example 3:
Input: s = " "
Output: true
Explanation: s is an empty string "" after removing non-alphanumeric characters.
Since an empty string reads the same forward and backward, it is a palindrome.
Constraints:
1 <= s.length <= 2 * 10^5sconsists only of printable ASCII characters.
Solution
Code (Rust)
impl Solution {
pub fn is_palindrome(s: String) -> bool {
let mut s = s;
s = s.to_lowercase();
let s = s.chars().collect::<Vec<char>>();
let mut i = 0;
let mut j = s.len() - 1;
while i < j {
let (a,b) = (s[i], s[j]);
match ( a.is_alphanumeric(), b.is_alphanumeric() ) {
(true, true) => if a != b {return false} else {i+=1; j-=1;},
(true, false) => j-=1,
(false, true) => i+=1,
(false, false) => {i+1; j-=1;}
}
}
return true;
}
}
Complexity
- n is the length of string
Time complexity:
- \( T(n) = O(n) \)
Auxiliary Space:
- \( S(n) = O(n) \ / \ O(1) \)
- Depends on implementation.
136. Single Number
Description
Given a non-empty array of integers nums, every element appears twice except for one. Find that single one.
You must implement a solution with a linear runtime complexity and use only constant extra space.
Example 1:
Input: nums = [2,2,1]
Output: 1
Example 2:
Input: nums = [4,1,2,1,2]
Output: 4
Example 3:
Input: nums = [1]
Output: 1
Constraints:
1 <= nums.length <= 3 * 10^4-3 * 10^4 <= nums[i] <= 3 * 10^4- Each element in the array appears twice except for one element which appears only once.
Solution
Tags: Bit Manipulation
Explanation
For any number n, n xor n === 0 since 1 xor 1 === 0 and 0 xor 0 === 0.
Code (Rust)
impl Solution {
pub fn single_number(nums: Vec<i32>) -> i32 {
nums.into_iter().fold(0, |acc, num| acc ^ num)
}
}
Complexity
- n is length of
nums
Time Complexity
- \(T(n) = \Theta(n)\)
Space Complexity
- \(S(n) = O(1)\)
141. Linked List Cycle
Description of the Problem
Given head, the head of a linked list, determine if the linked list has a cycle in it.
There is a cycle in a linked list if there is some node in the list that can be reached again by continuously following the next pointer. Internally, pos is used to denote the index of the node that tail's next pointer is connected to. Note that pos is not passed as a parameter.
Return true if there is a cycle in the linked list. Otherwise, return false.
Example 1:
Input: head = [3,2,0,-4], pos = 1
Output: true
Explanation: There is a cycle in the linked list, where the tail connects to the 1st node (0-indexed).
Example 2:
Input: head = [1,2], pos = 0
Output: true
Explanation: There is a cycle in the linked list, where the tail connects to the 0th node.
Example 3:
Input: head = [1], pos = -1
Output: false
Explanation: There is no cycle in the linked list.
Constraints:
- The number of the nodes in the list is in the range
[0, 10^4]. -10^5 <= Node.val <= 10^5posis-1or a valid index in the linked-list.
Follow up: Can you solve it using O(1) (i.e. constant) memory?
Solution
Tags: LinkedList Fast-slow Pointers
Explanation
For any linkedlist (with or without a cycle), we can express as the following graph where \( k \ge 0\), \( \lambda \ge 0 \) and those \(\lambda\) nodes form a cycle.
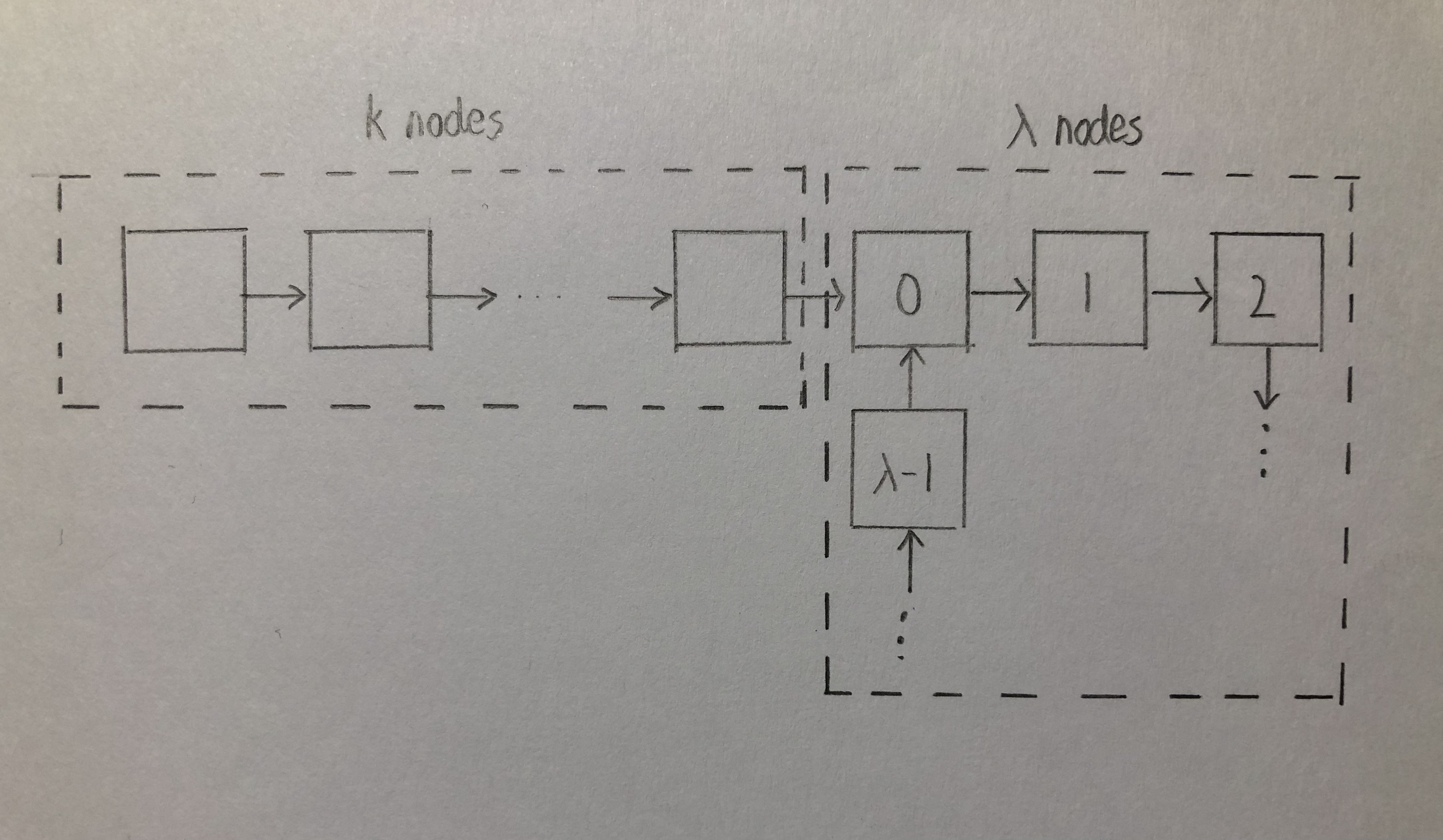
Let \(n\) is the number of nodes in the linkedlist (i.e. \(n = k + \lambda \)).
We would like to show that if the linkedlist has a cycle, two pointers will meet in somewhere in those \(\lambda\) nodes (Proposition 1), and the time complxity is bounded by \(n\) (Proposition 2).
Also, let \(s^{(t)}\) be position of slow pointer after t iterations; let \(f^{(t)}\) be position of fast pointer after t iterations.
Proposition 1 - If the linkedlist has a cycle, two pointers will meet in somewhere the cycle:
Proof:
Consider the positions of two pointer in the cycle after k iterations: \(s^{(k)} = 0 \) and \(f^{(k)} = (k \mod \lambda) \)
They meet in somewhere in the cycle if and only if \(\exists t \gt 0 (s^{(k+t)} \equiv f^{(k+t)} \mod \lambda) \), evaluate the equation: \[ \begin{align} s^{(k+t)} & \equiv f^{(k+t)} & \mod \lambda \\ t & \equiv k+2t & \mod \lambda \\ 0 & \equiv k+t & \mod \lambda \\ t & \equiv -k & \mod \lambda \\ \end{align} \]
\( (t \equiv -k \mod \lambda) \) implies that t has a solution where \(0 \lt t \lt \lambda \).
Thus, Two pointer meet in some node in a cycle if the linkedlist has the cycle.
Proposition 2 - time complxity is bounded by \(n\):
Proof:
Consider a linkedlist without a cycle, the algorithm terminates in \(O(n)\).
Consider a linkedlist with a cycle, the algorithm runs less than \( k + \lambda = n \) iterations
Code (Java)
/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public boolean hasCycle(ListNode head) {
if(head == null){
return false;
}
ListNode slow = head;
ListNode fast = head;
while(slow.next != null && fast.next != null && fast.next.next != null){
slow = slow.next;
fast = fast.next.next;
if(slow == fast){
return true;
}
}
return false;
}
}
Complexity
- n is number of nodes in a linkedlist
Time complexity:
- \(T(n) = O(n)\)
Auxiliary Space:
- \(S(n) = O(1)\)
144. Binary Tree Preorder Traversal
Description of Problem
Given the root of a binary tree, return the preorder traversal of its nodes' values.
Example 1:
Input: root = [1,null,2,3]
Output: [1,2,3]
Example 2:
Input: root = []
Output: []
Example 3:
Input: root = [1]
Output: [1]
Constraints:
- The number of nodes in the tree is in the range
[0, 100]. -100 <= Node.val <= 100
Follow up: Recursive solution is trivial, could you do it iteratively?
Solution (Failed answer the follow-up)
Code(C++)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
private:
void helper(TreeNode * root, vector<int> &vec){
if(root == nullptr)
return;
vec.push_back(root->val);
helper(root->left, vec);
helper(root->right, vec);
}
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int> vec;
helper(root, vec);
return vec;
}
};
145. Binary Tree Postorder Traversal
Description of Problem
Given the root of a binary tree, return the postorder traversal of its nodes' values.
Example 1:
Input: root = [1,null,2,3]
Output: [3,2,1]
Example 2:
Input: root = []
Output: []
Example 3:
Input: root = [1]
Output: [1]
Constraints:
- The number of the nodes in the tree is in the range
[0, 100]. -100 <= Node.val <= 100
Follow up: Recursive solution is trivial, could you do it iteratively?
Solution (Failed to answer the follow-up)
Code (C++)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
private:
void helper(TreeNode * root, vector<int> &vec){
if(root == nullptr)
return;
helper(root->left, vec);
helper(root->right, vec);
vec.push_back(root->val);
}
public:
vector<int> postorderTraversal(TreeNode* root) {
vector<int> vec;
helper(root, vec);
return vec;
}
};
175. Combine Two Tables
Description of Problem
Table: Person
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| personId | int |
| lastName | varchar |
| firstName | varchar |
+-------------+---------+
personId is the primary key (column with unique values) for this table.
This table contains information about the ID of some persons and their first and last names.
Table: Address
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| addressId | int |
| personId | int |
| city | varchar |
| state | varchar |
+-------------+---------+
addressId is the primary key (column with unique values) for this table.
Each row of this table contains information about the city and state of one person with ID = PersonId.
Write a solution to report the first name, last name, city, and state of each person in the Person table. If the address of a personId is not present in the Address table, report null instead.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Person table:
+----------+----------+-----------+
| personId | lastName | firstName |
+----------+----------+-----------+
| 1 | Wang | Allen |
| 2 | Alice | Bob |
+----------+----------+-----------+
Address table:
+-----------+----------+---------------+------------+
| addressId | personId | city | state |
+-----------+----------+---------------+------------+
| 1 | 2 | New York City | New York |
| 2 | 3 | Leetcode | California |
+-----------+----------+---------------+------------+
Output:
+-----------+----------+---------------+----------+
| firstName | lastName | city | state |
+-----------+----------+---------------+----------+
| Allen | Wang | Null | Null |
| Bob | Alice | New York City | New York |
+-----------+----------+---------------+----------+
Explanation:
There is no address in the address table for the personId = 1 so we return null in their city and state.
addressId = 1 contains information about the address of personId = 2.
Solution
Tags: SQL
Code (MySQL)
# Write your MySQL query statement below
SELECT p.firstName, p.lastName, a.city, a.state
FROM Person p
LEFT JOIN Address a
ON p.personId = a.personId
;
181. Employees Earning More Than Their Managers
Description
Table: Employee
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| name | varchar |
| salary | int |
| managerId | int |
+-------------+---------+
id is the primary key (column with unique values) for this table.
Each row of this table indicates the ID of an employee, their name, salary, and the ID of their manager.
Write a solution to find the employees who earn more than their managers.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Employee table:
+----+-------+--------+-----------+
| id | name | salary | managerId |
+----+-------+--------+-----------+
| 1 | Joe | 70000 | 3 |
| 2 | Henry | 80000 | 4 |
| 3 | Sam | 60000 | Null |
| 4 | Max | 90000 | Null |
+----+-------+--------+-----------+
Output:
+----------+
| Employee |
+----------+
| Joe |
+----------+
Explanation: Joe is the only employee who earns more than his manager.
Solution
Tags: SQL
Code (MySQL)
# Write your MySQL query statement below
SELECT e1.name as Employee
FROM Employee e1
INNER JOIN Employee e2
ON e1.managerId = e2.id
WHERE e1.salary > e2.salary
;
182. Duplicate Emails
Description of Problem
Table: Person
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| email | varchar |
+-------------+---------+
id is the primary key (column with unique values) for this table.
Each row of this table contains an email. The emails will not contain uppercase letters.
Write a solution to report all the duplicate emails. Note that it's guaranteed that the email field is not NULL.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Person table:
+----+---------+
| id | email |
+----+---------+
| 1 | a@b.com |
| 2 | c@d.com |
| 3 | a@b.com |
+----+---------+
Output:
+---------+
| Email |
+---------+
| a@b.com |
+---------+
Explanation: a@b.com is repeated two times.
Solution
Tags: SQL
Code (MySQL)
# Write your MySQL query statement below
SELECT email
FROM Person
GROUP BY email
HAVING COUNT(email) >= 2
;
183. Customers Who Never Order
Description
Table: Customers
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| name | varchar |
+-------------+---------+
id is the primary key (column with unique values) for this table.
Each row of this table indicates the ID and name of a customer.
Table: Orders
+-------------+------+
| Column Name | Type |
+-------------+------+
| id | int |
| customerId | int |
+-------------+------+
id is the primary key (column with unique values) for this table.
customerId is a foreign key (reference columns) of the ID from the Customers table.
Each row of this table indicates the ID of an order and the ID of the customer who ordered it.
Write a solution to find all customers who never order anything.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Customers table:
+----+-------+
| id | name |
+----+-------+
| 1 | Joe |
| 2 | Henry |
| 3 | Sam |
| 4 | Max |
+----+-------+
Orders table:
+----+------------+
| id | customerId |
+----+------------+
| 1 | 3 |
| 2 | 1 |
+----+------------+
Output:
+-----------+
| Customers |
+-----------+
| Henry |
| Max |
+-----------+
Solution
Tags: SQL
Code (MySQL)
# Write your MySQL query statement below
SELECT name as Customers
FROM Customers c
WHERE NOT EXISTS (
SELECT 1 FROM Orders o WHERE o.customerId = c.id
)
;
191. Number of 1 Bits
Description of the Problem
Write a function that takes the binary representation of an unsigned integer and returns the number of '1' bits it has (also known as the Hamming weight).
Note:
Note that in some languages, such as Java, there is no unsigned integer type. In this case, the input will be given as a signed integer type. It should not affect your implementation, as the integer's internal binary representation is the same, whether it is signed or unsigned. In Java, the compiler represents the signed integers using 2's complement notation. Therefore, in Example 3, the input represents the signed integer. -3.
Example 1:
Input: n = 00000000000000000000000000001011
Output: 3
Explanation: The input binary string 00000000000000000000000000001011 has a total of three '1' bits.
Example 2:
Input: n = 00000000000000000000000010000000
Output: 1
Explanation: The input binary string 00000000000000000000000010000000 has a total of one '1' bit.
Example 3:
Input: n = 11111111111111111111111111111101
Output: 31
Explanation: The input binary string 11111111111111111111111111111101 has a total of thirty one '1' bits.
Constraints:
- The input must be a binary string of length 32.
Follow up: If this function is called many times, how would you optimize it?
Solution 1
Tags: Bit Manipulation
Code (Rust)
impl Solution {
pub fn hammingWeight (n: u32) -> i32 {
let mut n = n;
let mut count = 0;
while n != 0 {
count += n & 1;
n = n >> 1; // Unsigned Right Shift
}
return count as i32;
}
}
Complexity
- d is the number of digits of the input number
Time Complexity:
- \(T(d) = O(d)\)
Auxiliary Space:
- \(T(d) = O(1)\)
Solution 2 (Answer to the follow-up)
Tags: Precomputation Bit Manipulation
Explanation
Since the function is called many times, we must reduce the executeion time. Space can buy time; we can pre-compute the number of '1' bit in a 4-bit numbers.
Code (Rust)
impl Solution {
pub fn hammingWeight (n: u32) -> i32 {
let precomputed = [
0,1,1,2, // 0000 0001 0010 0011
1,2,2,3, // 0100 0101 0110 0111
1,2,2,3, // 1000 1001 1010 1011
2,3,3,4 // 1100 1101 1110 1111
];
let mut n = n;
let mut count = 0;
while n != 0 {
count += precomputed[(n & 0b1111) as usize];
n = n >> 4; // Unsigned Right Shift
}
return count;
}
}
Complexity
- d is the number of digits of the input number
Time Complexity:
- \(T(d) = \Theta(\lceil d/4 \rceil)\)
Auxiliary Space:
- \(T(d) = O(1)\)
193. Valid Phone Numbers
Description of Problem
Given a text file file.txt that contains a list of phone numbers (one per line), write a one-liner bash script to print all valid phone numbers.
You may assume that a valid phone number must appear in one of the following two formats: (xxx) xxx-xxxx or xxx-xxx-xxxx. (x means a digit)
You may also assume each line in the text file must not contain leading or trailing white spaces.
Example:
Assume that file.txt has the following content:
987-123-4567
123 456 7890
(123) 456-7890
Your script should output the following valid phone numbers:
987-123-4567
(123) 456-7890
Solution
Tags: Shell Script
Explanation
There are only 2 valid formats of phone numbers. Therefore, we can use the union of 2 extended-regular expressions to express all valid phone numbers.
Code (sh)
# Read from the file file.txt and output all valid phone numbers to stdout.
# Read from the file file.txt and output all valid phone numbers to stdout.
grep -E "^[0-9]{3}-[0-9]{3}-[0-9]{4}$|^\([0-9]{3}\) [0-9]{3}-[0-9]{4}$" file.txt
195. Tenth Line
Description of Problem
Given a text file file.txt, print just the 10th line of the file.
Example:
Assume that file.txt has the following content:
Line 1
Line 2
Line 3
Line 4
Line 5
Line 6
Line 7
Line 8
Line 9
Line 10
Your script should output the tenth line, which is:
Line 10
Note:
- If the file contains less than 10 lines, what should you output?
- There's at least three different solutions. Try to explore all possibilities.
Solution
Tags: Shell Script
Explanation
The problem does not need explanation.
Code (sh)
tail -n +10 file.txt | head -n 1
awk 'NR == 10 {print; exit}' file.txt
sed -n '10p' < file.txt
196. Delete Duplicate Emails
Description of Problem
Table: Person
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| email | varchar |
+-------------+---------+
id is the primary key (column with unique values) for this table.
Each row of this table contains an email. The emails will not contain uppercase letters.
Write a solution to delete all duplicate emails, keeping only one unique email with the smallest id.
For SQL users, please note that you are supposed to write a DELETE statement and not a SELECT one.
For Pandas users, please note that you are supposed to modify Person in place.
After running your script, the answer shown is the Person table. The driver will first compile and run your piece of code and then show the Person table. The final order of the Person table does not matter.
The result format is in the following example.
Example 1:
Input:
Person table:
+----+------------------+
| id | email |
+----+------------------+
| 1 | john@example.com |
| 2 | bob@example.com |
| 3 | john@example.com |
+----+------------------+
Output:
+----+------------------+
| id | email |
+----+------------------+
| 1 | john@example.com |
| 2 | bob@example.com |
+----+------------------+
Explanation: john@example.com is repeated two times. We keep the row with the smallest Id = 1.
Solution
Tags: SQL Subquery
Code (MySQL)
-- Write your MySQL query statement below
DELETE FROM Person WHERE id NOT IN (
-- One more SELECT due to Bug of MySQL
SELECT * FROM (
SELECT MIN(p1.id) AS id
FROM Person p1
GROUP BY p1.email
) t
);
Reference
- For more elegant solution, see fabrizio3's Solution
197. Rising Temperature
Description of the Problem
Table: Weather
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| recordDate | date |
| temperature | int |
+---------------+---------+
id is the column with unique values for this table.
This table contains information about the temperature on a certain day.
Write a solution to find all dates' Id with higher temperatures compared to its previous dates (yesterday).
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Weather table:
+----+------------+-------------+
| id | recordDate | temperature |
+----+------------+-------------+
| 1 | 2015-01-01 | 10 |
| 2 | 2015-01-02 | 25 |
| 3 | 2015-01-03 | 20 |
| 4 | 2015-01-04 | 30 |
+----+------------+-------------+
Output:
+----+
| id |
+----+
| 2 |
| 4 |
+----+
Explanation:
In 2015-01-02, the temperature was higher than the previous day (10 -> 25).
In 2015-01-04, the temperature was higher than the previous day (20 -> 30).
Solution
Tags: SQL Joins
Code (MySQL)
-- Write your MySQL query statement below
SELECT w2.id
FROM Weather w1
INNER JOIN Weather w2
ON DATEDIFF(w1.recordDate, w2.recordDate) = -1
WHERE w1.temperature < w2.temperature;
203. Remove Linked List Elements
Description of the Problem
Given the head of a linked list and an integer val, remove all the nodes of the linked list that has Node.val == val, and return the new head.
Example 1:
Input: head = [1,2,6,3,4,5,6], val = 6
Output: [1,2,3,4,5]
Example 2:
Input: head = [], val = 1
Output: []
Example 3:
Input: head = [7,7,7,7], val = 7
Output: []
Constraints:
- The number of nodes in the list is in the range
[0, 104]. 1 <= Node.val <= 500 <= val <= 50
Solution
Tags: LinkedList
Code (C++)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
ListNode * dummyHead = new ListNode();
dummyHead->next = head;
ListNode * curr = dummyHead;
while(curr != nullptr && curr->next != nullptr){
if (curr->next->val == val) {
curr->next = curr->next->next;
}else{
curr = curr->next;
}
}
return dummyHead->next;
}
};
Complexity
- n is length of the linkedlist
Time Complexity:
- \(T(n) = O(n)\)
Auxiliary Space:
- \(S(n) = O(1) \)
206. Reverse Linked Lists
Description of the Problem
Given the head of a singly linked list, reverse the list, and return the reversed list.
Example 1:
Input: head = [1,2,3,4,5]
Output: [5,4,3,2,1]
Example 2:
Input: head = [1,2]
Output: [2,1]
Example 3:
Input: head = []
Output: []
Constraints:
- The number of nodes in the list is the range
[0, 5000]. -5000 <= Node.val <= 5000
Solution
Tags: Rust LinkedList
Explanation
The following (Rust) code can be verified by the loop invariant
Invariant: All nodes before the current node are properly reversed
Proof:
- Initialisation: Before the begin of the loop, No node is before the current node, the invariant is vacuously true
- Maintenance: Suppose the invariant is true before an iteration, having perform re-ordering operations, all nodes before the current node (originally it is next node) is properly reversed
- Termination: After all iterations, all nodes in the LinkedList are reversed properly
Code (Rust)
// Definition for singly-linked list.
// #[derive(PartialEq, Eq, Clone, Debug)]
// pub struct ListNode {
// pub val: i32,
// pub next: Option<Box<ListNode>>
// }
//
// impl ListNode {
// #[inline]
// fn new(val: i32) -> Self {
// ListNode {
// next: None,
// val
// }
// }
// }
impl Solution {
pub fn reverse_list(head: Option<Box<ListNode>>) -> Option<Box<ListNode>> {
let mut curr = head;
let mut prev = None;
while let Some(mut node) = curr.take() {
curr = node.next; // Transfer the ownership of node.next to curr, node.next becomes None
node.next = prev; // The next node of the current node should point to previous node
prev = Some(node); // Current nodebecomes preivous node for next iteration
}
return prev;
}
}
Code(Java)
public class Solution {
public ListNode reverseList(ListNode head) {
ListNode prev = null;
ListNode curr = head;
while(curr != null){
ListNode temp = curr;
curr = temp.next;
temp.next = prev;
prev= temp;
}
return prev;
}
}
Code(C++)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode * prev = nullptr;
ListNode * curr = head;
ListNode * node;
while( (node = curr) != nullptr ){
curr = node->next;
node->next = prev;
prev = node;
}
return prev;
}
};
Complexity
Time complexity:
- \( T(n) = \mathcal{\Theta}(n) \)
- Traversal of all nodes in LinkedList
Auxiliary Space:
- \( S(n) = O(1) \)
217. Contains Duplicate
Description of the Problem
Given an integer array nums, return true if any value appears at least twice in the array, and return false if every element is distinct.
Example 1:
Input: nums = [1,2,3,1]
Output: true
Example 2:
Input: nums = [1,2,3,4]
Output: false
Example 3:
Input: nums = [1,1,1,3,3,4,3,2,4,2]
Output: true
Constraints:
1 <= nums.length <= 10^510^9 <= nums[i] <= 10^9
Solution
Code (Java)
// import java.util.HashSet;
class Solution {
public boolean containsDuplicate(int[] nums) {
HashSet <Integer> set = new HashSet();
for (int n : nums){
if (!set.add(n))
return true;
}
return false;
}
}
Code(Rust)
use std::collections::HashSet;
impl Solution {
pub fn contains_duplicate(nums: Vec<i32>) -> bool {
let mut set : HashSet<i32> = HashSet::new();
for n in nums {
if !set.insert(n) {
return true;
}
}
return false;
}
}
Complexity
- n is the number of elements in the array
Time complexity:
- \( T(n) = O(n) \)
Auxiliary Space:
- \( S(n) = O(n) \)
- For HashMap
226. Invert Binary Tree
Description of the Problem
Given the root of a binary tree, invert the tree, and return its root.
Example 1:
Input: root = [4,2,7,1,3,6,9]
Output: [4,7,2,9,6,3,1]
Example 2:
Input: root = [2,1,3]
Output: [2,3,1]
Example 3:
Input: root = []
Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 100]. -100 <= Node.val <= 100
Solution
Tags: Rust Binary Tree
Explanation
Recursively invert left and right sub-trees. And swap left and right sub-trees.
Code(C++)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if(root == nullptr)
return nullptr;
TreeNode * tempNode = root->left;
root->left = invertTree(root->right);
root->right = invertTree(tempNode);
return root;
}
};
Code (Rust)
// Definition for a binary tree node.
// #[derive(Debug, PartialEq, Eq)]
// pub struct TreeNode {
// pub val: i32,
// pub left: Option<Rc<RefCell<TreeNode>>>,
// pub right: Option<Rc<RefCell<TreeNode>>>,
// }
//
// impl TreeNode {
// #[inline]
// pub fn new(val: i32) -> Self {
// TreeNode {
// val,
// left: None,
// right: None
// }
// }
// }
use std::rc::Rc;
use std::cell::RefCell;
impl Solution {
pub fn invert_tree(root: Option<Rc<RefCell<TreeNode>>>) -> Option<Rc<RefCell<TreeNode>>> {
return root.map(
|root| {
{
let mut node = root.borrow_mut();
let left = node.left.clone();
let right = node.right.clone();
node.right = Self::invert_tree(left);
node.left = Self::invert_tree(right);
}
return root;
}
);
}
}
Complexity
- \(h\) is the height of the tree
- \(n\) is the number of nodes in the tree
Time complexity:
- \( T(n) = O(n) \)
- Traverse all nodes in the tree.
Auxiliary Space:
- \( S(h) = O(h) \)
- the depth of the tree is the depth of recursive tree.
Reference
231. Power of Two
Description of Problem
Given an integer n, return true if it is a power of two. Otherwise, return false.
An integer n is a power of two, if there exists an integer x such that n == 2^x.
Example 1:
Input: n = 1
Output: true
Explanation: 20 = 1
Example 2:
Input: n = 16
Output: true
Explanation: 24 = 16
Example 3:
Input: n = 3
Output: false
Constraints:
-2^31 <= n <= 2^31 - 1
Follow up: Could you solve it without loops/recursion?
Solution 1 - Bitwise operations
Explanation
Consider binary number representation, each position is either 0 or 1 and it represents \(2^i\).
For any power of two, the binary representation should be \(1000......000000_2\).
Code (Java)
class Solution {
public boolean isPowerOfTwo(int n) {
if ( n <= 0 ){
return false;
}
while((n & 1) == 0){
n = n >> 1;
}
return n == 1 ;
}
}
Complexity
- n is the input number
Time complexity:
- \( T(n) = O(\log_2(n) + 1) \)
- Assume division takes constant time.
Auxiliary Space:
- \( S(n) = O(1) \)
Solution 2 - Meet the requirement of the follow-up
Explanation
The maximum power of two in i32 integer is \( 2^{30}=1073741824 \). This number is divsible by any power of two.
Code (Java)
class Solution {
public boolean isPowerOfTwo(int n) {
if (n <= 0) {
return false;
}else{
return (1073741824 % n) == 0;
}
}
}
Complexity
- n is the input number
Time complexity:
- \( T(n) = O(1) \)
- Assume division takes constant time.
Auxiliary Space:
- \( S(n) = O(1) \)
234. Palindrome Linked List
Description of Problem
Given the head of a singly linked list, return true if it is a palindrome or false otherwise.
Example 1:
Input: head = [1,2,2,1]
Output: true
Example 2:
Input: head = [1,2]
Output: false
Constraints:
- The number of nodes in the list is in the range
[1, 105]. 0 <= Node.val <= 9
Follow up: Could you do it in O(n) time and O(1) space?
Solution
Tags: LinkedList
Explanation
If you solve [143. Reorder List], it is not difficult to re-use the logic.
Code (C++)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
bool isPalindrome(ListNode* head) {
ListNode* fast = head;
ListNode* slow = head;
// 1. Find the middle node
while(fast->next != nullptr && fast->next->next != nullptr){
slow = slow->next;
fast = fast->next->next;
}
// 2. Cut and Reverse
ListNode* curr = slow->next;
ListNode* prev = nullptr;
slow->next = nullptr; // Cut
// Reverse
while(curr != nullptr){
ListNode* temp = curr;
curr = temp->next;
temp->next = prev;
prev = temp;
}
// 3. Merge
ListNode* list1 = head; ListNode* list2 = prev;
while(list1 != nullptr && list2 != nullptr){
if (list1->val != list2->val){
return false;
}
list1 = list1->next;
list2 = list2->next;
}
return true;
}
};
Complexity
Time complexity:
- \(T(n)=O(n)\)
- There are only nearly constant number of n iterations
Auxiliary Space:
- \(S(n)=O(1)\)
- Use only constant number of variables
242. Valid Anagram
Description of the Problem
Given two strings s and t, return true if t is an anagram of s, and false otherwise.
An Anagram is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
Example 1:
Input: s = "anagram", t = "nagaram"
Output: true
Example 2:
Input: s = "rat", t = "car"
Output: false
Constraints:
1 <= s.length, t.length <= 5 * 10^4sandtconsist of lowercase English letters.
Follow up: What if the inputs contain Unicode characters? How would you adapt your solution to such a case?
Solution
Explanation
The key of the problem is to count the occurences of each charaters of each string and to see whether the counts is equal or not.
Answer to followup question: char in Rust already handles the case of UTF-8. Therefore, the following code meet the requirement of follow-up question.
Code (Rust)
impl Solution {
pub fn is_anagram(s: String, t: String) -> bool {
use std::collections::HashMap;
let mut bucket = HashMap::new();
for c in s.chars() {
if let Some(count) = bucket.get_mut(&c) {
*count += 1;
}else{
bucket.insert(c, 1);
}
}
for c in t.chars() {
if let Some(count) = bucket.get_mut(&c) {
*count -= 1;
if *count == 0 {
bucket.remove(&c);
}
}else{
return false;
}
}
return bucket.len() == 0;
}
}
Code (Rust) - Alternative
impl Solution {
pub fn is_anagram(s: String, t: String) -> bool {
let mut s : Vec<char> = s.chars().collect();
let mut t : Vec<char> = t.chars().collect();
s.sort();
t.sort();
return s==t;
}
}
Complexity
- m is the length of string
s - n is the length of string
t
Time complexity:
- \( T(n) = O(\max(m,n)) \)
Auxiliary Space:
- \( S(n) = O(\max(m,n)) \)
- For HashMap
283. Move Zeroes
Description of Problem
Given an integer array nums, move all 0's to the end of it while maintaining the relative order of the non-zero elements.
Note that you must do this in-place without making a copy of the array.
Example 1:
Input: nums = [0,1,0,3,12]
Output: [1,3,12,0,0]
Example 2:
Input: nums = [0]
Output: [0]
Constraints:
1 <= nums.length <= 10^4-2^31 <= nums[i] <= 2^31 - 1
Follow up: Could you minimize the total number of operations done?
Solution 1
Tags: Two Pointers Turing Machine
Explanation
Code
impl Solution {
pub fn move_zeroes(nums: &mut Vec<i32>) {
let n = nums.len();
let (mut read_head, mut write_head, mut count_zeros) = (0, 0, 0);
while read_head < n {
if nums[read_head] != 0 {
nums[write_head] = nums[read_head];
write_head += 1;
}
read_head+=1;
}
while write_head < n {
nums[write_head] = 0;
write_head += 1;
}
}
}
Complexity
- n is length of
nums
Time Complexity
- \( T(n)= O(n) \)
Auxiliary Space
- \( S(n)= O(1) \)
Solution 2
Tags: Two Pointers
Explanation
The solution is provided by LeetCode official. When nums[read_head] is non-zero, swap it and nums[write_head], the following loop invariant verify the correctness of the above method.
Loop invariant (non-inclusive range):
write_head <= read_headnums[write_head..read_head]are all zerosnums[..write_head]are all non-zeros
Code
impl Solution {
pub fn move_zeroes(nums: &mut Vec<i32>) {
let n = nums.len();
let (mut read_head, mut write_head) = (0, 0);
while read_head < n {
if nums[read_head] != 0 {
let temp = nums[write_head];
nums[write_head] = nums[read_head];
nums[read_head] = temp;
write_head += 1;
}
read_head+=1;
}
}
}
Complexity
- n is length of
nums
Time Complexity
- \( T(n)= O(n) \)
Auxiliary Space
- \( S(n)= O(1) \)
292. Nim Game
Description of the Problem
You are playing the following Nim Game with your friend:
- Initially, there is a heap of stones on the table.
- You and your friend will alternate taking turns, and you go first.
- On each turn, the person whose turn it is will remove 1 to 3 stones from the heap.
- The one who removes the last stone is the winner.
Given n, the number of stones in the heap, return true if you can win the game assuming both you and your friend play optimally, otherwise return false.
Example 1:
Input: n = 4
Output: false
Explanation: These are the possible outcomes:
1. You remove 1 stone. Your friend removes 3 stones, including the last stone. Your friend wins.
2. You remove 2 stones. Your friend removes 2 stones, including the last stone. Your friend wins.
3. You remove 3 stones. Your friend removes the last stone. Your friend wins.
In all outcomes, your friend wins.
Example 2:
Input: n = 1
Output: true
Example 3:
Input: n = 2
Output: true
Constraints:
1 <= n <= 2^31 - 1
Solution
Tags: Game Theory
Explanation
Use back-tracking to consider the situation. Let W denotes winning position, L denotes losing position.
| W | L | W | L | W | ... |
|---|---|---|---|---|---|
| 1, 2, 3 | 4 | 5, 6, 7 | 8 | 9, 10, 11 | ... |
To win the game, the number of stones at the last stage should be 1, 2 or 3. In order to have this condition, the previous number of stones should be 4. According to the above reasoning, we can fill the above table to observe the winning pattern.
By observation, the winning position contains n stones where \(n \ mod \ 4 \ne 0 \).
Code (Java)
class Solution {
public boolean canWinNim(int n) {
return n % 4 != 0;
}
}
338. Counting Bits
Description of Problem
Given an integer n, return an array ans of length n + 1 such that for each i (0 <= i <= n), ans[i] is the number of 1's in the binary representation of i.
Example 1:
Input: n = 2
Output: [0,1,1]
Explanation:
0 --> 0
1 --> 1
2 --> 10
Example 2:
Input: n = 5
Output: [0,1,1,2,1,2]
Explanation:
0 --> 0
1 --> 1
2 --> 10
3 --> 11
4 --> 100
5 --> 101
Constraints:
0 <= n <= 10^5
Follow up:
- It is very easy to come up with a solution with a runtime of O(n log n). Can you do it in linear time O(n) and possibly in a single pass?
- Can you do it without using any built-in function (i.e., like __builtin_popcount in C++)?
Solution (Answer to follow-up)
Tags: Divide and Conquer,Parity,Dynamic Programming,Bit Manipulation
Explanation
Hints:
- Can we re-use the preivous result?
- Consider the parity (odd/even) of the number.
Code (Rust)
impl Solution {
pub fn count_bits(n: i32) -> Vec<i32> {
let mut count = vec![0 ; n as usize + 1];
for (i,x) in (0..=n).enumerate().skip(1) {
count[i] = count[i / 2] + (x % 2);
}
return count;
}
}
Complexity
Time Complexity
- \( T(n) = O(n+1) \)
T(0)shall beO(1).
Auxiliary Space
- \( S(n) = O(1) \)
344. Reverse String
Description of the Problem
Write a function that reverses a string. The input string is given as an array of characters s.
You must do this by modifying the input array in-place with O(1) extra memory.
Example 1:
Input: s = ["h","e","l","l","o"]
Output: ["o","l","l","e","h"]
Example 2:
Input: s = ["H","a","n","n","a","h"]
Output: ["h","a","n","n","a","H"]
Constraints:
- 1 <= s.length <= 10^5
s[i]is a printable ascii character.
Solution
Tags: String
Code(Rust)
impl Solution {
pub fn reverse_string(s: &mut Vec<char>) {
let (mut i, mut j) = (0, s.len() - 1);
while( i < j){
let c = s[i];
s[i] = s[j];
s[j] = c;
i+=1; j-=1;
}
}
}
Code(Java)
class Solution {
public void reverseString(char[] s) {
int i = 0; int j = s.length - 1;
while( i < j){
char c = s[i];
s[i] = s[j];
s[j] = c;
i++; j--;
}
}
}
Complexity
- n is the length of the string
Time complexity:
- \( T(n) = O(n/2) \)
Auxiliary Space:
- \( S(n) = O(1) \)
345. Reverse Vowels of a String
Description of Problem
Given a string s, reverse only all the vowels in the string and return it.
The vowels are 'a', 'e', 'i', 'o', and 'u', and they can appear in both lower and upper cases, more than once.
Example 1:
Input: s = "hello"
Output: "holle"
Example 2:
Input: s = "leetcode"
Output: "leotcede"
Constraints:
1 <= s.length <= 3 * 10^5sconsist of printable ASCII characters.
Solution
Code (Rust)
impl Solution {
pub fn reverse_vowels(s: String) -> String {
let mut s = s;
let mut bytes = unsafe { s.as_bytes_mut() };
let (mut i, mut j) = (0, bytes.len() - 1);
while (i < j){
match (bytes[i], bytes[j]) {
(65|69|73|79|85|97|101|105|111|117, 65|69|73|79|85|97|101|105|111|117) => {
let temp = bytes[i];
bytes[i] = bytes[j];
bytes[j] = temp;
i+=1; j-=1;
},
(65|69|73|79|85|97|101|105|111|117, _) => {
j-=1;
},
(_, 65|69|73|79|85|97|101|105|111|117) => {
i+=1;
},
(_,_) => { i+=1; j-=1; }
}
}
return s;
}
}
Complexity
- n is length of string
Time Complexity
- \(T(n)=O(n)\)
Auxiliary Space
- \(S(n)=O(1)\)
374. Guess Number Higher or Lower
Description of the Problem
We are playing the Guess Game. The game is as follows:
I pick a number from 1 to n. You have to guess which number I picked.
Every time you guess wrong, I will tell you whether the number I picked is higher or lower than your guess.
You call a pre-defined API int guess(int num), which returns three possible results:
-1: Your guess is higher than the number I picked (i.e. num > pick).
1: Your guess is lower than the number I picked (i.e. num < pick).
0: your guess is equal to the number I picked (i.e. num == pick).
Return the number that I picked.
Example 1:
Input: n = 10, pick = 6
Output: 6
Example 2:
Input: n = 1, pick = 1
Output: 1
Example 3:
Input: n = 2, pick = 1
Output: 1
Constraints:
- 1 <= n <= 2^31 - 1
- 1 <= pick <= n
Solution
Code(Rust)
impl Solution {
unsafe fn guessNumber(n: i32) -> i32 {
let mut begin = 1;
let mut i_end = n;
let mut mid;
loop{
mid = begin + (i_end - begin) / 2;
match guess(mid) {
-1 => {i_end = mid - 1},
0 => {break},
1 => {begin = mid + 1},
_ => panic!(),
}
};
return mid;
}
}
Complexity
- m is size of the range
Time complexity:
- \( T(m) = O(\log_2(m)) \)
Auxiliary Space:
- \( S(m) = O(1) \)
392. Is Subsequence
Description of Problem
Given two strings s and t, return true if s is a subsequence of t, or false otherwise.
A subsequence of a string is a new string that is formed from the original string by deleting some (can be none) of the characters without disturbing the relative positions of the remaining characters. (i.e., "ace" is a subsequence of "abcde" while "aec" is not).
Example 1:
Input: s = "abc", t = "ahbgdc"
Output: true
Example 2:
Input: s = "axc", t = "ahbgdc"
Output: false
Constraints:
0 <= s.length <= 1000 <= t.length <= 104sandtconsist only of lowercase English letters.
Follow up: Suppose there are lots of incoming s, say s1, s2, ..., sk where k >= 10^9, and you want to check one by one to see if t has its subsequence. In this scenario, how would you change your code?
Solution 1
Tags: Two Pointers
Explanation
Use two distinct pointers to scan oven string s and t. When they have the same character, move both pointers. Otherwise, move t's pointer only.
If the scanning of s is not completed, then s is not the subsequence of t.
Code (Rust)
impl Solution {
pub fn is_subsequence(s: String, t: String) -> bool {
let (s,t) = (s.as_bytes(), t.as_bytes() );
let (mut i, mut j) = (0,0);
while i < s.len() && j < t.len(){
if s[i] == t[j]{
i+=1;
}
j+=1;
}
return i == s.len();
}
}
Complexity
- m is length of
t - n is length of
s
Time Complexity
- \( T(n) = O(\min(m,n)) \)
Auxiliary Space
- \( S(n) = O(1) \)
Solution 2 - Follow-up
Tags: HashSet/HashMap
Explanation
Intutively, find the list of indices \( I \) such that \( s = t[i_0] + t[i_1] + ... + t[i_{n-1}]\)
Example
s = "abc"
t = "axxxxbbxxxbbbxxxxcc"
s = t[0] + t[5] + t[17]
= t[0] + t[6] + t[17]
= ...
= t[0] + [12] + t[18]
Code (Rust)
impl Solution {
pub fn is_subsequence(s: String, t: String) -> bool {
use std::collections::HashMap;
let mut map : HashMap<char, Vec<usize>>= HashMap::new();
// Build (character, Vec<index>) map
for (i,ch) in t.chars().enumerate(){
map.entry(ch).and_modify(|v| v.push(i)).or_insert(vec![i]);
}
let mut curr_idx = None;
for (i, ch) in s.chars().enumerate() {
// characters `ch` is in `t`
if let Some(v) = map.get(&ch) {
// Extract idx from `curr_idx` if exists
if let Some(idx) = curr_idx {
// Find the minimum index in `t` which is greater then `idx`
let next_idx = v.iter().filter( |&x| idx < x ).min();
// No character `ch` is found in `t` after `t[idx]`
if next_idx.is_none(){
return false
}
// Update `curr_idx`
else{
curr_idx = next_idx;
}
}
// the `curr_idx` is None. i.e. This is the first character we read
else{
curr_idx = Some(&v[0]);
}
}
// No such characters in `t`
else{
return false;
}
}
return true;
}
}
Complexity
- m is length of
t - k is the number of incoming requests
- n is maximum length of strings amongst
si
Time Complexity
- \( T(n) = O( m + n \cdot k ) \)
Auxiliary Space
- \( S(n) = O(m) \)
- The HashMap equivalently stores entries in HashMap.
511. Game Play Analysis I
Description of Problem
Table: Activity
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| player_id | int |
| device_id | int |
| event_date | date |
| games_played | int |
+--------------+---------+
(player_id, event_date) is the primary key (combination of columns with unique values) of this table.
This table shows the activity of players of some games.
Each row is a record of a player who logged in and played a number of games (possibly 0) before logging out on someday using some device.
Write a solution to find the first login date for each player.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Activity table:
+-----------+-----------+------------+--------------+
| player_id | device_id | event_date | games_played |
+-----------+-----------+------------+--------------+
| 1 | 2 | 2016-03-01 | 5 |
| 1 | 2 | 2016-05-02 | 6 |
| 2 | 3 | 2017-06-25 | 1 |
| 3 | 1 | 2016-03-02 | 0 |
| 3 | 4 | 2018-07-03 | 5 |
+-----------+-----------+------------+--------------+
Output:
+-----------+-------------+
| player_id | first_login |
+-----------+-------------+
| 1 | 2016-03-01 |
| 2 | 2017-06-25 |
| 3 | 2016-03-02 |
+-----------+-------------+
Solution
Tags: SQL
Code (MySQL)
SELECT player_id, MIN(event_date) AS first_login
FROM Activity
GROUP BY player_id;
577. Employee Bonus
Description of the Problem
Table: Employee
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| empId | int |
| name | varchar |
| supervisor | int |
| salary | int |
+-------------+---------+
empId is the column with unique values for this table.
Each row of this table indicates the name and the ID of an employee in addition to their salary and the id of their manager.
Table: Bonus
+-------------+------+
| Column Name | Type |
+-------------+------+
| empId | int |
| bonus | int |
+-------------+------+
empId is the column of unique values for this table.
empId is a foreign key (reference column) to empId from the Employee table.
Each row of this table contains the id of an employee and their respective bonus.
Write a solution to report the name and bonus amount of each employee with a bonus less than 1000.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Employee table:
+-------+--------+------------+--------+
| empId | name | supervisor | salary |
+-------+--------+------------+--------+
| 3 | Brad | null | 4000 |
| 1 | John | 3 | 1000 |
| 2 | Dan | 3 | 2000 |
| 4 | Thomas | 3 | 4000 |
+-------+--------+------------+--------+
Bonus table:
+-------+-------+
| empId | bonus |
+-------+-------+
| 2 | 500 |
| 4 | 2000 |
+-------+-------+
Output:
+------+-------+
| name | bonus |
+------+-------+
| Brad | null |
| John | null |
| Dan | 500 |
+------+-------+
Solution
Tags: SQL
Code (MySQL)
-- Write your MySQL query statement below
SELECT e.name, b.bonus
FROM Employee e
LEFT JOIN Bonus b ON e.empId = b.empId
WHERE b.bonus IS NULL OR b.bonus < 1000
584. Find Customer Referee
Description of the Problem
Table: Customer
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| name | varchar |
| referee_id | int |
+-------------+---------+
In SQL, id is the primary key column for this table.
Each row of this table indicates the id of a customer, their name, and the id of the customer who referred them.
Find the names of the customer that are not referred by the customer with id = 2.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Customer table:
+----+------+------------+
| id | name | referee_id |
+----+------+------------+
| 1 | Will | null |
| 2 | Jane | null |
| 3 | Alex | 2 |
| 4 | Bill | null |
| 5 | Zack | 1 |
| 6 | Mark | 2 |
+----+------+------------+
Output:
+------+
| name |
+------+
| Will |
| Jane |
| Bill |
| Zack |
+------+
Solution
Tags: SQL
Code (MySQL)
-- Write your MySQL query statement below
SELECT name
FROM Customer
WHERE referee_id IS NULL OR referee_id != 2;
586. Customer Placing the Largest Number of Orders
Description of Problem
Table: Orders
+-----------------+----------+
| Column Name | Type |
+-----------------+----------+
| order_number | int |
| customer_number | int |
+-----------------+----------+
order_number is the primary key (column with unique values) for this table.
This table contains information about the order ID and the customer ID.
Write a solution to find the customer_number for the customer who has placed the largest number of orders.
The test cases are generated so that exactly one customer will have placed more orders than any other customer.
The result format is in the following example.
Example 1:
Input:
Orders table:
+--------------+-----------------+
| order_number | customer_number |
+--------------+-----------------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 3 |
+--------------+-----------------+
Output:
+-----------------+
| customer_number |
+-----------------+
| 3 |
+-----------------+
Explanation:
The customer with number 3 has two orders, which is greater than either customer 1 or 2 because each of them only has one order.
So the result is customer_number 3.
Follow up: What if more than one customer has the largest number of orders, can you find all the customer_number in this case?
Solution
Tags: SQL
Code (MySQL)
SELECT customer_number
FROM Orders
GROUP BY customer_number
ORDER BY COUNT(order_number) DESC
LIMIT 1;
Code (MySQL) - For the follow-up
-- Answer the follow-up question
SELECT customer_number
FROM Orders
GROUP BY customer_number
HAVING COUNT(order_number) = (
SELECT COUNT(order_number) AS count
FROM Orders
GROUP BY customer_number
ORDER BY count DESC
LIMIT 1
)
595. Big Countries
Description of the Problem
Table: World
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| name | varchar |
| continent | varchar |
| area | int |
| population | int |
| gdp | bigint |
+-------------+---------+
name is the primary key (column with unique values) for this table.
Each row of this table gives information about the name of a country, the continent to which it belongs, its area, the population, and its GDP value.
A country is big if:
- it has an area of at least three million (i.e.,
3000000 km2), or - it has a population of at least twenty-five million (i.e.,
25000000).
Write a solution to find the name, population, and area of the big countries.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
World table:
+-------------+-----------+---------+------------+--------------+
| name | continent | area | population | gdp |
+-------------+-----------+---------+------------+--------------+
| Afghanistan | Asia | 652230 | 25500100 | 20343000000 |
| Albania | Europe | 28748 | 2831741 | 12960000000 |
| Algeria | Africa | 2381741 | 37100000 | 188681000000 |
| Andorra | Europe | 468 | 78115 | 3712000000 |
| Angola | Africa | 1246700 | 20609294 | 100990000000 |
+-------------+-----------+---------+------------+--------------+
Output:
+-------------+------------+---------+
| name | population | area |
+-------------+------------+---------+
| Afghanistan | 25500100 | 652230 |
| Algeria | 37100000 | 2381741 |
+-------------+------------+---------+
Solution
Tags: SQL
Code (MySQL)
-- Write your MySQL query statement below
SELECT name, population, area
FROM World
WHERE population >= 25000000 OR area >= 3000000;
596. Classes More Than 5 Students
Description of the Problem
Table: Courses
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| student | varchar |
| class | varchar |
+-------------+---------+
(student, class) is the primary key (combination of columns with unique values) for this table.
Each row of this table indicates the name of a student and the class in which they are enrolled.
Write a solution to find all the classes that have at least five students.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Courses table:
+---------+----------+
| student | class |
+---------+----------+
| A | Math |
| B | English |
| C | Math |
| D | Biology |
| E | Math |
| F | Computer |
| G | Math |
| H | Math |
| I | Math |
+---------+----------+
Output:
+---------+
| class |
+---------+
| Math |
+---------+
Explanation:
- Math has 6 students, so we include it.
- English has 1 student, so we do not include it.
- Biology has 1 student, so we do not include it.
- Computer has 1 student, so we do not include it.
Solution
Tags: SQL
Code (MySQL)
-- Write your MySQL query statement below
SELECT class
FROM Courses
GROUP BY class
HAVING COUNT(Student) >= 5;
607. Sales Person
Description of Problem
Table: SalesPerson
+-----------------+---------+
| Column Name | Type |
+-----------------+---------+
| sales_id | int |
| name | varchar |
| salary | int |
| commission_rate | int |
| hire_date | date |
+-----------------+---------+
sales_id is the primary key (column with unique values) for this table.
Each row of this table indicates the name and the ID of a salesperson alongside their salary, commission rate, and hire date.
Table: Company
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| com_id | int |
| name | varchar |
| city | varchar |
+-------------+---------+
com_id is the primary key (column with unique values) for this table.
Each row of this table indicates the name and the ID of a company and the city in which the company is located.
Table: Orders
+-------------+------+
| Column Name | Type |
+-------------+------+
| order_id | int |
| order_date | date |
| com_id | int |
| sales_id | int |
| amount | int |
+-------------+------+
order_id is the primary key (column with unique values) for this table.
com_id is a foreign key (reference column) to com_id from the Company table.
sales_id is a foreign key (reference column) to sales_id from the SalesPerson table.
Each row of this table contains information about one order. This includes the ID of the company, the ID of the salesperson, the date of the order, and the amount paid.
Write a solution to find the names of all the salespersons who did not have any orders related to the company with the name "RED".
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
SalesPerson table:
+----------+------+--------+-----------------+------------+
| sales_id | name | salary | commission_rate | hire_date |
+----------+------+--------+-----------------+------------+
| 1 | John | 100000 | 6 | 4/1/2006 |
| 2 | Amy | 12000 | 5 | 5/1/2010 |
| 3 | Mark | 65000 | 12 | 12/25/2008 |
| 4 | Pam | 25000 | 25 | 1/1/2005 |
| 5 | Alex | 5000 | 10 | 2/3/2007 |
+----------+------+--------+-----------------+------------+
Company table:
+--------+--------+----------+
| com_id | name | city |
+--------+--------+----------+
| 1 | RED | Boston |
| 2 | ORANGE | New York |
| 3 | YELLOW | Boston |
| 4 | GREEN | Austin |
+--------+--------+----------+
Orders table:
+----------+------------+--------+----------+--------+
| order_id | order_date | com_id | sales_id | amount |
+----------+------------+--------+----------+--------+
| 1 | 1/1/2014 | 3 | 4 | 10000 |
| 2 | 2/1/2014 | 4 | 5 | 5000 |
| 3 | 3/1/2014 | 1 | 1 | 50000 |
| 4 | 4/1/2014 | 1 | 4 | 25000 |
+----------+------------+--------+----------+--------+
Output:
+------+
| name |
+------+
| Amy |
| Mark |
| Alex |
+------+
Explanation:
According to orders 3 and 4 in the Orders table, it is easy to tell that only salesperson John and Pam have sales to company RED, so we report all the other names in the table salesperson.
Solution
Tags: SQL Subquery
Code (MySQL)
SELECT s.name
FROM SalesPerson s
WHERE NOT EXISTS (
SELECT 'X'
FROM Orders o
WHERE o.com_id = (SELECT c.com_id FROM Company c WHERE c.name = 'RED')
AND o.sales_id = s.sales_id
);
610. Triangle Judgement
Description of the Problem
Table: Triangle
+-------------+------+
| Column Name | Type |
+-------------+------+
| x | int |
| y | int |
| z | int |
+-------------+------+
In SQL, (x, y, z) is the primary key column for this table.
Each row of this table contains the lengths of three line segments.
Report for every three line segments whether they can form a triangle.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Triangle table:
+----+----+----+
| x | y | z |
+----+----+----+
| 13 | 15 | 30 |
| 10 | 20 | 15 |
+----+----+----+
Output:
+----+----+----+----------+
| x | y | z | triangle |
+----+----+----+----------+
| 13 | 15 | 30 | No |
| 10 | 20 | 15 | Yes |
+----+----+----+----------+
Solution
Tags: SQL
Code (MySQL)
-- Write your MySQL query statement below
SELECT
*,
IF(x + y > z AND y + z > x AND z + x > y, 'Yes', 'No') AS triangle
FROM Triangle;
619. Biggest Single Number
Description of the Problem
Table: MyNumbers
+-------------+------+
| Column Name | Type |
+-------------+------+
| num | int |
+-------------+------+
This table may contain duplicates (In other words, there is no primary key for this table in SQL).
Each row of this table contains an integer.
A single number is a number that appeared only once in the MyNumbers table.
Find the largest single number. If there is no single number, report null.
The result format is in the following example.
Example 1:
Input:
MyNumbers table:
+-----+
| num |
+-----+
| 8 |
| 8 |
| 3 |
| 3 |
| 1 |
| 4 |
| 5 |
| 6 |
+-----+
Output:
+-----+
| num |
+-----+
| 6 |
+-----+
Explanation: The single numbers are 1, 4, 5, and 6.
Since 6 is the largest single number, we return it.
Example 2:
Input:
MyNumbers table:
+-----+
| num |
+-----+
| 8 |
| 8 |
| 7 |
| 7 |
| 3 |
| 3 |
| 3 |
+-----+
Output:
+------+
| num |
+------+
| null |
+------+
Explanation: There are no single numbers in the input table so we return null.
Solution
Tags: SQL Group
Code (MySQL)
-- Write your MySQL query statement below
WITH T AS (
SELECT num
FROM MyNumbers
GROUP BY num
HAVING COUNT(1) = 1
)
SELECT MAX(num) AS num FROM T;
620. Not Boring Movies
Description of the Problem
Table: Cinema
+----------------+----------+
| Column Name | Type |
+----------------+----------+
| id | int |
| movie | varchar |
| description | varchar |
| rating | float |
+----------------+----------+
id is the primary key (column with unique values) for this table.
Each row contains information about the name of a movie, its genre, and its rating.
rating is a 2 decimal places float in the range [0, 10]
Write a solution to report the movies with an odd-numbered ID and a description that is not "boring".
Return the result table ordered by rating in descending order.
The result format is in the following example.
Example 1:
Input:
Cinema table:
+----+------------+-------------+--------+
| id | movie | description | rating |
+----+------------+-------------+--------+
| 1 | War | great 3D | 8.9 |
| 2 | Science | fiction | 8.5 |
| 3 | irish | boring | 6.2 |
| 4 | Ice song | Fantacy | 8.6 |
| 5 | House card | Interesting | 9.1 |
+----+------------+-------------+--------+
Output:
+----+------------+-------------+--------+
| id | movie | description | rating |
+----+------------+-------------+--------+
| 5 | House card | Interesting | 9.1 |
| 1 | War | great 3D | 8.9 |
+----+------------+-------------+--------+
Explanation:
We have three movies with odd-numbered IDs: 1, 3, and 5. The movie with ID = 3 is boring so we do not include it in the answer.
Solution
Tags: SQL
-- Write your MySQL query statement below
SELECT *
FROM Cinema
WHERE id % 2 = 1
AND description != 'boring'
ORDER BY rating DESC;
627. Swap Salary
Description of Problem
Table: Salary
+-------------+----------+
| Column Name | Type |
+-------------+----------+
| id | int |
| name | varchar |
| sex | ENUM |
| salary | int |
+-------------+----------+
id is the primary key (column with unique values) for this table.
The sex column is ENUM (category) value of type ('m', 'f').
The table contains information about an employee.
Write a solution to swap all 'f' and 'm' values (i.e., change all 'f' values to 'm' and vice versa) with a single update statement and no intermediate temporary tables.
Note that you must write a single update statement, do not write any select statement for this problem.
The result format is in the following example.
Example 1:
Input:
Salary table:
+----+------+-----+--------+
| id | name | sex | salary |
+----+------+-----+--------+
| 1 | A | m | 2500 |
| 2 | B | f | 1500 |
| 3 | C | m | 5500 |
| 4 | D | f | 500 |
+----+------+-----+--------+
Output:
+----+------+-----+--------+
| id | name | sex | salary |
+----+------+-----+--------+
| 1 | A | f | 2500 |
| 2 | B | m | 1500 |
| 3 | C | f | 5500 |
| 4 | D | m | 500 |
+----+------+-----+--------+
Explanation:
(1, A) and (3, C) were changed from 'm' to 'f'.
(2, B) and (4, D) were changed from 'f' to 'm'.
Solution
Tags: SQL
Code (MySQL)
UPDATE Salary
SET sex = (
CASE
WHEN sex = 'f' then 'm'
ELSE 'f'
END
);
643. Maximum Average Subarray I
Description of Problem
You are given an integer array nums consisting of n elements, and an integer k.
Find a contiguous subarray whose length is equal to k that has the maximum average value and return this value. Any answer with a calculation error less than 10^-5 will be accepted.
Example 1:
Input: nums = [1,12,-5,-6,50,3], k = 4
Output: 12.75000
Explanation: Maximum average is (12 - 5 - 6 + 50) / 4 = 51 / 4 = 12.75
Example 2:
Input: nums = [5], k = 1
Output: 5.00000
Constraints:
n == nums.length1 <= k <= n <= 10^5-10^4 <= nums[i] <= 10^4
Solution
Tags: Sliding Window
Code (Rust)
impl Solution {
pub fn find_max_average(nums: Vec<i32>, k: i32) -> f64 {
use std::iter::zip;
let (n, k) = (nums.len() as usize, k as usize);
let mut sum = 0;
for i in 0..k {
sum += nums[i];
}
let mut max = sum;
// window range (i..=j)
for (i,j) in zip(1..,k..n) {
sum = sum - nums[i - 1] + nums[j];
max = max.max(sum);
}
return max as f64 / k as f64;
}
}
Complexity
- n is length of
nums
Time Complexity
- \(T(n) = \Theta(n)\)
Auxuiliary
- \(S(n) = O(1)\)
700. Search in a Binary Search Tree
Description of Problem
You are given the root of a binary search tree (BST) and an integer val.
Find the node in the BST that the node's value equals val and return the subtree rooted with that node. If such a node does not exist, return null.
Example 1:
Input: root = [4,2,7,1,3], val = 2
Output: [2,1,3]
Example 2:
Input: root = [4,2,7,1,3], val = 5
Output: []
Constraints:
- The number of nodes in the tree is in the range
[1, 5000]. 1 <= Node.val <= 10^7rootis a binary search tree.1 <= val <= 10^7
Solution
Tags: Rust Tree Binary Search Tree
Code (C++)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
TreeNode* curr = root;
while(curr != nullptr && val != curr->val){
if (val < curr->val) {
curr = curr->left;
}
else if (val > curr->val) {
curr = curr->right;
}
}
return curr;
}
};
Code (Rust)
// Definition for a binary tree node.
// #[derive(Debug, PartialEq, Eq)]
// pub struct TreeNode {
// pub val: i32,
// pub left: Option<Rc<RefCell<TreeNode>>>,
// pub right: Option<Rc<RefCell<TreeNode>>>,
// }
//
// impl TreeNode {
// #[inline]
// pub fn new(val: i32) -> Self {
// TreeNode {
// val,
// left: None,
// right: None
// }
// }
// }
use std::rc::Rc;
use std::cell::RefCell;
impl Solution {
pub fn search_bst(root: Option<Rc<RefCell<TreeNode>>>, val: i32) -> Option<Rc<RefCell<TreeNode>>> {
let mut curr = root;
while let Some(ref node) = curr.clone() {
let node = node.borrow();
if val == node.val {
break;
}else if val < node.val {
curr = node.left.clone();
}else {
curr = node.right.clone();;
}
}
return curr;
}
}
Complexity
- n is the number of element in the tree
Time Complexity
- \(T(n) = \Theta(\log_2 (n)) \)
Auxiliary Space
- \(S(n) = O(\log_2 (n)) \)
709. To Lower Case
Description of the Problem
Given a string s, return the string after replacing every uppercase letter with the same lowercase letter.
Example 1:
Input: s = "Hello"
Output: "hello"
Example 2:
Input: s = "here"
Output: "here"
Example 3:
Input: s = "LOVELY"
Output: "lovely"
Constraints:
1 <= s.length <= 100sconsists of printable ASCII characters.
Solution
Code (C++)
class Solution {
public:
string toLowerCase(string s) {
for(int i = 0; i < s.size(); i++){
char c = s[i];
if ('A' <= c && c <= 'Z'){
s[i] = c - 'A' + 'a';
}
}
return s;
}
};
Complexity
- n is length of string
s
Time Complexity:
- \(T(n) = \Theta(n)\)
Auxiliary Space:
- \(S(n) = O(1)\)
724. Find Pivot Index
Description of Problem
Given an array of integers nums, calculate the pivot index of this array.
The pivot index is the index where the sum of all the numbers strictly to the left of the index is equal to the sum of all the numbers strictly to the index's right.
If the index is on the left edge of the array, then the left sum is 0 because there are no elements to the left. This also applies to the right edge of the array.
Return the leftmost pivot index. If no such index exists, return -1.
Example 1:
Input: nums = [1,7,3,6,5,6]
Output: 3
Explanation:
The pivot index is 3.
Left sum = nums[0] + nums[1] + nums[2] = 1 + 7 + 3 = 11
Right sum = nums[4] + nums[5] = 5 + 6 = 11
Example 2:
Input: nums = [1,2,3]
Output: -1
Explanation:
There is no index that satisfies the conditions in the problem statement.
Example 3:
Input: nums = [2,1,-1]
Output: 0
Explanation:
The pivot index is 0.
Left sum = 0 (no elements to the left of index 0)
Right sum = nums[1] + nums[2] = 1 + -1 = 0
Constraints:
1 <= nums.length <= 10^4-1000 <= nums[i] <= 1000
Note: This question is the same as 1991: https://leetcode.com/problems/find-the-middle-index-in-array/
Solution
Tags: Prefix Sum
Explanation
We need to find the position where prefix_sum equals to suffix_sum.
We can establish the relationship between sum, prefix_sum, suffix_sum and the number at i-th position.
\[ \begin{align} A[i] & = nums[i] \\ \sigma & = \sum_{i=0}^{n-1} A[i] \\ p_k & = \sum_{i \lt k} A[i] \\ s_k & = \sum_{i \gt k} A[i] \\ A[k] & = \sigma - s_k - p_k \\ A[k] & = \sigma - 2p_k & \because \text{when s=p, A[k] is the pivot} \end{align} \]
Since we aim to find the leftmost pivot, we use prefix sum.
Code (Rust)
impl Solution {
pub fn pivot_index(nums: Vec<i32>) -> i32 {
let n = nums.len();
let sum = nums.iter().sum::<i32>();
let mut prefix_sum = 0;
for i in 0..n {
if nums[i] + 2 * prefix_sum == sum {
return i as i32;
}
prefix_sum += nums[i];
}
return -1;
}
}
Complexity
- \(n\) is length of nums.
Time Complexity
- \(T(n)=\Theta(n)\)
Auxiliary Space
- \(S(n)=O(1)\)
746. Min Cost Climbing Stairs
Description of Problem
You are given an integer array cost where cost[i] is the cost of ith step on a staircase. Once you pay the cost, you can either climb one or two steps.
You can either start from the step with index 0, or the step with index 1.
Return the minimum cost to reach the top of the floor.
Example 1:
Input: cost = [10,15,20]
Output: 15
Explanation: You will start at index 1.
- Pay 15 and climb two steps to reach the top.
The total cost is 15.
Example 2:
Input: cost = [1,100,1,1,1,100,1,1,100,1]
Output: 6
Explanation: You will start at index 0.
- Pay 1 and climb two steps to reach index 2.
- Pay 1 and climb two steps to reach index 4.
- Pay 1 and climb two steps to reach index 6.
- Pay 1 and climb one step to reach index 7.
- Pay 1 and climb two steps to reach index 9.
- Pay 1 and climb one step to reach the top.
The total cost is 6.
Constraints:
2 <= cost.length <= 10000 <= cost[i] <= 999
Solution
Code 1 - Dynamic Programming
impl Solution {
pub fn min_cost_climbing_stairs(cost: Vec<i32>) -> i32 {
let n = cost.len();
let mut total_cost = vec![0; n + 1];
for i in 2..=n{
total_cost[i] = (total_cost[i-1] + cost[i-1]).min(
total_cost[i-2] + cost[i-2]
);
}
total_cost[n]
}
}
Code 2 - Space Optimised
impl Solution {
pub fn min_cost_climbing_stairs(cost: Vec<i32>) -> i32 {
let mut first = 0;
let mut second = 0;
let mut total_cost = 0;
let n = cost.len();
for i in 2..=n{
total_cost = (first + cost[i-2]).min(second + cost[i-1]);
first = second;
second = total_cost;
}
return total_cost;
}
}
Complexity
- n is length of
cost
Time Complexity
- \(T(n) = \Theta(n)\)
Auxiliary Space
- \(S(n) = O(1)\)
872. Leaf-Similar Trees
Description of Problem
Consider all the leaves of a binary tree, from left to right order, the values of those leaves form a leaf value sequence.
For example, in the given tree above, the leaf value sequence is (6, 7, 4, 9, 8).
Two binary trees are considered leaf-similar if their leaf value sequence is the same.
Return true if and only if the two given trees with head nodes root1 and root2 are leaf-similar.
Example 1:
Input: root1 = [3,5,1,6,2,9,8,null,null,7,4], root2 = [3,5,1,6,7,4,2,null,null,null,null,null,null,9,8]
Output: true
Example 2:
Input: root1 = [1,2,3], root2 = [1,3,2]
Output: false
Constraints:
- The number of nodes in each tree will be in the range
[1, 200]. - Both of the given trees will have values in the range
[0, 200].
Solution
Tags: Binary Tree DFS
Explanation
Append the node value when the node is leaf.
Code
// Definition for a binary tree node.
// #[derive(Debug, PartialEq, Eq)]
// pub struct TreeNode {
// pub val: i32,
// pub left: Option<Rc<RefCell<TreeNode>>>,
// pub right: Option<Rc<RefCell<TreeNode>>>,
// }
//
// impl TreeNode {
// #[inline]
// pub fn new(val: i32) -> Self {
// TreeNode {
// val,
// left: None,
// right: None
// }
// }
// }
use std::rc::Rc;
use std::cell::RefCell;
impl Solution {
pub fn leaf_similar(root1: Option<Rc<RefCell<TreeNode>>>, root2: Option<Rc<RefCell<TreeNode>>>) -> bool {
let mut v1 = vec![];
let mut v2 = vec![];
Self::dfs(root1, &mut v1);
Self::dfs(root2, &mut v2);
return v1==v2;
}
fn dfs(node: Option<Rc<RefCell<TreeNode>>>, v : &mut Vec<i32> ) {
if let Some(n) = node.clone() {
let n = n.borrow();
let left = n.left.clone();
let right = n.right.clone();
if left.is_none() && right.is_none(){
v.push(n.val);
}else {
Self::dfs(left, v);
Self::dfs(right, v);
}
}
}
}
Complexity
- n is the number of nodes in the tree
- h is the height of the tree
Time complexity:
- \( T(n) = \Theta(n) \)
Auxiliary Space:
- \( S(n) = O(h) \)
876. Middle of the Linked List
Description of the Problem
Given the head of a singly linked list, return the middle node of the linked list.
If there are two middle nodes, return the second middle node.
Example 1:
Input: head = [1,2,3,4,5]
Output: [3,4,5]
Explanation: The middle node of the list is node 3.
Example 2:
Input: head = [1,2,3,4,5,6]
Output: [4,5,6]
Explanation: Since the list has two middle nodes with values 3 and 4, we return the second one.
Constraints:
- The number of nodes in the list is in the range
[1, 100]. 1 <= Node.val <= 100
Solution - Fast and Slow Pointers
Tags: LinkedList Fast-slow Pointer
Explanation
Slow pointer move to right by 1 and fast pointer move to right by 2 if possible.
At the end of loop, slow pointer must point to the middle node or previous node of the middle node
Here we assume the linkedlist use 0-based indexing (i.e. list[0] indicate first element of the list)
At the termination of the loop, there are only two possible case:
- fast pointer point to last element of the linkedlist
- fast pointer point to second last element of the linkedlist;
Suppose the loop ran k times. It implies that fast pointer mvoed to right by 2k and slow pointer moved to right by k.
In case 1, this is because the number of nodes in the linkedlist is odd number. The total number of nodes is 2k + 1. list[k] is the middle node because there are k elements in list[0..k] and in list[k+1..2k+1] elements1.
In case 2, this is becuase the number of nodes in the linkedlist is even number. The total number of nodes is 2k + 2. list[0..k] and list[k+1..2k+2] contains half number of total elements.1 Thus return slow.next;
1 The sub-indexing is exclusive. For example A[i..j] does not include A[j]
Code (Java)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode middleNode(ListNode head) {
ListNode slow = head;
ListNode fast = head;
while(fast.next != null && fast.next.next != null){
slow = slow.next;
fast = fast.next.next;
}
return fast.next == null? slow : slow.next;
}
}
Complexity
Time complexity:
- \( T(n) = O(n/2) \)
- There are only nearly n/2 iterations
Auxiliary Space:
- \( S(n) = O(1) \)
- Use only constant number of variables
Futher Discussion
Tags: Rust
Alternative way to implements LinkedList in Rust and How to move a pointer in Rust
Althougt it is possible to implement LinkedList in Rust by Rc<RefCell<T>>, I do not know why leetcode refuse to use it. I would like to provide another implementation that supports fast and slow pointers approach. The key difficulty is moving pointer.
use std::rc::Rc;
use std::cell::RefCell;
#[derive(Debug, PartialEq)]
struct LinkedNode {
val : i32,
next : Option<Rc<RefCell<LinkedNode>>>,
}
impl LinkedNode {
fn new(val : i32, next: Option<Rc<RefCell<LinkedNode>>>) -> Option<Rc<RefCell<LinkedNode>>>{
Some(
Rc::new(
RefCell::new(
LinkedNode{
val,
next
}
)
)
)
}
}
fn main() {
let node_2 = LinkedNode::new(2, None);
let node_1 = LinkedNode::new(1, node_2.clone() );
let head = LinkedNode::new(0, node_1);
// Move pointer by flat_map
let safe_fast_pointer = head.clone()
.and_then(|n| {let n = n.borrow(); n.next.clone() })
.and_then(|n| {let n = n.borrow(); n.next.clone() });
assert_eq!(safe_fast_pointer, node_2);
}
For another way to use fast and slow pointers without re-implement the LinkedList, see: link from leetcode
897. Increasing Order Search Tree
Description of the Problem
Given the root of a binary search tree, rearrange the tree in in-order so that the leftmost node in the tree is now the root of the tree, and every node has no left child and only one right child.
Example 1:
Input: root = [5,3,6,2,4,null,8,1,null,null,null,7,9]
Output: [1,null,2,null,3,null,4,null,5,null,6,null,7,null,8,null,9]
Example 2:
Input: root = [5,1,7]
Output: [1,null,5,null,7]
Constraints:
- The number of nodes in the given tree will be in the range
[1, 100]. 0 <= Node.val <= 1000
Solution
Code(C++)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* increasingBST(TreeNode* root) {
if (root == nullptr)
return nullptr;
else if (root->left == nullptr){
TreeNode * right = increasingBST(root->right);
TreeNode * mid = new TreeNode(root->val);
mid->right = right;
return mid;
}
else{
TreeNode * left = increasingBST(root->left);
TreeNode * right = increasingBST(root->right);
TreeNode * mid = new TreeNode(root->val);
TreeNode * leftLeaf = left;
while(leftLeaf -> right != nullptr)
leftLeaf = leftLeaf->right;
leftLeaf->right = mid;
mid->right = right;
return left;
}
}
};
Complexity
- \(h\) is the height of the tree
- \(n\) is the number of nodes in the tree
Time complexity:
- \( T(n) = O(n) \)
- Traverse all nodes in the tree.
Auxiliary Space:
- \( S(h) = O(h) \)
- the depth of the tree is the depth of recursive tree.
933. Number of Recent Calls
Description of Problem
You have a RecentCounter class which counts the number of recent requests within a certain time frame.
Implement the RecentCounter class:
RecentCounter()Initializes the counter with zero recent requests.int ping(int t)Adds a new request at timet, wheretrepresents some time in milliseconds, and returns the number of requests that has happened in the past 3000 milliseconds (including the new request). Specifically, return the number of requests that have happened in the inclusive range[t - 3000, t].
It is guaranteed that every call to ping uses a strictly larger value of t than the previous call.
Example 1:
Input
["RecentCounter", "ping", "ping", "ping", "ping"]
[[], [1], [100], [3001], [3002]]
Output
[null, 1, 2, 3, 3]
Explanation
RecentCounter recentCounter = new RecentCounter();
recentCounter.ping(1); // requests = [1], range is [-2999,1], return 1
recentCounter.ping(100); // requests = [1, 100], range is [-2900,100], return 2
recentCounter.ping(3001); // requests = [1, 100, 3001], range is [1,3001], return 3
recentCounter.ping(3002); // requests = [1, 100, 3001, 3002], range is [2,3002], return 3
Constraints:
1 <= t <= 10^9- Each test case will call
pingwith strictly increasing values oft. - At most
10^4calls will be made toping.
Solution
Code (Rust)
use std::collections::VecDeque;
struct RecentCounter {
queue: VecDeque<i32>
}
/**
* `&self` means the method takes an immutable reference.
* If you need a mutable reference, change it to `&mut self` instead.
*/
impl RecentCounter {
fn new() -> Self {
RecentCounter {
queue : VecDeque::new()
}
}
fn ping(&mut self, t: i32) -> i32 {
self.queue.push_back(t);
while (t >= 3000 && *self.queue.front().unwrap() < t - 3000)
|| *self.queue.front().unwrap() > t
{
self.queue.pop_front();
}
return self.queue.len() as i32;
}
}
/**
* Your RecentCounter object will be instantiated and called as such:
* let obj = RecentCounter::new();
* let ret_1: i32 = obj.ping(t);
*/
Complexity
- n is the number of incoming
pingrequests
Time Complexity
- \(T(n) = O(n)\)
- dequeuing at most all incoming elements
Auxiliary Space
- \(S(n) = O(n)\)
1050. Actors and Directors Who Cooperated At Least Three Times
Description of Problem
Table: ActorDirector
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| actor_id | int |
| director_id | int |
| timestamp | int |
+-------------+---------+
timestamp is the primary key (column with unique values) for this table.
Write a solution to find all the pairs (actor_id, director_id) where the actor has cooperated with the director at least three times.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
ActorDirector table:
+-------------+-------------+-------------+
| actor_id | director_id | timestamp |
+-------------+-------------+-------------+
| 1 | 1 | 0 |
| 1 | 1 | 1 |
| 1 | 1 | 2 |
| 1 | 2 | 3 |
| 1 | 2 | 4 |
| 2 | 1 | 5 |
| 2 | 1 | 6 |
+-------------+-------------+-------------+
Output:
+-------------+-------------+
| actor_id | director_id |
+-------------+-------------+
| 1 | 1 |
+-------------+-------------+
Explanation: The only pair is (1, 1) where they cooperated exactly 3 times.
Solution
Tags: SQL
Code (MySQL)
SELECT actor_id, director_id
FROM ActorDirector
GROUP BY actor_id, director_id
HAVING COUNT(*) >= 3;
1068. Product Sales Analysis I
Description of the Problem
Table: Sales
+-------------+-------+
| Column Name | Type |
+-------------+-------+
| sale_id | int |
| product_id | int |
| year | int |
| quantity | int |
| price | int |
+-------------+-------+
(sale_id, year) is the primary key (combination of columns with unique values) of this table.
product_id is a foreign key (reference column) to Product table.
Each row of this table shows a sale on the product product_id in a certain year.
Note that the price is per unit.
Table: Product
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| product_id | int |
| product_name | varchar |
+--------------+---------+
product_id is the primary key (column with unique values) of this table.
Each row of this table indicates the product name of each product.
Write a solution to report the product_name, year, and price for each sale_id in the Sales table.
Return the resulting table in any order.
The result format is in the following example.
Example 1:
Input:
Sales table:
+---------+------------+------+----------+-------+
| sale_id | product_id | year | quantity | price |
+---------+------------+------+----------+-------+
| 1 | 100 | 2008 | 10 | 5000 |
| 2 | 100 | 2009 | 12 | 5000 |
| 7 | 200 | 2011 | 15 | 9000 |
+---------+------------+------+----------+-------+
Product table:
+------------+--------------+
| product_id | product_name |
+------------+--------------+
| 100 | Nokia |
| 200 | Apple |
| 300 | Samsung |
+------------+--------------+
Output:
+--------------+-------+-------+
| product_name | year | price |
+--------------+-------+-------+
| Nokia | 2008 | 5000 |
| Nokia | 2009 | 5000 |
| Apple | 2011 | 9000 |
+--------------+-------+-------+
Explanation:
From sale_id = 1, we can conclude that Nokia was sold for 5000 in the year 2008.
From sale_id = 2, we can conclude that Nokia was sold for 5000 in the year 2009.
From sale_id = 7, we can conclude that Apple was sold for 9000 in the year 2011.
Solution
Tags: SQL
Code (MySQL)
-- Write your MySQL query statement below
SELECT p.product_name, s.year, s.price
FROM Product p
INNER JOIN Sales s
ON p.product_id = s.product_id
;
1071. Greatest Common Divisor of Strings
Description of Problem
For two strings s and t, we say "t divides s" if and only if s = t + ... + t (i.e., t is concatenated with itself one or more times).
Given two strings str1 and str2, return the largest string x such that x divides both str1 and str2.
Example 1:
Input: str1 = "ABCABC", str2 = "ABC"
Output: "ABC"
Example 2:
Input: str1 = "ABABAB", str2 = "ABAB"
Output: "AB"
Example 3:
Input: str1 = "LEET", str2 = "CODE"
Output: ""
Constraints:
1 <= str1.length, str2.length <= 1000str1andstr2consist of English uppercase letters.
Solution 1
Tags:
Explanation
This is the official answer.
By definition, A string s is divisble if there is string t such that s = t + t + t + ... + t.
Consider divisble two strings s1 and s2:
- Assume the common string
texists (i.e.s1 = t^m,s2 = t^n), the greatest common string ist^gcd(m,n). - If they are non-divisble string or there is no common string, then
s1 + s2 != s2 + s1.
Code (Rust)
impl Solution {
pub fn gcd_of_strings(str1: String, str2: String) -> String {
if [&str1[..], &str2[..]].join("") != [&str2[..], &str1[..]].join("") {
return "".to_string();
}
let mut m = str1.len();
let mut n = str2.len();
if m < n {
let temp = m;
m = n;
n = temp;
}
while n > 0 {
let temp = m;
m = n;
n = temp % n;
}
return String::from(&str1[..m]);
}
}
Complexity
Time Complexity
- \( T(n) = O( (m+n) + \log(m \cdot n) ) = O( m+n ) \)
- Creates
str1 + str2andstr2 + str1for comparsion - Use Euclid's algorithm
- Creates
Auxiliary Space
- \(S(n) = O(2(m+n)) = O(m+n)\)
- Creates
str1 + str2andstr2 + str1for comparsion
- Creates
1075. Project Employees I
Description of the Problem
Table: Project
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| project_id | int |
| employee_id | int |
+-------------+---------+
(project_id, employee_id) is the primary key of this table.
employee_id is a foreign key to Employee table.
Each row of this table indicates that the employee with employee_id is working on the project with project_id.
Table: Employee
+------------------+---------+
| Column Name | Type |
+------------------+---------+
| employee_id | int |
| name | varchar |
| experience_years | int |
+------------------+---------+
employee_id is the primary key of this table. It's guaranteed that experience_years is not NULL.
Each row of this table contains information about one employee.
Write an SQL query that reports the average experience years of all the employees for each project, rounded to 2 digits.
Return the result table in any order.
The query result format is in the following example.
Example 1:
Input:
Project table:
+-------------+-------------+
| project_id | employee_id |
+-------------+-------------+
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 2 | 1 |
| 2 | 4 |
+-------------+-------------+
Employee table:
+-------------+--------+------------------+
| employee_id | name | experience_years |
+-------------+--------+------------------+
| 1 | Khaled | 3 |
| 2 | Ali | 2 |
| 3 | John | 1 |
| 4 | Doe | 2 |
+-------------+--------+------------------+
Output:
+-------------+---------------+
| project_id | average_years |
+-------------+---------------+
| 1 | 2.00 |
| 2 | 2.50 |
+-------------+---------------+
Explanation: The average experience years for the first project is (3 + 2 + 1) / 3 = 2.00 and for the second project is (3 + 2) / 2 = 2.50
Solution
Tags: SQL
Code (MySQL)
-- Write your MySQL query statement below
SELECT
p.project_id,
ROUND(AVG(e.experience_years),2) AS average_years
FROM Project p
INNER JOIN Employee e
ON p.employee_id = e.employee_id
GROUP BY p.project_id;
1084. Sales Analysis III
Description of Problem
Table: Product
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| product_id | int |
| product_name | varchar |
| unit_price | int |
+--------------+---------+
product_id is the primary key (column with unique values) of this table.
Each row of this table indicates the name and the price of each product.
Table: Sales
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| seller_id | int |
| product_id | int |
| buyer_id | int |
| sale_date | date |
| quantity | int |
| price | int |
+-------------+---------+
This table can have duplicate rows.
product_id is a foreign key (reference column) to the Product table.
Each row of this table contains some information about one sale.
Write a solution to report the products that were only sold in the first quarter of 2019. That is, between 2019-01-01 and 2019-03-31 inclusive.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Product table:
+------------+--------------+------------+
| product_id | product_name | unit_price |
+------------+--------------+------------+
| 1 | S8 | 1000 |
| 2 | G4 | 800 |
| 3 | iPhone | 1400 |
+------------+--------------+------------+
Sales table:
+-----------+------------+----------+------------+----------+-------+
| seller_id | product_id | buyer_id | sale_date | quantity | price |
+-----------+------------+----------+------------+----------+-------+
| 1 | 1 | 1 | 2019-01-21 | 2 | 2000 |
| 1 | 2 | 2 | 2019-02-17 | 1 | 800 |
| 2 | 2 | 3 | 2019-06-02 | 1 | 800 |
| 3 | 3 | 4 | 2019-05-13 | 2 | 2800 |
+-----------+------------+----------+------------+----------+-------+
Output:
+-------------+--------------+
| product_id | product_name |
+-------------+--------------+
| 1 | S8 |
+-------------+--------------+
Explanation:
The product with id 1 was only sold in the spring of 2019.
The product with id 2 was sold in the spring of 2019 but was also sold after the spring of 2019.
The product with id 3 was sold after spring 2019.
We return only product 1 as it is the product that was only sold in the spring of 2019.
Solution
Tags: SQL
Explanation
Simple Logic.
Code (MySQL)
SELECT p.product_id, p.product_name
FROM Product p
WHERE EXISTS (
SELECT 'X'
FROM Sales first_quarter
WHERE first_quarter.sale_date BETWEEN '2019-01-01' AND '2019-03-31'
AND first_quarter.product_id = p.product_id
) AND NOT EXISTS (
SELECT 'X'
FROM Sales other
WHERE other.sale_date NOT BETWEEN '2019-01-01' AND '2019-03-31'
AND other.product_id = p.product_id
)
1137. N-th Tribonacci Number
Description of the Problem
The Tribonacci sequence Tn is defined as follows:
\(T_0 = 0, T_1 = 1, T_2 = 1, and \ T_{n+3} = T_n + T_{n+1} + T_{n+2} \ for \ n \ge 0\).
Given n, return the value of \(T_n\).
Example 1:
Input: n = 4
Output: 4
Explanation:
T_3 = 0 + 1 + 1 = 2
T_4 = 1 + 1 + 2 = 4
Example 2:
Input: n = 25
Output: 1389537
Constraints:
0 <= n <= 37- The answer is guaranteed to fit within a 32-bit integer, ie.
answer <= 2^31 - 1.
Solution
Code (Rust)
impl Solution {
pub fn tribonacci(n: i32) -> i32 {
let n = n as usize;
let mut dp = vec![1 ; n + 1];
dp[0] = 0;
for k in 3..=n {
dp[k] = dp[k-1] + dp[k-2] + dp[k-3];
}
return dp[n];
}
}
Complexity
Time Complxity:
- \(T(n) = \Theta(n)\)
Space Complxity:
- \(T(n) = O(n)\)
1141. User Activity for the Past 30 Days I
Description of Problem
Table: Activity
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| user_id | int |
| session_id | int |
| activity_date | date |
| activity_type | enum |
+---------------+---------+
This table may have duplicate rows.
The activity_type column is an ENUM (category) of type ('open_session', 'end_session', 'scroll_down', 'send_message').
The table shows the user activities for a social media website.
Note that each session belongs to exactly one user.
Write a solution to find the daily active user count for a period of 30 days ending 2019-07-27 inclusively. A user was active on someday if they made at least one activity on that day.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Activity table:
+---------+------------+---------------+---------------+
| user_id | session_id | activity_date | activity_type |
+---------+------------+---------------+---------------+
| 1 | 1 | 2019-07-20 | open_session |
| 1 | 1 | 2019-07-20 | scroll_down |
| 1 | 1 | 2019-07-20 | end_session |
| 2 | 4 | 2019-07-20 | open_session |
| 2 | 4 | 2019-07-21 | send_message |
| 2 | 4 | 2019-07-21 | end_session |
| 3 | 2 | 2019-07-21 | open_session |
| 3 | 2 | 2019-07-21 | send_message |
| 3 | 2 | 2019-07-21 | end_session |
| 4 | 3 | 2019-06-25 | open_session |
| 4 | 3 | 2019-06-25 | end_session |
+---------+------------+---------------+---------------+
Output:
+------------+--------------+
| day | active_users |
+------------+--------------+
| 2019-07-20 | 2 |
| 2019-07-21 | 2 |
+------------+--------------+
Explanation: Note that we do not care about days with zero active users.
Solution
Tags: SQL
Code (MySQL)
SELECT activity_date AS day , COUNT(DISTINCT user_id) AS active_users
FROM Activity
WHERE activity_date BETWEEN '2019-06-28' AND '2019-07-27'
GROUP BY day
HAVING active_users >= 1;
1148. Article Views I
Description of the Problem
Table: Views
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| article_id | int |
| author_id | int |
| viewer_id | int |
| view_date | date |
+---------------+---------+
There is no primary key (column with unique values) for this table, the table may have duplicate rows.
Each row of this table indicates that some viewer viewed an article (written by some author) on some date.
Note that equal author_id and viewer_id indicate the same person.
Write a solution to find all the authors that viewed at least one of their own articles.
Return the result table sorted by id in ascending order.
The result format is in the following example.
Example 1:
Input:
Views table:
+------------+-----------+-----------+------------+
| article_id | author_id | viewer_id | view_date |
+------------+-----------+-----------+------------+
| 1 | 3 | 5 | 2019-08-01 |
| 1 | 3 | 6 | 2019-08-02 |
| 2 | 7 | 7 | 2019-08-01 |
| 2 | 7 | 6 | 2019-08-02 |
| 4 | 7 | 1 | 2019-07-22 |
| 3 | 4 | 4 | 2019-07-21 |
| 3 | 4 | 4 | 2019-07-21 |
+------------+-----------+-----------+------------+
Output:
+------+
| id |
+------+
| 4 |
| 7 |
+------+
Solution
Tags: SQL
Code (SQL)
-- Write your MySQL query statement below
SELECT author_id AS id
FROM Views
WHERE author_id = viewer_id
GROUP BY author_id,viewer_id
HAVING COUNT(1) >= 1
ORDER BY id;
1179. Reformat Department Table
Description of Problem
Table: Department
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| revenue | int |
| month | varchar |
+-------------+---------+
In SQL,(id, month) is the primary key of this table.
The table has information about the revenue of each department per month.
The month has values in ["Jan","Feb","Mar","Apr","May","Jun","Jul","Aug","Sep","Oct","Nov","Dec"].
Reformat the table such that there is a department id column and a revenue column for each month.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Department table:
+------+---------+-------+
| id | revenue | month |
+------+---------+-------+
| 1 | 8000 | Jan |
| 2 | 9000 | Jan |
| 3 | 10000 | Feb |
| 1 | 7000 | Feb |
| 1 | 6000 | Mar |
+------+---------+-------+
Output:
+------+-------------+-------------+-------------+-----+-------------+
| id | Jan_Revenue | Feb_Revenue | Mar_Revenue | ... | Dec_Revenue |
+------+-------------+-------------+-------------+-----+-------------+
| 1 | 8000 | 7000 | 6000 | ... | null |
| 2 | 9000 | null | null | ... | null |
| 3 | null | 10000 | null | ... | null |
+------+-------------+-------------+-------------+-----+-------------+
Explanation: The revenue from Apr to Dec is null.
Note that the result table has 13 columns (1 for the department id + 12 for the months).
Solution
Tags: SQL
Code (MySQL)
SELECT
id,
SUM(IF(month = 'Jan', revenue, null)) AS Jan_Revenue,
SUM(IF(month = 'Feb', revenue, null)) AS Feb_Revenue,
SUM(IF(month = 'Mar', revenue, null)) AS Mar_Revenue,
SUM(IF(month = 'Apr', revenue, null)) AS Apr_Revenue,
SUM(IF(month = 'May', revenue, null)) AS May_Revenue,
SUM(IF(month = 'Jun', revenue, null)) AS Jun_Revenue,
SUM(IF(month = 'Jul', revenue, null)) AS Jul_Revenue,
SUM(IF(month = 'Aug', revenue, null)) AS Aug_Revenue,
SUM(IF(month = 'Sep', revenue, null)) AS Sep_Revenue,
SUM(IF(month = 'Oct', revenue, null)) AS Oct_Revenue,
SUM(IF(month = 'Nov', revenue, null)) AS Nov_Revenue,
SUM(IF(month = 'Dec', revenue, null)) AS Dec_Revenue
FROM Department
GROUP BY id;
1207. Unique Number of Occurrences
Description of Problem
Given an array of integers arr, return true if the number of occurrences of each value in the array is unique or false otherwise.
Example 1:
Input: arr = [1,2,2,1,1,3]
Output: true
Explanation: The value 1 has 3 occurrences, 2 has 2 and 3 has 1. No two values have the same number of occurrences.
Example 2:
Input: arr = [1,2]
Output: false
Example 3:
Input: arr = [-3,0,1,-3,1,1,1,-3,10,0]
Output: true
Constraints:
1 <= arr.length <= 1000-1000 <= arr[i] <= 1000
Solution
Code (Rust)
impl Solution {
pub fn unique_occurrences(arr: Vec<i32>) -> bool {
use std::collections::HashMap;
use std::collections::HashSet;
let mut counting = HashMap::new();
for a in arr.into_iter() {
if let Some(x) = counting.get_mut(&a) {
*x += 1;
}else{
counting.insert(a, 1);
}
}
let vec: Vec<i32> = counting.into_values().collect();
let m = vec.len();
let set: HashSet<i32> = vec.into_iter().collect();
let n = set.len();
m == n
}
}
Complexity
- n is length of
arr - Assume HashMap query costs constant time
Time Complexity
- \(T(n) = \Theta(3n) = \Theta(n) \)
arrinto HashMaparrinto Vectorarrinto Set
Auxiliary Space
- \(S(n) = O(2n) = O(n) \)
- Vector and HashSet
1211. Queries Quality and Percentage
Description of Problem
Table: Queries
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| query_name | varchar |
| result | varchar |
| position | int |
| rating | int |
+-------------+---------+
This table may have duplicate rows.
This table contains information collected from some queries on a database.
The position column has a value from 1 to 500.
The rating column has a value from 1 to 5. Query with rating less than 3 is a poor query.
We define query quality as:
The average of the ratio between query rating and its position.
We also define poor query percentage as:
The percentage of all queries with rating less than 3.
Write a solution to find each query_name, the quality and poor_query_percentage.
Both quality and poor_query_percentage should be rounded to 2 decimal places.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Queries table:
+------------+-------------------+----------+--------+
| query_name | result | position | rating |
+------------+-------------------+----------+--------+
| Dog | Golden Retriever | 1 | 5 |
| Dog | German Shepherd | 2 | 5 |
| Dog | Mule | 200 | 1 |
| Cat | Shirazi | 5 | 2 |
| Cat | Siamese | 3 | 3 |
| Cat | Sphynx | 7 | 4 |
+------------+-------------------+----------+--------+
Output:
+------------+---------+-----------------------+
| query_name | quality | poor_query_percentage |
+------------+---------+-----------------------+
| Dog | 2.50 | 33.33 |
| Cat | 0.66 | 33.33 |
+------------+---------+-----------------------+
Explanation:
Dog queries quality is ((5 / 1) + (5 / 2) + (1 / 200)) / 3 = 2.50
Dog queries poor_ query_percentage is (1 / 3) * 100 = 33.33
Cat queries quality equals ((2 / 5) + (3 / 3) + (4 / 7)) / 3 = 0.66
Cat queries poor_ query_percentage is (1 / 3) * 100 = 33.33
Solution
Tags: SQL Aggregate Functions
Code (MySQL)
-- Write your MySQL query statement below
SELECT
query_name,
ROUND(AVG(rating / position), 2) as quality,
ROUND(AVG(rating < 3) * 100, 2) as poor_query_percentage
FROM queries
GROUP BY query_name
HAVING query_name IS NOT NULL;
1251. Average Selling Price
Description of the Problem
Table: Prices
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| product_id | int |
| start_date | date |
| end_date | date |
| price | int |
+---------------+---------+
(product_id, start_date, end_date) is the primary key (combination of columns with unique values) for this table.
Each row of this table indicates the price of the product_id in the period from start_date to end_date.
For each product_id there will be no two overlapping periods. That means there will be no two intersecting periods for the same product_id.
Table: UnitsSold
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| product_id | int |
| purchase_date | date |
| units | int |
+---------------+---------+
This table may contain duplicate rows.
Each row of this table indicates the date, units, and product_id of each product sold.
Write a solution to find the average selling price for each product. average_price should be rounded to 2 decimal places.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Prices table:
+------------+------------+------------+--------+
| product_id | start_date | end_date | price |
+------------+------------+------------+--------+
| 1 | 2019-02-17 | 2019-02-28 | 5 |
| 1 | 2019-03-01 | 2019-03-22 | 20 |
| 2 | 2019-02-01 | 2019-02-20 | 15 |
| 2 | 2019-02-21 | 2019-03-31 | 30 |
+------------+------------+------------+--------+
UnitsSold table:
+------------+---------------+-------+
| product_id | purchase_date | units |
+------------+---------------+-------+
| 1 | 2019-02-25 | 100 |
| 1 | 2019-03-01 | 15 |
| 2 | 2019-02-10 | 200 |
| 2 | 2019-03-22 | 30 |
+------------+---------------+-------+
Output:
+------------+---------------+
| product_id | average_price |
+------------+---------------+
| 1 | 6.96 |
| 2 | 16.96 |
+------------+---------------+
Explanation:
Average selling price = Total Price of Product / Number of products sold.
Average selling price for product 1 = ((100 * 5) + (15 * 20)) / 115 = 6.96
Average selling price for product 2 = ((200 * 15) + (30 * 30)) / 230 = 16.96
Solution
Tags: SQL Joins Aggregate Functions
Code (MySQL)
-- Write your MySQL query statement below
WITH t AS(
SELECT
p.product_id,
ROUND(SUM(p.price * u.units) / SUM(u.units), 2) AS average_price
FROM Prices p
LEFT JOIN UnitsSold u
ON p.product_id = u.product_id
AND u.purchase_date BETWEEN p.start_date AND p.end_date
GROUP BY p.product_id
)
SELECT
product_id,
IF(average_price IS NULL, 0, average_price) AS average_price
FROM t;
1280. Students and Examinations
Description of the Problem
Table: Students
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| student_id | int |
| student_name | varchar |
+---------------+---------+
student_id is the primary key (column with unique values) for this table.
Each row of this table contains the ID and the name of one student in the school.
Table: Subjects
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| subject_name | varchar |
+--------------+---------+
subject_name is the primary key (column with unique values) for this table.
Each row of this table contains the name of one subject in the school.
Table: Examinations
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| student_id | int |
| subject_name | varchar |
+--------------+---------+
There is no primary key (column with unique values) for this table. It may contain duplicates.
Each student from the Students table takes every course from the Subjects table.
Each row of this table indicates that a student with ID student_id attended the exam of subject_name.
Write a solution to find the number of times each student attended each exam.
Return the result table ordered by student_id and subject_name.
The result format is in the following example.
Example 1:
Input:
Students table:
+------------+--------------+
| student_id | student_name |
+------------+--------------+
| 1 | Alice |
| 2 | Bob |
| 13 | John |
| 6 | Alex |
+------------+--------------+
Subjects table:
+--------------+
| subject_name |
+--------------+
| Math |
| Physics |
| Programming |
+--------------+
Examinations table:
+------------+--------------+
| student_id | subject_name |
+------------+--------------+
| 1 | Math |
| 1 | Physics |
| 1 | Programming |
| 2 | Programming |
| 1 | Physics |
| 1 | Math |
| 13 | Math |
| 13 | Programming |
| 13 | Physics |
| 2 | Math |
| 1 | Math |
+------------+--------------+
Output:
+------------+--------------+--------------+----------------+
| student_id | student_name | subject_name | attended_exams |
+------------+--------------+--------------+----------------+
| 1 | Alice | Math | 3 |
| 1 | Alice | Physics | 2 |
| 1 | Alice | Programming | 1 |
| 2 | Bob | Math | 1 |
| 2 | Bob | Physics | 0 |
| 2 | Bob | Programming | 1 |
| 6 | Alex | Math | 0 |
| 6 | Alex | Physics | 0 |
| 6 | Alex | Programming | 0 |
| 13 | John | Math | 1 |
| 13 | John | Physics | 1 |
| 13 | John | Programming | 1 |
+------------+--------------+--------------+----------------+
Explanation:
The result table should contain all students and all subjects.
Alice attended the Math exam 3 times, the Physics exam 2 times, and the Programming exam 1 time.
Bob attended the Math exam 1 time, the Programming exam 1 time, and did not attend the Physics exam.
Alex did not attend any exams.
John attended the Math exam 1 time, the Physics exam 1 time, and the Programming exam 1 time.
Solution
Tags: SQL Joins Grouping Aggregate Functions
Code (MySQL)
-- Write your MySQL query statement below
-- Count only non-null subject_name
SELECT
stu.student_id, stu.student_name, sub.subject_name,
COUNT(e.subject_name) AS attended_exams
FROM Students stu
-- Cross Product
INNER JOIN Subjects sub
-- LEFT JOIN to keep left query
LEFT JOIN Examinations e
ON stu.student_id = e.student_id
AND sub.subject_name = e.subject_name
GROUP BY stu.student_id, stu.student_name, sub.subject_name
ORDER BY stu.student_id, sub.subject_name
;
1290. Convert Binary Number in a Linked List to Integer
Description of the Problem
Given head which is a reference node to a singly-linked list. The value of each node in the linked list is either 0 or 1. The linked list holds the binary representation of a number.
Return the decimal value of the number in the linked list.
The most significant bit is at the head of the linked list.
Example 1:
Input: head = [1,0,1]
Output: 5
Explanation: (101) in base 2 = (5) in base 10
Example 2:
Input: head = [0]
Output: 0
Constraints:
- The Linked List is not empty.
- Number of nodes will not exceed
30. - Each node's value is either
0or1.
Solution
Tags: Bit Manipulation
Code (Rust)
// Definition for singly-linked list.
// #[derive(PartialEq, Eq, Clone, Debug)]
// pub struct ListNode {
// pub val: i32,
// pub next: Option<Box<ListNode>>
// }
//
// impl ListNode {
// #[inline]
// fn new(val: i32) -> Self {
// ListNode {
// next: None,
// val
// }
// }
// }
impl Solution {
pub fn get_decimal_value(head: Option<Box<ListNode>>) -> i32 {
let mut head = head;
let mut sum = 0;
while let Some(node) = head.take() {
sum = sum << 1;
sum ^= node.val;
head = node.next;
}
return sum;
}
}
Complexity
- n is the number of elements in the linkedlist
Time complexity:
- \( T(n) = O(n) \)
Auxiliary Space:
- \( S(n) = O(1) \)
1327. List the Products Ordered in a Period
Description of Problem
Table: Products
+------------------+---------+
| Column Name | Type |
+------------------+---------+
| product_id | int |
| product_name | varchar |
| product_category | varchar |
+------------------+---------+
product_id is the primary key (column with unique values) for this table.
This table contains data about the company's products.
Table: Orders
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| product_id | int |
| order_date | date |
| unit | int |
+---------------+---------+
This table may have duplicate rows.
product_id is a foreign key (reference column) to the Products table.
unit is the number of products ordered in order_date.
Write a solution to get the names of products that have at least 100 units ordered in February 2020 and their amount.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Products table:
+-------------+-----------------------+------------------+
| product_id | product_name | product_category |
+-------------+-----------------------+------------------+
| 1 | Leetcode Solutions | Book |
| 2 | Jewels of Stringology | Book |
| 3 | HP | Laptop |
| 4 | Lenovo | Laptop |
| 5 | Leetcode Kit | T-shirt |
+-------------+-----------------------+------------------+
Orders table:
+--------------+--------------+----------+
| product_id | order_date | unit |
+--------------+--------------+----------+
| 1 | 2020-02-05 | 60 |
| 1 | 2020-02-10 | 70 |
| 2 | 2020-01-18 | 30 |
| 2 | 2020-02-11 | 80 |
| 3 | 2020-02-17 | 2 |
| 3 | 2020-02-24 | 3 |
| 4 | 2020-03-01 | 20 |
| 4 | 2020-03-04 | 30 |
| 4 | 2020-03-04 | 60 |
| 5 | 2020-02-25 | 50 |
| 5 | 2020-02-27 | 50 |
| 5 | 2020-03-01 | 50 |
+--------------+--------------+----------+
Output:
+--------------------+---------+
| product_name | unit |
+--------------------+---------+
| Leetcode Solutions | 130 |
| Leetcode Kit | 100 |
+--------------------+---------+
Explanation:
Products with product_id = 1 is ordered in February a total of (60 + 70) = 130.
Products with product_id = 2 is ordered in February a total of 80.
Products with product_id = 3 is ordered in February a total of (2 + 3) = 5.
Products with product_id = 4 was not ordered in February 2020.
Products with product_id = 5 is ordered in February a total of (50 + 50) = 100.
Solution
Tags: SQL Grouping
Code (MySQL)
-- Write your MySQL query statement below
SELECT
(SELECT p.product_name FROM Products p WHERE p.product_id = o.product_id) AS product_name,
SUM(unit) as unit
FROM Orders o
WHERE o.order_date BETWEEN '2020-02-01' AND '2020-02-29'
GROUP BY o.product_id
HAVING unit >= 100
;
1378. Replace Employee ID With The Unique Identifier
Description of the Problem
Table: Employees
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| name | varchar |
+---------------+---------+
id is the primary key (column with unique values) for this table.
Each row of this table contains the id and the name of an employee in a company.
Table: EmployeeUNI
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| unique_id | int |
+---------------+---------+
(id, unique_id) is the primary key (combination of columns with unique values) for this table.
Each row of this table contains the id and the corresponding unique id of an employee in the company.
Write a solution to show the unique ID of each user, If a user does not have a unique ID replace just show null.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Employees table:
+----+----------+
| id | name |
+----+----------+
| 1 | Alice |
| 7 | Bob |
| 11 | Meir |
| 90 | Winston |
| 3 | Jonathan |
+----+----------+
EmployeeUNI table:
+----+-----------+
| id | unique_id |
+----+-----------+
| 3 | 1 |
| 11 | 2 |
| 90 | 3 |
+----+-----------+
Output:
+-----------+----------+
| unique_id | name |
+-----------+----------+
| null | Alice |
| null | Bob |
| 2 | Meir |
| 3 | Winston |
| 1 | Jonathan |
+-----------+----------+
Explanation:
Alice and Bob do not have a unique ID, We will show null instead.
The unique ID of Meir is 2.
The unique ID of Winston is 3.
The unique ID of Jonathan is 1.
Solution
Tags: SQL
Code (MySQL)
-- Write your MySQL query statement below
SELECT unique_id, name
FROM Employees emp
LEFT JOIN EmployeeUNI uni
ON emp.id = uni.id
;
1407. Top Travellers
Description of Problem
Table: Users
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| name | varchar |
+---------------+---------+
id is the column with unique values for this table.
name is the name of the user.
Table: Rides
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| user_id | int |
| distance | int |
+---------------+---------+
id is the column with unique values for this table.
user_id is the id of the user who traveled the distance "distance".
Write a solution to report the distance traveled by each user.
Return the result table ordered by travelled_distance in descending order, if two or more users traveled the same distance, order them by their name in ascending order.
The result format is in the following example.
Example 1:
Input:
Users table:
+------+-----------+
| id | name |
+------+-----------+
| 1 | Alice |
| 2 | Bob |
| 3 | Alex |
| 4 | Donald |
| 7 | Lee |
| 13 | Jonathan |
| 19 | Elvis |
+------+-----------+
Rides table:
+------+----------+----------+
| id | user_id | distance |
+------+----------+----------+
| 1 | 1 | 120 |
| 2 | 2 | 317 |
| 3 | 3 | 222 |
| 4 | 7 | 100 |
| 5 | 13 | 312 |
| 6 | 19 | 50 |
| 7 | 7 | 120 |
| 8 | 19 | 400 |
| 9 | 7 | 230 |
+------+----------+----------+
Output:
+----------+--------------------+
| name | travelled_distance |
+----------+--------------------+
| Elvis | 450 |
| Lee | 450 |
| Bob | 317 |
| Jonathan | 312 |
| Alex | 222 |
| Alice | 120 |
| Donald | 0 |
+----------+--------------------+
Explanation:
Elvis and Lee traveled 450 miles, Elvis is the top traveler as his name is alphabetically smaller than Lee.
Bob, Jonathan, Alex, and Alice have only one ride and we just order them by the total distances of the ride.
Donald did not have any rides, the distance traveled by him is 0.
Solution
Tags: SQL JOIN
Code 1
WITH s AS (
SELECT user_id, SUM(distance) AS travelled_distance
FROM Rides
GROUP BY user_id
)
SELECT u.name, IF(s.user_id IS NULL, 0, s.travelled_distance) AS travelled_distance
FROM Users u
LEFT JOIN s ON u.id = s.user_id
ORDER BY travelled_distance DESC, u.name ASC
;
Code 2 - Seems simpler
WITH T AS (
SELECT u.id, u.name, IF(r.user_id IS NULL, 0, SUM(distance)) AS travelled_distance
FROM Users u
LEFT JOIN Rides r ON u.id = r.user_id
GROUP BY u.id, u.name
ORDER BY travelled_distance DESC, u.name ASC
)
SELECT T.name, T.travelled_distance
FROM T;
1431. Kids With the Greatest Number of Candies
Description of Problem
There are n kids with candies. You are given an integer array candies, where each candies[i] represents the number of candies the ith kid has, and an integer extraCandies, denoting the number of extra candies that you have.
Return a boolean array result of length n, where result[i] is true if, after giving the ith kid all the extraCandies, they will have the greatest number of candies among all the kids, or false otherwise.
Note that multiple kids can have the greatest number of candies.
Example 1:
Input: candies = [2,3,5,1,3], extraCandies = 3
Output: [true,true,true,false,true]
Explanation: If you give all extraCandies to:
- Kid 1, they will have 2 + 3 = 5 candies, which is the greatest among the kids.
- Kid 2, they will have 3 + 3 = 6 candies, which is the greatest among the kids.
- Kid 3, they will have 5 + 3 = 8 candies, which is the greatest among the kids.
- Kid 4, they will have 1 + 3 = 4 candies, which is not the greatest among the kids.
- Kid 5, they will have 3 + 3 = 6 candies, which is the greatest among the kids.
Example 2:
Input: candies = [4,2,1,1,2], extraCandies = 1
Output: [true,false,false,false,false]
Explanation: There is only 1 extra candy.
Kid 1 will always have the greatest number of candies, even if a different kid is given the extra candy.
Example 3:
Input: candies = [12,1,12], extraCandies = 10
Output: [true,false,true]
Constraints:
n == candies.length2 <= n <= 1001 <= candies[i] <= 1001 <= extraCandies <= 50
Solution
Code (Rust)
impl Solution {
pub fn kids_with_candies(candies: Vec<i32>, extra_candies: i32) -> Vec<bool> {
// The constrains guarantees that the candies is not empty
let max = *candies.iter().max().unwrap();
let mut is_greatest = vec![];
for &c in candies.iter() {
if c + extra_candies >= max {
is_greatest.push(true);
}else{
is_greatest.push(false);
}
}
return is_greatest;
}
}
Complexity
- n is length of
candies
Time Complexity
- \(T(n)=O(n)\)
Auxiliary Space
- \(S(n)=O(1)\)
1484. Group Sold Products By The Date
Description of the Problem
Table Activities:
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| sell_date | date |
| product | varchar |
+-------------+---------+
There is no primary key (column with unique values) for this table. It may contain duplicates.
Each row of this table contains the product name and the date it was sold in a market.
Write a solution to find for each date the number of different products sold and their names.
The sold products names for each date should be sorted lexicographically.
Return the result table ordered by sell_date.
The result format is in the following example.
Example 1:
Input:
Activities table:
+------------+------------+
| sell_date | product |
+------------+------------+
| 2020-05-30 | Headphone |
| 2020-06-01 | Pencil |
| 2020-06-02 | Mask |
| 2020-05-30 | Basketball |
| 2020-06-01 | Bible |
| 2020-06-02 | Mask |
| 2020-05-30 | T-Shirt |
+------------+------------+
Output:
+------------+----------+------------------------------+
| sell_date | num_sold | products |
+------------+----------+------------------------------+
| 2020-05-30 | 3 | Basketball,Headphone,T-shirt |
| 2020-06-01 | 2 | Bible,Pencil |
| 2020-06-02 | 1 | Mask |
+------------+----------+------------------------------+
Explanation:
For 2020-05-30, Sold items were (Headphone, Basketball, T-shirt), we sort them lexicographically and separate them by a comma.
For 2020-06-01, Sold items were (Pencil, Bible), we sort them lexicographically and separate them by a comma.
For 2020-06-02, the Sold item is (Mask), we just return it.
Solution
Tags: SQL Advanced Select
Code (MySQL)
-- Write your MySQL query statement below
SELECT
sell_date, COUNT(DISTINCT product) AS num_sold,
GROUP_CONCAT(DISTINCT product ORDER BY product) as products
FROM Activities
GROUP BY sell_date
ORDER BY sell_date;
1486. XOR Operation in an Array
Description of Problem
You are given an integer n and an integer start.
Define an array nums where nums[i] = start + 2 * i (0-indexed) and n == nums.length.
Return the bitwise XOR of all elements of nums.
Example 1:
Input: n = 5, start = 0
Output: 8
Explanation: Array nums is equal to [0, 2, 4, 6, 8] where (0 ^ 2 ^ 4 ^ 6 ^ 8) = 8.
Where "^" corresponds to bitwise XOR operator.
Example 2:
Input: n = 4, start = 3
Output: 8
Explanation: Array nums is equal to [3, 5, 7, 9] where (3 ^ 5 ^ 7 ^ 9) = 8.
Constraints:
1 <= n <= 10000 <= start <= 1000n == nums.length
Solution
Code (Rust)
impl Solution {
pub fn xor_operation (n: i32, start: i32) -> i32 {
let mut sum = start;
for i in 1..n {
sum ^= start + 2 * i;
}
return sum;
}
}
1517. Find Users With Valid E-Mails
Description of Problem
Table: Users
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| user_id | int |
| name | varchar |
| mail | varchar |
+---------------+---------+
user_id is the primary key (column with unique values) for this table.
This table contains information of the users signed up in a website. Some e-mails are invalid.
Write a solution to find the users who have valid emails.
A valid e-mail has a prefix name and a domain where:
- The prefix name is a string that may contain letters (upper or lower case), digits, underscore
'_', period'.', and/or dash'-'. The prefix name must start with a letter. - The domain is
'@leetcode.com'. Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Users table:
+---------+-----------+-------------------------+
| user_id | name | mail |
+---------+-----------+-------------------------+
| 1 | Winston | winston@leetcode.com |
| 2 | Jonathan | jonathanisgreat |
| 3 | Annabelle | bella-@leetcode.com |
| 4 | Sally | sally.come@leetcode.com |
| 5 | Marwan | quarz#2020@leetcode.com |
| 6 | David | david69@gmail.com |
| 7 | Shapiro | .shapo@leetcode.com |
+---------+-----------+-------------------------+
Output:
+---------+-----------+-------------------------+
| user_id | name | mail |
+---------+-----------+-------------------------+
| 1 | Winston | winston@leetcode.com |
| 3 | Annabelle | bella-@leetcode.com |
| 4 | Sally | sally.come@leetcode.com |
+---------+-----------+-------------------------+
Explanation:
The mail of user 2 does not have a domain.
The mail of user 5 has the # sign which is not allowed.
The mail of user 6 does not have the leetcode domain.
The mail of user 7 starts with a period.
Solution
Tags: SQL
Code (MySQL)
-- Write your MySQL query statement below
SELECT *
FROM Users
WHERE mail REGEXP '^[A-Za-z][A-Za-z0-9_.-]*@leetcode\\.com$';
Reference
1527. Patients With a Condition
Description
Table: Patients
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| patient_id | int |
| patient_name | varchar |
| conditions | varchar |
+--------------+---------+
patient_id is the primary key (column with unique values) for this table.
'conditions' contains 0 or more code separated by spaces.
This table contains information of the patients in the hospital.
Write a solution to find the patient_id, patient_name, and conditions of the patients who have Type I Diabetes. Type I Diabetes always starts with DIAB1 prefix.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Patients table:
+------------+--------------+--------------+
| patient_id | patient_name | conditions |
+------------+--------------+--------------+
| 1 | Daniel | YFEV COUGH |
| 2 | Alice | |
| 3 | Bob | DIAB100 MYOP |
| 4 | George | ACNE DIAB100 |
| 5 | Alain | DIAB201 |
+------------+--------------+--------------+
Output:
+------------+--------------+--------------+
| patient_id | patient_name | conditions |
+------------+--------------+--------------+
| 3 | Bob | DIAB100 MYOP |
| 4 | George | ACNE DIAB100 |
+------------+--------------+--------------+
Explanation: Bob and George both have a condition that starts with DIAB1.
Solution
Tags: SQL
The solutions are inspired by Micheal_V's Solution
Code (MySQL)
# Write your MySQL query statement below
SELECT *
FROM Patients
WHERE conditions REGEXP '\\bDIAB1';
Code (MySQL)
# Write your MySQL query statement below
SELECT *
FROM Patients
WHERE conditions LIKE '% DIAB1%' OR conditions LIKE 'DIAB1%';
1581. Customer Who Visited but Did Not Make Any Transactions
Description of the Problem
Table: Visits
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| visit_id | int |
| customer_id | int |
+-------------+---------+
visit_id is the column with unique values for this table.
This table contains information about the customers who visited the mall.
Table: Transactions
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| transaction_id | int |
| visit_id | int |
| amount | int |
+----------------+---------+
transaction_id is column with unique values for this table.
This table contains information about the transactions made during the visit_id.
Write a solution to find the IDs of the users who visited without making any transactions and the number of times they made these types of visits.
Return the result table sorted in any order.
The result format is in the following example.
Example 1:
Input:
Visits
+----------+-------------+
| visit_id | customer_id |
+----------+-------------+
| 1 | 23 |
| 2 | 9 |
| 4 | 30 |
| 5 | 54 |
| 6 | 96 |
| 7 | 54 |
| 8 | 54 |
+----------+-------------+
Transactions
+----------------+----------+--------+
| transaction_id | visit_id | amount |
+----------------+----------+--------+
| 2 | 5 | 310 |
| 3 | 5 | 300 |
| 9 | 5 | 200 |
| 12 | 1 | 910 |
| 13 | 2 | 970 |
+----------------+----------+--------+
Output:
+-------------+----------------+
| customer_id | count_no_trans |
+-------------+----------------+
| 54 | 2 |
| 30 | 1 |
| 96 | 1 |
+-------------+----------------+
Explanation:
Customer with id = 23 visited the mall once and made one transaction during the visit with id = 12.
Customer with id = 9 visited the mall once and made one transaction during the visit with id = 13.
Customer with id = 30 visited the mall once and did not make any transactions.
Customer with id = 54 visited the mall three times. During 2 visits they did not make any transactions, and during one visit they made 3 transactions.
Customer with id = 96 visited the mall once and did not make any transactions.
As we can see, users with IDs 30 and 96 visited the mall one time without making any transactions. Also, user 54 visited the mall twice and did not make any transactions.
Solution
Tags: SQL Subquery
Code (MySQL)
-- Write your MySQL query statement below
SELECT v.customer_id, COUNT(1) AS count_no_trans
FROM Visits v
WHERE NOT EXISTS(
SELECT 1 FROM Transactions t WHERE t.visit_id = v.visit_id
)
GROUP BY v.customer_id;
1587. Bank Account Summary II
Description of Problem
Table: Users
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| account | int |
| name | varchar |
+--------------+---------+
account is the primary key (column with unique values) for this table.
Each row of this table contains the account number of each user in the bank.
There will be no two users having the same name in the table.
Table: Transactions
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| trans_id | int |
| account | int |
| amount | int |
| transacted_on | date |
+---------------+---------+
trans_id is the primary key (column with unique values) for this table.
Each row of this table contains all changes made to all accounts.
amount is positive if the user received money and negative if they transferred money.
All accounts start with a balance of 0.
Write a solution to report the name and balance of users with a balance higher than 10000. The balance of an account is equal to the sum of the amounts of all transactions involving that account.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Users table:
+------------+--------------+
| account | name |
+------------+--------------+
| 900001 | Alice |
| 900002 | Bob |
| 900003 | Charlie |
+------------+--------------+
Transactions table:
+------------+------------+------------+---------------+
| trans_id | account | amount | transacted_on |
+------------+------------+------------+---------------+
| 1 | 900001 | 7000 | 2020-08-01 |
| 2 | 900001 | 7000 | 2020-09-01 |
| 3 | 900001 | -3000 | 2020-09-02 |
| 4 | 900002 | 1000 | 2020-09-12 |
| 5 | 900003 | 6000 | 2020-08-07 |
| 6 | 900003 | 6000 | 2020-09-07 |
| 7 | 900003 | -4000 | 2020-09-11 |
+------------+------------+------------+---------------+
Output:
+------------+------------+
| name | balance |
+------------+------------+
| Alice | 11000 |
+------------+------------+
Explanation:
Alice's balance is (7000 + 7000 - 3000) = 11000.
Bob's balance is 1000.
Charlie's balance is (6000 + 6000 - 4000) = 8000.
Solution
Tags: SQL
Code (MySQL)
WITH t AS (
SELECT account, SUM(amount) as balance
FROM Transactions
GROUP BY account
)
SELECT u.name, IF(t.account IS NOT NULL, t.balance, 0) as balance
FROM Users u
LEFT JOIN t ON t.account = u.account
WHERE balance > 10000
1633. Percentage of Users Attended a Contest
Description of Problem
Table: Users
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| user_id | int |
| user_name | varchar |
+-------------+---------+
user_id is the primary key (column with unique values) for this table.
Each row of this table contains the name and the id of a user.
Table: Register
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| contest_id | int |
| user_id | int |
+-------------+---------+
(contest_id, user_id) is the primary key (combination of columns with unique values) for this table.
Each row of this table contains the id of a user and the contest they registered into.
Write a solution to find the percentage of the users registered in each contest rounded to two decimals.
Return the result table ordered by percentage in descending order. In case of a tie, order it by contest_id in ascending order.
The result format is in the following example.
Example 1:
Input:
Users table:
+---------+-----------+
| user_id | user_name |
+---------+-----------+
| 6 | Alice |
| 2 | Bob |
| 7 | Alex |
+---------+-----------+
Register table:
+------------+---------+
| contest_id | user_id |
+------------+---------+
| 215 | 6 |
| 209 | 2 |
| 208 | 2 |
| 210 | 6 |
| 208 | 6 |
| 209 | 7 |
| 209 | 6 |
| 215 | 7 |
| 208 | 7 |
| 210 | 2 |
| 207 | 2 |
| 210 | 7 |
+------------+---------+
Output:
+------------+------------+
| contest_id | percentage |
+------------+------------+
| 208 | 100.0 |
| 209 | 100.0 |
| 210 | 100.0 |
| 215 | 66.67 |
| 207 | 33.33 |
+------------+------------+
Explanation:
All the users registered in contests 208, 209, and 210. The percentage is 100% and we sort them in the answer table by contest_id in ascending order.
Alice and Alex registered in contest 215 and the percentage is ((2/3) * 100) = 66.67%
Bob registered in contest 207 and the percentage is ((1/3) * 100) = 33.33%
Solution
Tags: SQL Aggregate Functions
Code (MySQL)
-- Write your MySQL query statement below
SELECT
r.contest_id,
ROUND(COUNT(1) / (SELECT COUNT(1) FROM Users) * 100,2) AS percentage
FROM Register r
GROUP BY r.contest_id
ORDER BY percentage DESC, contest_id ASC
1661. Average Time of Process per Machine
Description of the Problem
Table: Activity
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| machine_id | int |
| process_id | int |
| activity_type | enum |
| timestamp | float |
+----------------+---------+
The table shows the user activities for a factory website.
(machine_id, process_id, activity_type) is the primary key (combination of columns with unique values) of this table.
machine_id is the ID of a machine.
process_id is the ID of a process running on the machine with ID machine_id.
activity_type is an ENUM (category) of type ('start', 'end').
timestamp is a float representing the current time in seconds.
'start' means the machine starts the process at the given timestamp and 'end' means the machine ends the process at the given timestamp.
The 'start' timestamp will always be before the 'end' timestamp for every (machine_id, process_id) pair.
There is a factory website that has several machines each running the same number of processes. Write a solution to find the average time each machine takes to complete a process.
The time to complete a process is the 'end' timestamp minus the 'start' timestamp. The average time is calculated by the total time to complete every process on the machine divided by the number of processes that were run.
The resulting table should have the machine_id along with the average time as processing_time, which should be rounded to 3 decimal places.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Activity table:
+------------+------------+---------------+-----------+
| machine_id | process_id | activity_type | timestamp |
+------------+------------+---------------+-----------+
| 0 | 0 | start | 0.712 |
| 0 | 0 | end | 1.520 |
| 0 | 1 | start | 3.140 |
| 0 | 1 | end | 4.120 |
| 1 | 0 | start | 0.550 |
| 1 | 0 | end | 1.550 |
| 1 | 1 | start | 0.430 |
| 1 | 1 | end | 1.420 |
| 2 | 0 | start | 4.100 |
| 2 | 0 | end | 4.512 |
| 2 | 1 | start | 2.500 |
| 2 | 1 | end | 5.000 |
+------------+------------+---------------+-----------+
Output:
+------------+-----------------+
| machine_id | processing_time |
+------------+-----------------+
| 0 | 0.894 |
| 1 | 0.995 |
| 2 | 1.456 |
+------------+-----------------+
Explanation:
There are 3 machines running 2 processes each.
Machine 0's average time is ((1.520 - 0.712) + (4.120 - 3.140)) / 2 = 0.894
Machine 1's average time is ((1.550 - 0.550) + (1.420 - 0.430)) / 2 = 0.995
Machine 2's average time is ((4.512 - 4.100) + (5.000 - 2.500)) / 2 = 1.456
Solution
Tags: SQL Joins Aggregate Functions
Code (MySQL)
-- Write your MySQL query statement below
SELECT t1.machine_id, ROUND(AVG(t2.timestamp - t1.timestamp),3) AS processing_time
FROM
(
SELECT *
FROM Activity
WHERE activity_type = 'start'
) t1
INNER JOIN
(
SELECT *
FROM Activity
WHERE activity_type = 'end'
) t2
ON t1.machine_id = t2.machine_id
AND t1.process_id = t2.process_id
GROUP BY t1.machine_id;
1667. Fix Names in a Table
Description of the Problem
Table: Users
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| user_id | int |
| name | varchar |
+----------------+---------+
user_id is the primary key (column with unique values) for this table.
This table contains the ID and the name of the user. The name consists of only lowercase and uppercase characters.
Write a solution to fix the names so that only the first character is uppercase and the rest are lowercase.
Return the result table ordered by user_id.
The result format is in the following example.
Example 1:
Input:
Users table:
+---------+-------+
| user_id | name |
+---------+-------+
| 1 | aLice |
| 2 | bOB |
+---------+-------+
Output:
+---------+-------+
| user_id | name |
+---------+-------+
| 1 | Alice |
| 2 | Bob |
+---------+-------+
Solution
Tags: SQL
Code (MySQL)
-- Write your MySQL query statement below
SELECT
user_id,
CONCAT(
UCASE(LEFT(name, 1)),
LCASE(SUBSTRING(name, 2))
) AS name
FROM Users
ORDER BY user_id;
1683. Invalid Tweets
Description of the Problem
Table: Tweets
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| tweet_id | int |
| content | varchar |
+----------------+---------+
tweet_id is the primary key (column with unique values) for this table.
This table contains all the tweets in a social media app.
Write a solution to find the IDs of the invalid tweets. The tweet is invalid if the number of characters used in the content of the tweet is strictly greater than 15.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Tweets table:
+----------+----------------------------------+
| tweet_id | content |
+----------+----------------------------------+
| 1 | Vote for Biden |
| 2 | Let us make America great again! |
+----------+----------------------------------+
Output:
+----------+
| tweet_id |
+----------+
| 2 |
+----------+
Explanation:
Tweet 1 has length = 14. It is a valid tweet.
Tweet 2 has length = 32. It is an invalid tweet.
Solution
Tags: SQL
Code (MySQL)
-- Write your MySQL query statement below
SELECT tweet_id
FROM Tweets
WHERE LENGTH(content) > 15;
1693. Daily Leads and Partners
Description of Problem
Table: DailySales
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| date_id | date |
| make_name | varchar |
| lead_id | int |
| partner_id | int |
+-------------+---------+
There is no primary key (column with unique values) for this table. It may contain duplicates.
This table contains the date and the name of the product sold and the IDs of the lead and partner it was sold to.
The name consists of only lowercase English letters.
For each date_id and make_name, find the number of distinct lead_id's and distinct partner_id's.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
DailySales table:
+-----------+-----------+---------+------------+
| date_id | make_name | lead_id | partner_id |
+-----------+-----------+---------+------------+
| 2020-12-8 | toyota | 0 | 1 |
| 2020-12-8 | toyota | 1 | 0 |
| 2020-12-8 | toyota | 1 | 2 |
| 2020-12-7 | toyota | 0 | 2 |
| 2020-12-7 | toyota | 0 | 1 |
| 2020-12-8 | honda | 1 | 2 |
| 2020-12-8 | honda | 2 | 1 |
| 2020-12-7 | honda | 0 | 1 |
| 2020-12-7 | honda | 1 | 2 |
| 2020-12-7 | honda | 2 | 1 |
+-----------+-----------+---------+------------+
Output:
+-----------+-----------+--------------+-----------------+
| date_id | make_name | unique_leads | unique_partners |
+-----------+-----------+--------------+-----------------+
| 2020-12-8 | toyota | 2 | 3 |
| 2020-12-7 | toyota | 1 | 2 |
| 2020-12-8 | honda | 2 | 2 |
| 2020-12-7 | honda | 3 | 2 |
+-----------+-----------+--------------+-----------------+
Explanation:
For 2020-12-8, toyota gets leads = [0, 1] and partners = [0, 1, 2] while honda gets leads = [1, 2] and partners = [1, 2].
For 2020-12-7, toyota gets leads = [0] and partners = [1, 2] while honda gets leads = [0, 1, 2] and partners = [1, 2].
Solution
Tags: SQL
Code (MySQL)
SELECT
date_id, make_name,
COUNT(DISTINCT lead_id) AS unique_leads,
COUNT(DISTINCT partner_id) AS unique_partners
FROM DailySales
GROUP BY date_id, make_name
1704. Determine if String Halves Are Alike
Description of Problem
You are given a string s of even length. Split this string into two halves of equal lengths, and let a be the first half and b be the second half.
Two strings are alike if they have the same number of vowels ('a', 'e', 'i', 'o', 'u', 'A', 'E', 'I', 'O', 'U'). Notice that s contains uppercase and lowercase letters.
Return true if a and b are alike. Otherwise, return false.
Example 1:
Input: s = "book"
Output: true
Explanation: a = "bo" and b = "ok". a has 1 vowel and b has 1 vowel. Therefore, they are alike.
Example 2:
Input: s = "textbook"
Output: false
Explanation: a = "text" and b = "book". a has 1 vowel whereas b has 2. Therefore, they are not alike.
Notice that the vowel o is counted twice.
Constraints:
2 <= s.length <= 1000s.lengthis even.sconsists of uppercase and lowercase letters.
Solution
Code 1 (Rust)
impl Solution {
pub fn halves_are_alike(s: String) -> bool {
let k = s.len() / 2;
let s = s.as_bytes();
let mut count = 0;
for i in 0..k {
let (ch_a, ch_b) = (s[i], s[k+i]);
match ch_a {
b'a' | b'A' => count+=1,
b'e' | b'E' => count+=1,
b'i' | b'I' => count+=1,
b'o' | b'O' => count+=1,
b'u' | b'U' => count+=1,
_ => {},
}
match ch_b {
b'a' | b'A' => count-=1,
b'e' | b'E' => count-=1,
b'i' | b'I' => count-=1,
b'o' | b'O' => count-=1,
b'u' | b'U' => count-=1,
_ => {},
}
}
return count==0;
}
}
Code 2 (Rust)
Is there any efficient way to iterate characters?
1729. Find Followers Count
Description of the Problem
Table: Followers
+-------------+------+
| Column Name | Type |
+-------------+------+
| user_id | int |
| follower_id | int |
+-------------+------+
(user_id, follower_id) is the primary key (combination of columns with unique values) for this table.
This table contains the IDs of a user and a follower in a social media app where the follower follows the user.
Write a solution that will, for each user, return the number of followers.
Return the result table ordered by user_id in ascending order.
The result format is in the following example.
Example 1:
Input:
Followers table:
+---------+-------------+
| user_id | follower_id |
+---------+-------------+
| 0 | 1 |
| 1 | 0 |
| 2 | 0 |
| 2 | 1 |
+---------+-------------+
Output:
+---------+----------------+
| user_id | followers_count|
+---------+----------------+
| 0 | 1 |
| 1 | 1 |
| 2 | 2 |
+---------+----------------+
Explanation:
The followers of 0 are {1}
The followers of 1 are {0}
The followers of 2 are {0,1}
Solution
Tags: SQL
Code (MySQL)
-- Write your MySQL query statement below
SELECT user_id, COUNT(follower_id) AS followers_count
FROM Followers
GROUP BY user_id
ORDER BY user_id;
1731. The Number of Employees Which Report to Each Employee
Description of Problem
Table: Employees
+-------------+----------+
| Column Name | Type |
+-------------+----------+
| employee_id | int |
| name | varchar |
| reports_to | int |
| age | int |
+-------------+----------+
employee_id is the column with unique values for this table.
This table contains information about the employees and the id of the manager they report to. Some employees do not report to anyone (reports_to is null).
For this problem, we will consider a manager an employee who has at least 1 other employee reporting to them.
Write a solution to report the ids and the names of all managers, the number of employees who report directly to them, and the average age of the reports rounded to the nearest integer.
Return the result table ordered by employee_id.
The result format is in the following example.
Example 1:
Input:
Employees table:
+-------------+---------+------------+-----+
| employee_id | name | reports_to | age |
+-------------+---------+------------+-----+
| 9 | Hercy | null | 43 |
| 6 | Alice | 9 | 41 |
| 4 | Bob | 9 | 36 |
| 2 | Winston | null | 37 |
+-------------+---------+------------+-----+
Output:
+-------------+-------+---------------+-------------+
| employee_id | name | reports_count | average_age |
+-------------+-------+---------------+-------------+
| 9 | Hercy | 2 | 39 |
+-------------+-------+---------------+-------------+
Explanation: Hercy has 2 people report directly to him, Alice and Bob. Their average age is (41+36)/2 = 38.5, which is 39 after rounding it to the nearest integer.
Solution
Tags: SQL Grouping Aggregate Functions
Code (MySQL)
-- Write your MySQL query statement below
SELECT
e1.reports_to AS employee_id,
(SELECT e2.name FROM Employees e2 WHERE e2.employee_id = e1.reports_to ) AS name,
COUNT(1) AS reports_count,
ROUND(AVG(age),0) AS average_age
FROM Employees e1
GROUP BY reports_to
HAVING reports_to IS NOT NULL
ORDER BY e1.reports_to;
1732. Find the Highest Altitude
Description of Problem
There is a biker going on a road trip. The road trip consists of n + 1 points at different altitudes. The biker starts his trip on point 0 with altitude equal 0.
You are given an integer array gain of length n where gain[i] is the net gain in altitude between points i and i + 1 for all (0 <= i < n). Return the highest altitude of a point.
Example 1:
Input: gain = [-5,1,5,0,-7]
Output: 1
Explanation: The altitudes are [0,-5,-4,1,1,-6]. The highest is 1.
Example 2:
Input: gain = [-4,-3,-2,-1,4,3,2]
Output: 0
Explanation: The altitudes are [0,-4,-7,-9,-10,-6,-3,-1]. The highest is 0.
Constraints:
n == gain.length1 <= n <= 100-100 <= gain[i] <= 100
Solution
Code (Rust)
impl Solution {
pub fn largest_altitude(gain: Vec<i32>) -> i32 {
let mut altitude = 0;
let mut max = altitude;
for g in gain.into_iter(){
max = max.max(altitude);
altitude += g;
}
// remember the last element
return max.max(altitude);
}
}
Complexity
- n is length of
gain
Time Complexity
- \(T(n) = \Theta(n)\)
Auxiliary Space
- \(S(n) = O(1)\)
1741. Find Total Time Spent by Each Employee
Description of Problem
Table: Employees
+-------------+------+
| Column Name | Type |
+-------------+------+
| emp_id | int |
| event_day | date |
| in_time | int |
| out_time | int |
+-------------+------+
(emp_id, event_day, in_time) is the primary key (combinations of columns with unique values) of this table.
The table shows the employees' entries and exits in an office.
event_day is the day at which this event happened, in_time is the minute at which the employee entered the office, and out_time is the minute at which they left the office.
in_time and out_time are between 1 and 1440.
It is guaranteed that no two events on the same day intersect in time, and in_time < out_time.
Write a solution to calculate the total time in minutes spent by each employee on each day at the office. Note that within one day, an employee can enter and leave more than once. The time spent in the office for a single entry is out_time - in_time.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Employees table:
+--------+------------+---------+----------+
| emp_id | event_day | in_time | out_time |
+--------+------------+---------+----------+
| 1 | 2020-11-28 | 4 | 32 |
| 1 | 2020-11-28 | 55 | 200 |
| 1 | 2020-12-03 | 1 | 42 |
| 2 | 2020-11-28 | 3 | 33 |
| 2 | 2020-12-09 | 47 | 74 |
+--------+------------+---------+----------+
Output:
+------------+--------+------------+
| day | emp_id | total_time |
+------------+--------+------------+
| 2020-11-28 | 1 | 173 |
| 2020-11-28 | 2 | 30 |
| 2020-12-03 | 1 | 41 |
| 2020-12-09 | 2 | 27 |
+------------+--------+------------+
Explanation:
Employee 1 has three events: two on day 2020-11-28 with a total of (32 - 4) + (200 - 55) = 173, and one on day 2020-12-03 with a total of (42 - 1) = 41.
Employee 2 has two events: one on day 2020-11-28 with a total of (33 - 3) = 30, and one on day 2020-12-09 with a total of (74 - 47) = 27.
Solution
Tags: MySQL
Code (MySQL)
SELECT
event_day AS day,
emp_id,
SUM(out_time - in_time) AS total_time
FROM Employees
GROUP BY day, emp_id
1757. Recyclable and Low Fat Products
Description of the Problem
Table: Products
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| product_id | int |
| low_fats | enum |
| recyclable | enum |
+-------------+---------+
product_id is the primary key (column with unique values) for this table.
low_fats is an ENUM (category) of type ('Y', 'N') where 'Y' means this product is low fat and 'N' means it is not.
recyclable is an ENUM (category) of types ('Y', 'N') where 'Y' means this product is recyclable and 'N' means it is not.
Write a solution to find the ids of products that are both low fat and recyclable.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Products table:
+-------------+----------+------------+
| product_id | low_fats | recyclable |
+-------------+----------+------------+
| 0 | Y | N |
| 1 | Y | Y |
| 2 | N | Y |
| 3 | Y | Y |
| 4 | N | N |
+-------------+----------+------------+
Output:
+-------------+
| product_id |
+-------------+
| 1 |
| 3 |
+-------------+
Explanation: Only products 1 and 3 are both low fat and recyclable.
Solution
Tags: SQL
Code (MySQL)
# Write your MySQL query statement below
SELECT product_id
FROM Products
WHERE low_fats = 'Y' AND recyclable = 'Y';
1768. Merge Strings Alternately
Description of Problem
You are given two strings word1 and word2. Merge the strings by adding letters in alternating order, starting with word1. If a string is longer than the other, append the additional letters onto the end of the merged string.
Return the merged string.
Example 1:
Input: word1 = "abc", word2 = "pqr"
Output: "apbqcr"
Explanation: The merged string will be merged as so:
word1: a b c
word2: p q r
merged: a p b q c r
Example 2:
Input: word1 = "ab", word2 = "pqrs"
Output: "apbqrs"
Explanation: Notice that as word2 is longer, "rs" is appended to the end.
word1: a b
word2: p q r s
merged: a p b q r s
Example 3:
Input: word1 = "abcd", word2 = "pq"
Output: "apbqcd"
Explanation: Notice that as word1 is longer, "cd" is appended to the end.
word1: a b c d
word2: p q
merged: a p b q c d
Solution
Code (Rust)
impl Solution {
pub fn merge_alternately(word1: String, word2: String) -> String {
// Since `word1` and `word2` contains only English letters, we can act on &[u8] and Vec<u8>
let mut v = vec![];
let (w1, m, w2, n) = (word1.as_bytes(), word1.len(), word2.as_bytes(), word2.len());
let (mut b, mut i, mut j) = (false, 0, 0);
// Merging
while( i < m && j < n) {
match b {
false => {
v.push(w1[i]);
i+=1;
b = true;
},
true => {
v.push(w2[j]);
j+=1;
b = false;
}
}
}
// Appending remamining characters
while( i < m ) {
v.push(w1[i]);
i+=1;
}
// Appending remamining characters
while( j < n ) {
v.push(w2[j]);
j+=1;
}
return String::from_utf8(v).unwrap();
}
}
Complexity
- \(m\) is length of
word1 - \(n\) is length of
word2
Time Complexity
- \(T(m,n) = O(m+n) \)
Auxiliary Space
- \(S(m,n) = O(1) \)
- As output vector does not included in Auxiliary Space
1789. Primary Department for Each Employee
Description of Problem
Table: Employee
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| employee_id | int |
| department_id | int |
| primary_flag | varchar |
+---------------+---------+
(employee_id, department_id) is the primary key (combination of columns with unique values) for this table.
employee_id is the id of the employee.
department_id is the id of the department to which the employee belongs.
primary_flag is an ENUM (category) of type ('Y', 'N'). If the flag is 'Y', the department is the primary department for the employee. If the flag is 'N', the department is not the primary.
Employees can belong to multiple departments. When the employee joins other departments, they need to decide which department is their primary department. Note that when an employee belongs to only one department, their primary column is 'N'.
Write a solution to report all the employees with their primary department. For employees who belong to one department, report their only department.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Employee table:
+-------------+---------------+--------------+
| employee_id | department_id | primary_flag |
+-------------+---------------+--------------+
| 1 | 1 | N |
| 2 | 1 | Y |
| 2 | 2 | N |
| 3 | 3 | N |
| 4 | 2 | N |
| 4 | 3 | Y |
| 4 | 4 | N |
+-------------+---------------+--------------+
Output:
+-------------+---------------+
| employee_id | department_id |
+-------------+---------------+
| 1 | 1 |
| 2 | 1 |
| 3 | 3 |
| 4 | 3 |
+-------------+---------------+
Explanation:
- The Primary department for employee 1 is 1.
- The Primary department for employee 2 is 1.
- The Primary department for employee 3 is 3.
- The Primary department for employee 4 is 3.
Solution
Tags: SQL Joins
Code 1 (MySQL)
SELECT e1.employee_id, e1.department_id
FROM Employee e1
WHERE NOT EXISTS (
SELECT 1
FROM Employee e
WHERE e.employee_id = e1.employee_id
AND primary_flag = 'Y'
)
AND 1 = (
SELECT COUNT(1)
FROM Employee e
WHERE e.employee_id = e1.employee_id
AND primary_flag = 'N'
)
UNION
SELECT e2.employee_id, e2.department_id
FROM Employee e2
WHERE e2.primary_flag = 'Y'
;
Code 2 (MySQL) - Optimised
SELECT e1.employee_id, e1.department_id
FROM Employee e1
GROUP BY e1.employee_id
HAVING COUNT(e1.department_id) = 1
UNION
SELECT e2.employee_id, e2.department_id
FROM Employee e2
WHERE e2.primary_flag = 'Y'
;
1795. Rearrange Products Table
Description of Problem
Table: Products
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| product_id | int |
| store1 | int |
| store2 | int |
| store3 | int |
+-------------+---------+
product_id is the primary key (column with unique values) for this table.
Each row in this table indicates the product's price in 3 different stores: store1, store2, and store3.
If the product is not available in a store, the price will be null in that store's column.
Write a solution to rearrange the Products table so that each row has (product_id, store, price). If a product is not available in a store, do not include a row with that product_id and store combination in the result table.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Products table:
+------------+--------+--------+--------+
| product_id | store1 | store2 | store3 |
+------------+--------+--------+--------+
| 0 | 95 | 100 | 105 |
| 1 | 70 | null | 80 |
+------------+--------+--------+--------+
Output:
+------------+--------+-------+
| product_id | store | price |
+------------+--------+-------+
| 0 | store1 | 95 |
| 0 | store2 | 100 |
| 0 | store3 | 105 |
| 1 | store1 | 70 |
| 1 | store3 | 80 |
+------------+--------+-------+
Explanation:
Product 0 is available in all three stores with prices 95, 100, and 105 respectively.
Product 1 is available in store1 with price 70 and store3 with price 80. The product is not available in store2.
Solution
Tags: MySQL
Explanation
Code
SELECT product_id, 'store1' AS 'store', store1 AS price
FROM Products
WHERE store1 IS NOT NULL
UNION
SELECT product_id, 'store2' AS 'store', store2 AS price
FROM Products
WHERE store2 IS NOT NULL
UNION
SELECT product_id, 'store3' AS 'store', store3 AS price
FROM Products
WHERE store3 IS NOT NULL
1822. Sign of the Product of an Array
Description of the Problem
There is a function signFunc(x) that returns:
1ifxis positive.-1ifxis negative.0ifxis equal to0. You are given an integer arraynums. Letproductbe the product of all values in the arraynums.
Return signFunc(product).
Example 1:
Input: nums = [-1,-2,-3,-4,3,2,1]
Output: 1
Explanation: The product of all values in the array is 144, and signFunc(144) = 1
Example 2:
Input: nums = [1,5,0,2,-3]
Output: 0
Explanation: The product of all values in the array is 0, and signFunc(0) = 0
Example 3:
Input: nums = [-1,1,-1,1,-1]
Output: -1
Explanation: The product of all values in the array is -1, and signFunc(-1) = -1
Constraints:
1 <= nums.length <= 1000-100 <= nums[i] <= 100
Solution
Code (Rust)
impl Solution {
pub fn array_sign(nums: Vec<i32>) -> i32 {
nums
.into_iter()
.map( |a| if a < 0 { -1 } else if a > 0 { 1 } else { 0 } )
.reduce(|a, b| a * b)
.unwrap()
}
}
Complexity
- n is the number of elements in the array
Time complexity:
- \( T(n) = \Theta(n) \)
Auxiliary Space:
- \( S(n) = O(1) \)
1873. Calculate Special Bonus
Description of Problem
Table: Employees
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| employee_id | int |
| name | varchar |
| salary | int |
+-------------+---------+
employee_id is the primary key (column with unique values) for this table.
Each row of this table indicates the employee ID, employee name, and salary.
Write a solution to calculate the bonus of each employee. The bonus of an employee is 100% of their salary if the ID of the employee is an odd number and the employee's name does not start with the character 'M'. The bonus of an employee is 0 otherwise.
Return the result table ordered by employee_id.
The result format is in the following example.
Example 1:
Input:
Employees table:
+-------------+---------+--------+
| employee_id | name | salary |
+-------------+---------+--------+
| 2 | Meir | 3000 |
| 3 | Michael | 3800 |
| 7 | Addilyn | 7400 |
| 8 | Juan | 6100 |
| 9 | Kannon | 7700 |
+-------------+---------+--------+
Output:
+-------------+-------+
| employee_id | bonus |
+-------------+-------+
| 2 | 0 |
| 3 | 0 |
| 7 | 7400 |
| 8 | 0 |
| 9 | 7700 |
+-------------+-------+
Explanation:
The employees with IDs 2 and 8 get 0 bonus because they have an even employee_id.
The employee with ID 3 gets 0 bonus because their name starts with 'M'.
The rest of the employees get a 100% bonus.
Solution
Tags: SQL
Code (MySQL)
# Write your MySQL query statement below
SELECT
employee_id,
CASE
WHEN MOD(employee_id, 2) = 0 OR name LIKE 'M%' THEN 0
ELSE salary
END AS bonus
FROM Employees
ORDER BY employee_id
1890. The Latest Login in 2020
Description of Problem
Table: Logins
+----------------+----------+
| Column Name | Type |
+----------------+----------+
| user_id | int |
| time_stamp | datetime |
+----------------+----------+
(user_id, time_stamp) is the primary key (combination of columns with unique values) for this table.
Each row contains information about the login time for the user with ID user_id.
Write a solution to report the latest login for all users in the year 2020. Do not include the users who did not login in 2020.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Logins table:
+---------+---------------------+
| user_id | time_stamp |
+---------+---------------------+
| 6 | 2020-06-30 15:06:07 |
| 6 | 2021-04-21 14:06:06 |
| 6 | 2019-03-07 00:18:15 |
| 8 | 2020-02-01 05:10:53 |
| 8 | 2020-12-30 00:46:50 |
| 2 | 2020-01-16 02:49:50 |
| 2 | 2019-08-25 07:59:08 |
| 14 | 2019-07-14 09:00:00 |
| 14 | 2021-01-06 11:59:59 |
+---------+---------------------+
Output:
+---------+---------------------+
| user_id | last_stamp |
+---------+---------------------+
| 6 | 2020-06-30 15:06:07 |
| 8 | 2020-12-30 00:46:50 |
| 2 | 2020-01-16 02:49:50 |
+---------+---------------------+
Explanation:
User 6 logged into their account 3 times but only once in 2020, so we include this login in the result table.
User 8 logged into their account 2 times in 2020, once in February and once in December. We include only the latest one (December) in the result table.
User 2 logged into their account 2 times but only once in 2020, so we include this login in the result table.
User 14 did not login in 2020, so we do not include them in the result table.
Solution
Tags: SQL
Code (MySQL)
# Write your MySQL query statement below
SELECT user_id, MAX(time_stamp) AS last_stamp
FROM Logins
WHERE YEAR(time_stamp) = 2020
GROUP BY user_id;
1929. Concatenation of Array
Description of the Problem
Given an integer array nums of length n, you want to create an array ans of length 2n where ans[i] == nums[i] and ans[i + n] == nums[i] for 0 <= i < n (0-indexed).
Specifically, ans is the concatenation of two nums arrays.
Return the array ans.
Example 1:
Input: nums = [1,2,1]
Output: [1,2,1,1,2,1]
Explanation: The array ans is formed as follows:
- ans = [nums[0],nums[1],nums[2],nums[0],nums[1],nums[2]]
- ans = [1,2,1,1,2,1]
Example 2:
Input: nums = [1,3,2,1]
Output: [1,3,2,1,1,3,2,1]
Explanation: The array ans is formed as follows:
- ans = [nums[0],nums[1],nums[2],nums[3],nums[0],nums[1],nums[2],nums[3]]
- ans = [1,3,2,1,1,3,2,1]
Constraints:
n == nums.length1 <= n <= 10001 <= nums[i] <= 1000
Solution
Code(Rust)
impl Solution {
pub fn get_concatenation(nums: Vec<i32>) -> Vec<i32> {
let mut res = nums.clone();
for n in nums{
res.push(n);
}
return res;
}
}
Complexity
- n is the number of elements in the array
Time complexity:
- \( T(n) = \Theta(n) \)
Auxiliary Space:
- \( S(n) = O(n) \)
1965. Employees With Missing Information
Description of Problem
Table: Employees
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| employee_id | int |
| name | varchar |
+-------------+---------+
employee_id is the column with unique values for this table.
Each row of this table indicates the name of the employee whose ID is employee_id.
Table: Salaries
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| employee_id | int |
| salary | int |
+-------------+---------+
employee_id is the column with unique values for this table.
Each row of this table indicates the salary of the employee whose ID is employee_id.
Write a solution to report the IDs of all the employees with missing information. The information of an employee is missing if:
- The employee's name is missing, or
- The employee's salary is missing.
Return the result table ordered by
employee_idin ascending order.
The result format is in the following example.
Example 1:
Input:
Employees table:
+-------------+----------+
| employee_id | name |
+-------------+----------+
| 2 | Crew |
| 4 | Haven |
| 5 | Kristian |
+-------------+----------+
Salaries table:
+-------------+--------+
| employee_id | salary |
+-------------+--------+
| 5 | 76071 |
| 1 | 22517 |
| 4 | 63539 |
+-------------+--------+
Output:
+-------------+
| employee_id |
+-------------+
| 1 |
| 2 |
+-------------+
Explanation:
Employees 1, 2, 4, and 5 are working at this company.
The name of employee 1 is missing.
The salary of employee 2 is missing.
Solution
Tags: SQL Set Operations
Explanation
Perform Set Symmetric Difference between Employees and Salaries tables.
Code
WITH t AS (
SELECT left_table.employee_id
FROM Employees left_table
WHERE NOT EXISTS (
SELECT 'X'
FROM Salaries right_table
WHERE right_table.employee_id = left_table.employee_id
)
UNION
SELECT right_table.employee_id
FROM Salaries right_table
WHERE NOT EXISTS (
SELECT 'X'
FROM Employees left_table
WHERE left_table.employee_id = right_table.employee_id
)
)
SELECT *
FROM t
ORDER by employee_id;
1967. Number of Strings That Appear as Substrings in Word
Description of Problem
Given an array of strings patterns and a string word, return the number of strings in patterns that exist as a substring in word.
A substring is a contiguous sequence of characters within a string.
Example 1:
Input: patterns = ["a","abc","bc","d"], word = "abc"
Output: 3
Explanation:
- "a" appears as a substring in "abc".
- "abc" appears as a substring in "abc".
- "bc" appears as a substring in "abc".
- "d" does not appear as a substring in "abc".
3 of the strings in patterns appear as a substring in word.
Example 2:
Input: patterns = ["a","b","c"], word = "aaaaabbbbb"
Output: 2
Explanation:
- "a" appears as a substring in "aaaaabbbbb".
- "b" appears as a substring in "aaaaabbbbb".
- "c" does not appear as a substring in "aaaaabbbbb".
2 of the strings in patterns appear as a substring in word.
Example 3:
Input: patterns = ["a","a","a"], word = "ab"
Output: 3
Explanation: Each of the patterns appears as a substring in word "ab".
Constraints:
1 <= patterns.length <= 1001 <= patterns[i].length <= 1001 <= word.length <= 100patterns[i]andwordconsist of lowercase English letters.
Solution
Code (Rust)
impl Solution {
pub fn num_of_strings (patterns: Vec<String>, word: String) -> i32 {
let mut count = 0;
for p in patterns.iter() {
count += if word.contains(p) { 1 } else { 0 };
}
return count;
}
}
1978. Employees Whose Manager Left the Company
Description of Problem
Table: Employees
+-------------+----------+
| Column Name | Type |
+-------------+----------+
| employee_id | int |
| name | varchar |
| manager_id | int |
| salary | int |
+-------------+----------+
In SQL, employee_id is the primary key for this table.
This table contains information about the employees, their salary, and the ID of their manager. Some employees do not have a manager (manager_id is null).
Find the IDs of the employees whose salary is strictly less than $30000 and whose manager left the company. When a manager leaves the company, their information is deleted from the Employees table, but the reports still have their manager_id set to the manager that left.
Return the result table ordered by employee_id.
The result format is in the following example.
Example 1:
Input:
Employees table:
+-------------+-----------+------------+--------+
| employee_id | name | manager_id | salary |
+-------------+-----------+------------+--------+
| 3 | Mila | 9 | 60301 |
| 12 | Antonella | null | 31000 |
| 13 | Emery | null | 67084 |
| 1 | Kalel | 11 | 21241 |
| 9 | Mikaela | null | 50937 |
| 11 | Joziah | 6 | 28485 |
+-------------+-----------+------------+--------+
Output:
+-------------+
| employee_id |
+-------------+
| 11 |
+-------------+
Explanation:
The employees with a salary less than $30000 are 1 (Kalel) and 11 (Joziah).
Kalel's manager is employee 11, who is still in the company (Joziah).
Joziah's manager is employee 6, who left the company because there is no row for employee 6 as it was deleted.
Solution
Tags: SQL Subquery
The problem has relatively low passing rate (~47%)
# Write your MySQL query statement below
SELECT employee_id
FROM Employees e1
WHERE e1.salary < 30000
AND e1.manager_id IS NOT NULL
AND NOT EXISTS (
SELECT 1
FROM Employees e2
WHERE e2.employee_id = e1.manager_id
)
ORDER BY employee_id;
1991. Find the Middle Index in Array
Description of Problem
Given a 0-indexed integer array nums, find the leftmost middleIndex (i.e., the smallest amongst all the possible ones).
A middleIndex is an index where nums[0] + nums[1] + ... + nums[middleIndex-1] == nums[middleIndex+1] + nums[middleIndex+2] + ... + nums[nums.length-1].
If middleIndex == 0, the left side sum is considered to be 0. Similarly, if middleIndex == nums.length - 1, the right side sum is considered to be 0.
Return the leftmost middleIndex that satisfies the condition, or -1 if there is no such index.
Example 1:
Input: nums = [2,3,-1,8,4]
Output: 3
Explanation: The sum of the numbers before index 3 is: 2 + 3 + -1 = 4
The sum of the numbers after index 3 is: 4 = 4
Example 2:
Input: nums = [1,-1,4]
Output: 2
Explanation: The sum of the numbers before index 2 is: 1 + -1 = 0
The sum of the numbers after index 2 is: 0
Example 3:
Input: nums = [2,5]
Output: -1
Explanation: There is no valid middleIndex.
Constraints:
1 <= nums.length <= 100-1000 <= nums[i] <= 1000
Note: This question is the same as 724: (https://leetcode.com/problems/find-pivot-index/)[https://leetcode.com/problems/find-pivot-index/]
Solution
Tags: Prefix Sum
Explanation
Please see 724. Find Pivot Index
Code (Rust)
impl Solution {
pub fn find_middle_index(nums: Vec<i32>) -> i32 {
let n = nums.len();
let sum = nums.iter().sum::<i32>();
let mut prefix_sum = 0;
for i in 0..n {
if nums[i] + 2 * prefix_sum == sum {
return i as i32;
}
prefix_sum += nums[i];
}
return -1;
}
}
Complexity
- \(n\) is length of nums.
Time Complexity
- \(T(n)=\Theta(n)\)
Auxiliary Space
- \(S(n)=O(1)\)
2215. Find the Difference of Two Arrays
Description of Problem
Given two 0-indexed integer arrays nums1 and nums2, return a list answer of size 2 where:
answer[0]is a list of all distinct integers innums1which are not present innums2.answer[1]is a list of all distinct integers innums2which are not present innums1.
Note that the integers in the lists may be returned in any order.
Example 1:
Input: nums1 = [1,2,3], nums2 = [2,4,6]
Output: [[1,3],[4,6]]
Explanation:
For nums1, nums1[1] = 2 is present at index 0 of nums2, whereas nums1[0] = 1 and nums1[2] = 3 are not present in nums2. Therefore, answer[0] = [1,3].
For nums2, nums2[0] = 2 is present at index 1 of nums1, whereas nums2[1] = 4 and nums2[2] = 6 are not present in nums2. Therefore, answer[1] = [4,6].
Example 2:
Input: nums1 = [1,2,3,3], nums2 = [1,1,2,2]
Output: [[3],[]]
Explanation:
For nums1, nums1[2] and nums1[3] are not present in nums2. Since nums1[2] == nums1[3], their value is only included once and answer[0] = [3].
Every integer in nums2 is present in nums1. Therefore, answer[1] = [].
Constraints:
1 <= nums1.length, nums2.length <= 1000-1000 <= nums1[i], nums2[i] <= 1000
Code (Rust) - Use Rust built-in functions
impl Solution {
pub fn find_difference(nums1: Vec<i32>, nums2: Vec<i32>) -> Vec<Vec<i32>> {
use std::collections::HashSet;
use std::iter::FromIterator;
let a : HashSet<_> = nums1.into_iter().collect();
let b : HashSet<_> = nums2.into_iter().collect();
let left_diff: Vec<_> = a.difference(&b).map(|&x| x).collect();
let rigth_diff: Vec<_> = b.difference(&a).map(|&x| x).collect();
return vec![left_diff, rigth_diff];
}
}
Complexity
- \(m\) is
nums1.len() - \(n\) is
nums2.len()
Time Complexity
- \(T(m,n) = O(m+n)\)
- Create HashSet for both arrays.
- Create left-difference list and right-difference list
Auxiliary Space
- \(S(m,n) = O(m+n)\)
- Create HashSet for both arrays.
2235. Add Two Integers
Description of Problem
Given two integers num1 and num2, return the sum of the two integers.
Example 1:
Input: num1 = 12, num2 = 5
Output: 17
Explanation: num1 is 12, num2 is 5, and their sum is 12 + 5 = 17, so 17 is returned.
Example 2:
Input: num1 = -10, num2 = 4
Output: -6
Explanation: num1 + num2 = -6, so -6 is returned.
Constraints:
-100 <= num1, num2 <= 100
Solution
Code
impl Solution {
pub fn sum(num1: i32, num2: i32) -> i32 {
return num1+num2;
}
}
2331. Evaluate Boolean Binary Tree
Description
You are given the root of a full binary tree with the following properties:
- Leaf nodes have either the value
0or1, where0representsFalseand1representsTrue. - Non-leaf nodes have either the value
2or3, where2represents the booleanORand3represents the booleanAND.
The evaluation of a node is as follows:
- If the node is a leaf node, the evaluation is the value of the node, i.e.
TrueorFalse. - Otherwise, evaluate the node's two children and apply the boolean operation of its value with the children's evaluations.
Return the boolean result of evaluating the root node.
A full binary tree is a binary tree where each node has either 0 or 2 children.
A leaf node is a node that has zero children.
Example 1:
Input: root = [2,1,3,null,null,0,1]
Output: true
Explanation: The above diagram illustrates the evaluation process.
The AND node evaluates to False AND True = False.
The OR node evaluates to True OR False = True.
The root node evaluates to True, so we return true.
Example 2:
Input: root = [0]
Output: false
Explanation: The root node is a leaf node and it evaluates to false, so we return false.
Constraints:
- The number of nodes in the tree is in the range
[1, 1000]. 0 <= Node.val <= 3- Every node has either
0or2children. - Leaf nodes have a value of
0or1. - Non-leaf nodes have a value of
2or3.
Solution
Code (Rust)
// Definition for a binary tree node.
// #[derive(Debug, PartialEq, Eq)]
// pub struct TreeNode {
// pub val: i32,
// pub left: Option<Rc<RefCell<TreeNode>>>,
// pub right: Option<Rc<RefCell<TreeNode>>>,
// }
//
// impl TreeNode {
// #[inline]
// pub fn new(val: i32) -> Self {
// TreeNode {
// val,
// left: None,
// right: None
// }
// }
// }
use std::rc::Rc;
use std::cell::RefCell;
impl Solution {
pub fn evaluate_tree(root: Option<Rc<RefCell<TreeNode>>>) -> bool {
if root.is_some() {
let root = root.unwrap();
let root = root.borrow();
let v = root.val;
return match v{
0 => false,
1 => true,
2 => Solution::evaluate_tree( root.left.clone() ) ||
Solution::evaluate_tree( root.right.clone() ),
3 => Solution::evaluate_tree( root.left.clone() ) &&
Solution::evaluate_tree( root.right.clone() ),
_ => false,
}
}
else{
return false;
}
}
}
Code (C++)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
bool evaluateTree(TreeNode* root) {
int val = root->val;
if ( val == 0 )
return false;
else if (val == 1)
return true;
else if (val == 2)
return evaluateTree(root->left) || evaluateTree(root->right);
else
return evaluateTree(root->left) && evaluateTree(root->right);
}
};
Complexity
Time complexity: (n is the number of nodes in the tree; h is the height of the tree)
- \( T(n) = O(n) \)
Auxiliary Space:
- \( S(n) = O(h) \)
2356. Number of Unique Subjects Taught by Each Teacher
Description of the Problem
Table: Teacher
+-------------+------+
| Column Name | Type |
+-------------+------+
| teacher_id | int |
| subject_id | int |
| dept_id | int |
+-------------+------+
(subject_id, dept_id) is the primary key (combinations of columns with unique values) of this table.
Each row in this table indicates that the teacher with teacher_id teaches the subject subject_id in the department dept_id.
Write a solution to calculate the number of unique subjects each teacher teaches in the university.
Return the result table in any order.
The result format is shown in the following example.
Example 1:
Input:
Teacher table:
+------------+------------+---------+
| teacher_id | subject_id | dept_id |
+------------+------------+---------+
| 1 | 2 | 3 |
| 1 | 2 | 4 |
| 1 | 3 | 3 |
| 2 | 1 | 1 |
| 2 | 2 | 1 |
| 2 | 3 | 1 |
| 2 | 4 | 1 |
+------------+------------+---------+
Output:
+------------+-----+
| teacher_id | cnt |
+------------+-----+
| 1 | 2 |
| 2 | 4 |
+------------+-----+
Explanation:
Teacher 1:
- They teach subject 2 in departments 3 and 4.
- They teach subject 3 in department 3.
Teacher 2:
- They teach subject 1 in department 1.
- They teach subject 2 in department 1.
- They teach subject 3 in department 1.
- They teach subject 4 in department 1.
Solution
Code (MySQL)
-- Write your MySQL query statement below
SELECT teacher_id, COUNT(DISTINCT subject_id) AS cnt
FROM Teacher
GROUP BY teacher_id;
2703. Return Length of Arguments Passed
Description of Problem
Write a function argumentsLength that returns the count of arguments passed to it.
Example 1:
Input: args = [5]
Output: 1
Explanation:
argumentsLength(5); // 1
One value was passed to the function so it should return 1.
Example 2:
Input: args = [{}, null, "3"]
Output: 3
Explanation:
argumentsLength({}, null, "3"); // 3
Three values were passed to the function so it should return 3.
Constraints:
argsis a valid JSON array0 <= args.length <= 100
Solution
Tags: JavaScript
Code (TypeScript)
type JSONValue = null | boolean | number | string | JSONValue[] | { [key: string]: JSONValue };
function argumentsLength(...args: JSONValue[]): number {
return args.length;
};
/**
* argumentsLength(1, 2, 3); // 3
*/
2723. Add Two Promises
Description of Problems
Given two promises promise1 and promise2, return a new promise. promise1 and promise2 will both resolve with a number. The returned promise should resolve with the sum of the two numbers.
Example 1:
Input:
promise1 = new Promise(resolve => setTimeout(() => resolve(2), 20)),
promise2 = new Promise(resolve => setTimeout(() => resolve(5), 60))
Output: 7
Explanation: The two input promises resolve with the values of 2 and 5 respectively. The returned promise should resolve with a value of 2 + 5 = 7. The time the returned promise resolves is not judged for this problem.
Example 2:
Input:
promise1 = new Promise(resolve => setTimeout(() => resolve(10), 50)),
promise2 = new Promise(resolve => setTimeout(() => resolve(-12), 30))
Output: -2
Explanation: The two input promises resolve with the values of 10 and -12 respectively. The returned promise should resolve with a value of 10 + -12 = -2.
Constraints:
promise1andpromise2are promises that resolve with a number
Solution
Tags: JavaScript
Code (TypeScript)
type P = Promise<number>
async function addTwoPromises(promise1: P, promise2: P): P {
return promise1.then(
v1 => promise2.then( v2 => v1+v2 )
);
};
/**
* addTwoPromises(Promise.resolve(2), Promise.resolve(2))
* .then(console.log); // 4
*/
2. Add Two Numbers
Description of the Problem
You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order, and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
Example 1:
Input: l1 = [2,4,3], l2 = [5,6,4]
Output: [7,0,8]
Explanation: 342 + 465 = 807.
Example 2:
Input: l1 = [0], l2 = [0]
Output: [0]
Example 3:
Input: l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
Output: [8,9,9,9,0,0,0,1]
Constraints:
- The number of nodes in each linked list is in the range
[1, 100]. 0 <= Node.val <= 9- It is guaranteed that the list represents a number that does not have leading zeros.
Solution
Code (Rust)
// Definition for singly-linked list.
// #[derive(PartialEq, Eq, Clone, Debug)]
// pub struct ListNode {
// pub val: i32,
// pub next: Option<Box<ListNode>>
// }
//
// impl ListNode {
// #[inline]
// fn new(val: i32) -> Self {
// ListNode {
// next: None,
// val
// }
// }
// }
impl Solution {
pub fn reverse_list(head: Option<Box<ListNode>>) -> Option<Box<ListNode>> {
let mut curr = head;
let mut prev = None;
while let Some(mut node) = curr.take() {
curr = node.next;
node.next = prev;
prev = Some(node);
}
return prev;
}
pub fn add_two_numbers(l1: Option<Box<ListNode>>, l2: Option<Box<ListNode>>)
-> Option<Box<ListNode>> {
let mut carry : i32 = 0;
let mut l1 = l1;
let mut l2 = l2;
let mut curr = Some(Box::new(ListNode::new(0))); // Dummy head
while l1.is_some() || l2.is_some() || carry > 0
{
let mut sum = carry;
if let Some(node) = l1 {
sum += node.val;
l1 = node.next;
}
if let Some(node) = l2 {
sum += node.val;
l2 = node.next;
}
let mut node = ListNode::new(sum % 10);
node.next = curr;
curr = Some(Box::new(node));
carry = sum / 10;
}
curr = Solution::reverse_list(curr);
if let Some(node) = curr {
curr = node.next;
}
return curr;
}
}
Code (Java)
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode result = new ListNode(0); // Sentinel node
ListNode current = result;
int carry = 0;
while (l1 != null || l2 != null || carry > 0) {
int sum = carry;
if (l1 != null){
sum += l1.val;
l1 = l1.next;
}
if (l2 != null){
sum += l2.val;
l2 = l2.next;
}
carry = sum / 10;
current.next = new ListNode(sum % 10);
current = current.next;
}
return result.next;
}
}
Code (C++)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
ListNode * dummyHead = new ListNode();
ListNode * curr = dummyHead;
int carry = 0;
while( l1 != nullptr || l2 != nullptr || carry > 0){
int val =
(l1 != nullptr ? l1->val : 0) +
(l2 != nullptr ? l2->val : 0) +
carry;
carry = val >= 10 ? 1 : 0;
curr->next = new ListNode( val % 10 );
curr = curr->next;
l1 = (l1 == nullptr) ? nullptr : l1->next;
l2 = (l2 == nullptr) ? nullptr : l2->next;
}
return dummyHead->next;
}
};
Complexity (m is the length of list1 and n is the length of list2)
Time complexity:
- \(O(\max(m,n)+1)\)
Auxiliary Space:
- \( O(1) \)
3. Longest Substring Without Repeating Characters
Description of the Problem
Given a string s, find the length of the longest substring without repeating characters.
Example 1:
Input: s = "abcabcbb"
Output: 3
Explanation: The answer is "abc", with the length of 3.
Example 2:
Input: s = "bbbbb"
Output: 1
Explanation: The answer is "b", with the length of 1.
Example 3:
Input: s = "pwwkew"
Output: 3
Explanation: The answer is "wke", with the length of 3.
Notice that the answer must be a substring, "pwke" is a subsequence and not a substring.
Constraints:
- \(0 <= s.length <= 5 * 10^4\)
- s consists of English letters, digits, symbols and spaces.
Solution - Sliding Window
Tags: Sliding Window
Explanation
Keep expanding our sliding window to find all substring without repeating character.
If new appended character is repeated, trim the current substring and append the new character.
Suppose before an iteration we have a substring without repeating character AcB where Capital letters represent may-be empty substrings and non-capital letter represents 1 character.
If we meet new character d which is different from c, it is fine. Just append to the substring to form a new
Otherwise, if c is the new character, then trim Ac and append c. New Substring becomes Bc which is a valid substring.
The above reasoning show that the algorithm must scan all longest possible valid substrings. The remaining work is to record the longest one.
Code (Rust)
impl Solution {
pub fn length_of_longest_substring(s: String) -> i32 {
// Sliding window for longest substring, j is exclusive
let (mut longest_i, mut longest_j) : (usize, usize) = (0,0);
// Sliding window for current substring, j is exclusive
let (mut i, mut j) : (usize, usize) = (0,0);
for (k, c) in s.chars().enumerate() {
// Find 1st index of char c in current substring (&s[i..j])
// IF new appended character c appear in current substring,
// i.e. substring has the form of AcBc where current substring consists of substring A, B and character c,
// THEN trim is, such that it becomes Bc
if let Some(index) = (&s[i..j]).find(c){
i += index + 1;
}
j = k + 1; // the end of the window move right by 1
// IF the current window size is larger, THEN update.
if j - i > longest_j - longest_i {
longest_i = i;
longest_j = j;
}
}
return (longest_j - longest_i) as i32;
}
}
Code (Java)
class Solution {
public int lengthOfLongestSubstring(String s) {
if ( s== null || s.isEmpty() ) return 0;
int start = 0; int end =1;
int max = 1;
while( end < s.length() ){
String subString = s.substring(start, end);
int indexOfChar = (int) (subString.indexOf(s.charAt(end)));
if (indexOfChar >= 0){
start = start + indexOfChar + 1;
}
end++;
max = max < end - start ? end - start : max;
}
return max;
}
}
Complexity (\(n\) is length of the string)
Time complexity:**
- Worst case: \( T(n) = \mathcal{\Theta}(n^2) \)
- String contains no repeating characters
- Average case: \( T(n) = O(n) \)
- (see Further Discussion)
- Best case: \( T(n) = \mathcal{\Theta}(n) \)
- String repeats same character
Auxiliary Space:**
- \( S(n) = O(1) \)
- Depends on implementation, Rust can achieve \( O(1) \)
Further Discussion
Average Time Complexity for the algorithm
Lemma: The algorithm run in \( O(n+X) \) where n is length of the string and X is number of comparison.
Proof: We have n iterations and each iteration performs certain number of characters comparison to find first index of the same character.
Theorem: The expected number of comparisons is \( O(n) \)
Proof:
Assume \( M \) is the number of characters of the program choose to form a string and each character is equally likely to be chosen independently.
Let \( X_{ij} = \unicode{x1D7D9} \text{ { i-th character is compared to j-th character } } \)
Consider a sequence of characters \( c_i c_{i+1} c_{i+2} ... c_{j-1} \) and a character \( c_j \) in a loop, \( c_i \) and \(c_j\) compares each other if-and-only-if the sequence of characters does not contains repeating characters. Otherwise the substring will be trimmed by our algorithm before the current loop.
For instance, consider a substring abaabcd, 1st a never compare with 2nd b, c, d since there are repeating characters between these pairs of characters (1st a and 2nd b, 1st a and c, 1st a and d).
The probability of \( c_i c_{i+1} c_{i+2} ... c_{j-1} \) does not contain repeating characters, according to formula of birthday paradox, is \(\frac{M!}{M^{(j-i)} (M - (j - i))! }\)
The total number of comparison \(\mathbb{E}[X] = \mathbb{E} \left [ \sum_{i = 0}^{n - 2} \sum_{j = i+1}^{n - 1} X_{ij} \right ] = \sum_{i = 0}^{n - 2} \sum_{j = i+1}^{n - 1} \mathbb{E}[ X_{ij} ] \)
\(= \sum_{i = 0}^{n - 2} \sum_{j = i+1}^{n - 1} \frac{M!}{M^{(j-i)} (M - (j - i))! } \)
\(= \sum_{i = 0}^{n - 2} \sum_{ k = 1}^{n - 1 - i} \frac{M!}{M^{k} (M - k)! } \)
\( \le \sum_{i = 0}^{n - 2} \sum_{k = 1}^{M} \frac{M!}{M^{k} (M - k)! } \)
\(\because\) When \(n \ge M \), the chance of substring without repeating characters becomes zero
\( \le \sum_{i = 0}^{n - 2} \int_{0}^{M} e^{ - x^2 / 2M } dx \) \( \ \because \) Approximation of the "birthday formula"
\( = \sum_{i = 0}^{n - 2} \frac{\sqrt{M\pi}}{\sqrt{2}} \ erf(\sqrt{\frac{M}{2}}) \)
\( \approx (n-1) 12.21 \) \( \ \because \) In ASCII table, dec32 to dec126 are charcters can be type in keyboard
\( = O(n) \)
Interpretation: Seldom do two characters compare each other since when the distance between two characters becomes larger, the chance of the characters between them contains no repeating characters becomes smaller.
Corollary: The average running time of the algorithm is \(O(n)\)
Proof: Followed by the lemma and the theorem.
6. Zigzag Conversion
Description of the Problem
The string "PAYPALISHIRING" is written in a zigzag pattern on a given number of rows like this: (you may want to display this pattern in a fixed font for better legibility)
A P L S I I G
Y I R
And then read line by line: "PAHNAPLSIIGYIR"
Write the code that will take a string and make this conversion given a number of rows:
string convert(string s, int numRows);
Example 1:
Input: s = "PAYPALISHIRING", numRows = 3
Output: "PAHNAPLSIIGYIR"
Example 2:
Input: s = "PAYPALISHIRING", numRows = 4
Output: "PINALSIGYAHRPI"
Explanation:
P I N
A L S I G
Y A H R
P I
Example 3:
Input: s = "A", numRows = 1
Output: "A"
Constraints:
1 <= s.length <= 1000sconsists of English letters (lower-case and upper-case),','and'.'.1 <= numRows <= 1000
Solution
Explanation
The solution is less intutive. Consider the following example: \[ \begin{matrix} x_0 & & & & & x_{10} & & & & & x_{20} \\ x_1 & & & & x_9 & x_{11} & & & & x_{19} & x_{21} \\ x_2 & & & x_8 & & x_{12} & & & x_{18} & & . \\ x_3 & & x_7 & & & x_{13} & & x_{17} & & & . \\ x_4 & x_6 & & & & x_{14} & x_{16} & & & & . \\ x_5 & & & & & x_{15} & & & & & . \\ \end{matrix} \]
Without consider extra characters of each row, the interval of index of two consecutive characters in a row is 2 * (num_rows - 1) (e.g. [x_0, x_10, x_20] and [x_1, x_11, x_21]).
\[ \begin{matrix} x_0 & & & & & x_{10} & & & & & x_{20} \\ x_1 & & & & \_ & x_{11} & & & & \_ & x_{21} \\ x_2 & & & \_ & & x_{12} & & & \_ & & . \\ x_3 & & \_ & & & x_{13} & & \_ & & & . \\ x_4 & \_ & & & & x_{14} & \_ & & & & . \\ x_5 & & & & & x_{15} & & & & & . \\ \end{matrix} \]
Then, consider the extra characters in the middle rows, the index of these characters are (offset - r) where offset is the interval multiplied by an integer k (i.e. interval * k), r is index of the row (i.e. 0 to n-1).
\[ \begin{matrix} x_0 & & & & & x_{10} & & & & & x_{20} \\ x_1 & & & & x_{10-1} & x_{11} & & & & x_{20-1} & x_{21} \\ x_2 & & & x_{10-2} & & x_{12} & & & x_{20-2} & & . \\ x_3 & & x_{10-3} & & & x_{13} & & x_{20-3} & & & . \\ x_4 & x_{10-4} & & & & x_{14} & x_{20-4} & & & & . \\ x_5 & & & & & x_{15} & & & & & . \\ \end{matrix} \]
Now, the solution is to append characters according to row number and index.
Code (Rust)
impl Solution {
pub fn convert(s: String, num_rows: i32) -> String {
let num_rows = num_rows as usize;
let n = s.len();
if num_rows == 1 {
return s;
}
let mut result = vec![];
let char_array = s.as_bytes();
for r in 0..num_rows {
let mut offset = 0;
while r + offset < n {
result.push(char_array[r+offset]);
offset += 2*(num_rows - 1);
if 1 <= r && r <= num_rows - 2 && offset < n + r {
result.push(char_array[offset-r]);
}
}
}
return String::from_utf8(result).unwrap();
}
}
Complexity (n is the length of string s)
Time complexity:
- \(O(n)\)
Auxiliary Space:
- \( O(n) \)
7. Reverse Integer
Description of the Problem
Given a signed 32-bit integer x, return x with its digits reversed. If reversing x causes the value to go outside the signed 32-bit integer range [-2^31, 2^31 - 1], then return 0.
Assume the environment does not allow you to store 64-bit integers (signed or unsigned).
Example 1:
Input: x = 123
Output: 321
Example 2:
Input: x = -123
Output: -321
Example 3:
Input: x = 120
Output: 21
Constraints:
-2^31 <= x <= 2^31 - 1
Solution
Explanation
Method 1: Use standard library to convert integer
Method 2: Do the Method by yourself. First perform checking of overflow/underflow. Then reverse the integer.
Checking of Overflow/Underflow
If a reverse integer overflows (or underflows), then it has at least 10 digits. (Since i32::MAX and i32::MIN has 10 digits). By contraposition, any number has less than 10 digits does not overflows (nor underflows).
To check whether a reversed full-digit integer overflows (or underflows), we can compare the number with i32::MAX or i32::MIN digit-by-digit.
Example 1: reverse of 2091748912 is 2198471902. Compare the reversed with i32::MAX digit-by-digit
2198471902
2147483647
-----------
1st digit: they are equal (i.e. 2) ==> compare next digit
2nd digit: they are equal (i.e. 1) ==> compare next digit
3nd digit: 9 > 4 ==> It overflows
Example 2: reverse of 2091748012 is 2108471902. Compare the reversed with i32::MAX digit-by-digit
2108471902
2147483647
-----------
1st digit: they are equal (i.e. 2) ==> compare next digit
2nd digit: they are equal (i.e. 1) ==> compare next digit
3nd digit: 0 < 4 ==> It is not possible to overflow
After the checking, just simply calculate the reversed value.
Code - Method 1 (Rust)
impl Solution {
pub fn reverse(n: i32) -> i32 {
let result =
if n > 0 {
n.to_string() // convert the number into String
.chars().rev() // reverse the number_string
.collect::<String>()
.parse::<i32>() // try to parse the reversed number_string
}
else{
n.to_string() // convert the number into String
.chars().skip(1) // skip 1st character i.e. minus sign
.collect::<String>() // convert it into String due to its type
.chars().rev() // reverse the number_string
.collect::<String>()
.parse::<i32>() // try to parse the reversed number_string
.map(|x| -x)
};
// Unwrap the result
return if let Ok(x) = result{
x
}
else{
0
};
}
}
Code - Method 2 (Rust)
impl Solution {
pub fn reverse(n: i32) -> i32 {
static MAX_POW : u32 = 9; // std::i32::MAX and std::i32::MIN has 10 digits
static TEN : i32 = 10;
if Solution::will_overflow_or_underflow(n){
return 0;
}
// Calculate the sum
let mut sum = 0;
let mut n = n;
while n != 0 {
sum *= 10;
sum += n % 10;
n /= 10;
}
return sum;
}
fn will_overflow_or_underflow(n : i32) -> bool {
static MAX_POW : u32 = 9;
static TEN : i32 = 10;
// if the number is not in full-digit, so is its reverse
if ( n>= 0 && n < TEN.pow(MAX_POW)) || (n < 0 && n > -TEN.pow(MAX_POW)){
return false;
}
// Otherwise, check whether the reverse will overflow
let mut is_not_overflow = true;
let mut is_continued;
for p in 0..=MAX_POW{
let digit_n = n / TEN.pow(p) % 10;
if n >= 0{
let digit_max = std::i32::MAX / TEN.pow(MAX_POW - p) % 10;
is_not_overflow = digit_n <= digit_max;
// If the digits are equal, then we have to check next digits
// Otherwise, its reverse must be smaller than std::i32::MAX
is_continued = is_not_overflow && digit_n == digit_max;
}else{
let digit_min = std::i32::MIN / TEN.pow(MAX_POW - p) % 10;
is_not_overflow = digit_n >= digit_min;
// Similarly, if the digits are equal, then we have to check next digits
// Otherwise, its reverse must be smaller than std::i32::MIN
is_continued = is_not_overflow && digit_n == digit_min;
}
if !is_continued{break;}
}
return !is_not_overflow;
}
}
Complexity - Method 2 (\(d\) is the number of digits)
Time complexity:
- \( T(n) = O(2d) \)
- Perform Overflow/Underflow checking and Calculate the reversed number
Auxiliary Space:
- \( S(n) = O(1) \)
- Extracted digits are stored in local variables
11. Container With Most Water
Description of Problem
You are given an integer array height of length n. There are n vertical lines drawn such that the two endpoints of the ith line are (i, 0) and (i, height[i]).
Find two lines that together with the x-axis form a container, such that the container contains the most water.
Return the maximum amount of water a container can store.
Notice that you may not slant the container.
Example 1:
Input: height = [1,8,6,2,5,4,8,3,7]
Output: 49
Explanation: The above vertical lines are represented by array [1,8,6,2,5,4,8,3,7]. In this case, the max area of water (blue section) the container can contain is 49.
Example 2:
Input: height = [1,1]
Output: 1
Constraints:
n == height.length2 <= n <= 10^50 <= height[i] <= 10^4
Solution
Tags: Two Pointers
Explanation
Consider the area with most widest width. And the only reasonable move to get greater area is move a point with smaller height.
Code (Rust)
impl Solution {
pub fn max_area(height: Vec<i32>) -> i32 {
let (mut i, mut j) = (0, height.len() - 1);
let mut max_area = 0;
while i < j {
let area = (j - i) as i32 * height[i].min(height[j]);
max_area = max_area.max(area);
if height[i] < height[j] {
i+=1;
}else {
j-=1;
}
}
return max_area;
}
}
Complexity
- n is length of
height
Time Complexity
- \( T(n) = O(n) \)
Auxiliary Space
- \( S(n) = O(1) \)
12. Integer to Roman
Description of the Problem
Roman numerals are represented by seven different symbols: I, V, X, L, C, D and M.
Symbol Value
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
For example, 2 is written as II in Roman numeral, just two one's added together. 12 is written as XII, which is simply X + II. The number 27 is written as XXVII, which is XX + V + II.
Roman numerals are usually written largest to smallest from left to right. However, the numeral for four is not IIII. Instead, the number four is written as IV. Because the one is before the five we subtract it making four. The same principle applies to the number nine, which is written as IX. There are six instances where subtraction is used:
Ican be placed beforeV(5) andX(10) to make 4 and 9.Xcan be placed beforeL(50) andC(100) to make 40 and 90.Ccan be placed beforeD(500) andM(1000) to make 400 and 900. Given an integer, convert it to a roman numeral.
Example 1:
Input: num = 3
Output: "III"
Explanation: 3 is represented as 3 ones.
Example 2:
Input: num = 58
Output: "LVIII"
Explanation: L = 50, V = 5, III = 3.
Example 3:
Input: num = 1994
Output: "MCMXCIV"
Explanation: M = 1000, CM = 900, XC = 90 and IV = 4.
Constraints:
1 <= num <= 3999
Solution
Explanation
Subtraction occurs in only six instances (i.e. CM, CD, XC, XL, IX, IV).
To convert an integer to a roman number, we shall consider larger numbers first (see the code below).
Code (Rust)
impl Solution {
pub fn int_to_roman(num: i32) -> String {
let mut num = num;
let mut s = String::from("");
while num > 0 {
if 1000 <= num && num <= 3999 {
s.push_str("M");
num -= 1000;
} else if 900 <= num && num < 1000 {
s.push_str("CM");
num -= 900;
} else if 500 <= num && num < 900 {
s.push_str("D");
num -= 500;
} else if 400 <= num && num < 500 {
s.push_str("CD");
num -= 400;
} else if 100 <= num && num < 400 {
s.push_str("C");
num -= 100;
} else if 90 <= num && num < 100 {
s.push_str("XC");
num -= 90;
} else if 50 <= num && num < 90 {
s.push_str("L");
num -= 50;
} else if 40 <= num && num < 50 {
s.push_str("XL");
num -= 40;
} else if 10 <= num && num < 40 {
s.push_str("X");
num -= 10;
} else if 9 <= num && num < 10 {
s.push_str("IX");
num -= 9;
} else if 5 <= num && num < 9 {
s.push_str("V");
num -= 5;
} else if 4 <= num && num < 5 {
s.push_str("IV");
num -= 4;
} else {
s.push_str("I");
num -= 1;
}
}
return s;
}
}
Code (Java)
class Solution {
public String intToRoman(int num) {
StringBuilder sb = new StringBuilder();
while (num > 0) {
if (1000 <= num && num <= 3999) {
sb.append("M");
num -= 1000;
} else if (900 <= num && num < 1000) {
sb.append("CM");
num -= 900;
} else if (500 <= num && num < 900) {
sb.append("D");
num -= 500;
} else if (400 <= num && num < 500) {
sb.append("CD");
num -= 400;
} else if (100 <= num && num < 400) {
sb.append("C");
num -= 100;
} else if (90 <= num && num < 100) {
sb.append("XC");
num -= 90;
} else if (50 <= num && num < 90) {
sb.append("L");
num -= 50;
} else if (40 <= num && num < 50) {
sb.append("XL");
num -= 40;
} else if (10 <= num && num < 40) {
sb.append("X");
num -= 10;
} else if (9 <= num && num < 10) {
sb.append("IX");
num -= 9;
} else if (5 <= num && num < 9) {
sb.append("V");
num -= 5;
} else if (4 <= num && num < 5) {
sb.append("IV");
num -= 4;
} else {
sb.append("I");
num -= 1;
}
}
return sb.toString();
}
}
17. Letter Combination of a Phone Number
Description of the Problem
Given a string containing digits from 2-9 inclusive, return all possible letter combinations that the number could represent. Return the answer in any order.
A mapping of digits to letters (just like on the telephone buttons) is given below. Note that 1 does not map to any letters.
Example 1:
Input: digits = "23"
Output: ["ad","ae","af","bd","be","bf","cd","ce","cf"]
Example 2:
Input: digits = ""
Output: []
Example 3:
Input: digits = "2"
Output: ["a","b","c"]
Constraints:
0 <= digits.length <= 4digits[i]is a digit in the range['2', '9'].
Solution
Explanation
The core of the solution is to define a function to do Cartesian product for list of string. It can be easily implemented by an nested loop.
Code (Rust)
impl Solution {
pub fn letter_combinations(digits: String) -> Vec<String> {
// m a -> (a -> m b) -> m b
let product = | v1: &Vec<String>, v2 : &Vec<&str> | -> Vec<String> {
v1.iter().map(
|e1| v2.iter().map(
|e2| format!("{}{}", e1, e2)
).collect::<Vec<String>>()
)
.flatten().collect::<Vec<String>>()
};
let mut result : Vec<String> = vec![];
for c in digits.chars() {
let rhs = match c {
'2' => vec!["a", "b", "c"],
'3' => vec!["d", "e", "f"],
'4' => vec!["g", "h", "i"],
'5' => vec!["j", "k", "l"],
'6' => vec!["m", "n", "o"],
'7' => vec!["p", "q", "r", "s"],
'8' => vec!["t", "u", "v"],
'9' => vec!["w", "x", "y", "z"],
_ => panic!("Impossible"),
};
result =
if result.len() == 0 { product(&vec!["".to_string()], &rhs) }
else { product(&result, &rhs) };
}
return result;
}
}
Code (Java)
class Solution {
public List<String> letterCombinations(String digits) {
if ( digits.equals("") )
return Collections.emptyList();
List<String> result = List.of("");
for (char d : digits.toCharArray()){
switch(d){
case '2':
result = product(result, List.of("a", "b", "c"));
break;
case '3':
result = product(result, List.of("d", "e", "f"));
break;
case '4':
result = product(result, List.of("g", "h", "i"));
break;
case '5':
result = product(result, List.of("j", "k", "l"));
break;
case '6':
result = product(result, List.of("m", "n", "o"));
break;
case '7':
result = product(result, List.of("p", "q", "r", "s"));
break;
case '8':
result = product(result, List.of("t", "u", "v"));
break;
case '9':
result = product(result, List.of("w", "x", "y", "z"));
break;
}
}
return result;
}
List<String> product(List<String> list1, List<String> list2){
List<String> list3 = new ArrayList<>();
for(String s1 : list1){
for(String s2 : list2){
list3.add(s1+s2);
}
}
return list3;
}
}
Complexity (d is the length of the digits)
Time complexity:
- \(O(4^d)\)
- Each product need
len(L_1) * len(L_2)
- Each product need
Auxiliary Space:
- \( O(1) \)
- The old
List<>/Vec<>is discard in memory by "RAII" if it is not in used.
- The old
19. Remove Nth Node From End of List
Description of the Problem
Given the head of a linked list, remove the nth node from the end of the list and return its head.
Example 1:
Input: head = [1,2,3,4,5], n = 2
Output: [1,2,3,5]
Example 2:
Input: head = [1], n = 1
Output: []
Example 3:
Input: head = [1,2], n = 1
Output: [1]
Constraints:
- The number of nodes in the list is sz.
- 1 <= sz <= 30
- 0 <= Node.val <= 100
- 1 <= n <= sz
Follow up: Could you do this in one pass?
Solution (Does not fullfill the follow-up question)
Code (Java)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode currentNode = head;
int len = 0;
while(currentNode != null){
len++;
currentNode = currentNode.next;
}
ListNode sentinelHead = new ListNode(-1, head);
currentNode = sentinelHead;
while( len - n > 0 ){
n++;
currentNode = currentNode.next;
}
currentNode.next = currentNode.next.next;
return sentinelHead.next;
}
}
Code (Rust)
// Definition for singly-linked list.
// #[derive(PartialEq, Eq, Clone, Debug)]
// pub struct ListNode {
// pub val: i32,
// pub next: Option<Box<ListNode>>
// }
//
// impl ListNode {
// #[inline]
// fn new(val: i32) -> Self {
// ListNode {
// next: None,
// val
// }
// }
// }
impl Solution {
pub fn remove_nth_from_end(head: Option<Box<ListNode>>, n: i32)
-> Option<Box<ListNode>> {
let mut n = n;
// Reverse The List
let mut curr = head;
let mut prev = None;
while let Some(mut node) = curr.take() {
curr = node.next;
node.next = prev;
prev = Some(node);
}
// Reverse again and delete
curr = prev;
prev = None;
while let Some(mut node) = curr.take() {
n-=1;
if (n != 0){
curr = node.next;
node.next = prev;
prev = Some(node);
}else{
curr = node.next;
}
}
return prev;
}
}
22. Generate Parentheses
Description of Problem
Given n pairs of parentheses, write a function to generate all combinations of well-formed parentheses.
Example 1:
Input: n = 3
Output: ["((()))","(()())","(())()","()(())","()()()"]
Example 2:
Input: n = 1
Output: ["()"]
Constraints:
1 <= n <= 8
Solution
Tags: Backtracking
Code (Rust)
impl Solution {
pub fn generate_parenthesis(n: i32) -> Vec<String> {
let mut ans = vec![];
let mut current_string = String::from("");
Self::dfs(0 , 0, n, &mut current_string, &mut ans);
return ans;
}
fn dfs(open : i32, close : i32, n : i32, current_string : &mut String , ans : &mut Vec<String>) {
if open == n && close == n {
ans.push(current_string.clone());
return;
// It's just a speed-up. Remove this block is also okay
} else if close > open {
return;
}
// Open a parenthesis
if open < n {
current_string.push('(');
Self::dfs(open+1, close, n, current_string, ans);
current_string.pop();
}
// Close a parenthsis
if close < n && close < open {
current_string.push(')');
Self::dfs(open, close + 1, n, current_string, ans);
current_string.pop();
}
}
}
24. Swap Nodes in Pairs
Description of the Problem
Given a linked list, swap every two adjacent nodes and return its head. You must solve the problem without modifying the values in the list's nodes (i.e., only nodes themselves may be changed.)
Example 1:
Input: head = [1,2,3,4]
Output: [2,1,4,3]
Example 2:
Input: head = []
Output: []
Example 3:
Input: head = [1]
Output: [1]
Constraints:
- The number of nodes in the list is in the range
[0, 100]. 0 <= Node.val <= 100
Solution
Explanation
As illustrated below (in Haskell), swapping first two nodes and recursively call the function on remaining nodes again.
swapNodesInPair :: [a] -> [a]
swapNodesInPair [] = []
swapNodesInPair [x] = [x]
swapNodesInPair (x1:x2:xs) = x2:x1:(swapNodesInPair xs)
Code (Rust)
// Definition for singly-linked list.
// #[derive(PartialEq, Eq, Clone, Debug)]
// pub struct ListNode {
// pub val: i32,
// pub next: Option<Box<ListNode>>
// }
//
// impl ListNode {
// #[inline]
// fn new(val: i32) -> Self {
// ListNode {
// next: None,
// val
// }
// }
// }
impl Solution {
pub fn swap_pairs(head: Option<Box<ListNode>>) -> Option<Box<ListNode>> {
match head{
None => return None,
// Move value as mutable
Some(mut p) => {
match p.next {
None => Some(p),
Some(mut q) => {
let rest = Self::swap_pairs(q.next);
p.next = rest;
q.next = Some(p);
return Some(q);
}
}
}
}
}
}
Code (Java)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode swapPairs(ListNode head) {
if (head == null){return null;}
if (head.next == null) {return head;}
ListNode temp = head.next.next;
head.next.next = head;
head = head.next;
head.next.next = swapPairs(temp);
return head;
}
}
Complexity (n is the number of nodes in a linked list)
Time complexity:
- \( O(n) \)
Auxiliary Space:
- \( O(n) \)
31. Next Permutation
Description of Problem
A permutation of an array of integers is an arrangement of its members into a sequence or linear order.
For example, for arr = [1,2,3], the following are all the permutations of arr: [1,2,3], [1,3,2], [2, 1, 3], [2, 3, 1], [3,1,2], [3,2,1].
The next permutation of an array of integers is the next lexicographically greater permutation of its integer. More formally, if all the permutations of the array are sorted in one container according to their lexicographical order, then the next permutation of that array is the permutation that follows it in the sorted container. If such arrangement is not possible, the array must be rearranged as the lowest possible order (i.e., sorted in ascending order).
- For example, the next permutation of
arr = [1,2,3]is[1,3,2]. - Similarly, the next permutation of
arr = [2,3,1]is[3,1,2]. - While the next permutation of
arr = [3,2,1]is[1,2,3]because[3,2,1]does not have a lexicographical larger rearrangement.
Given an array of integers nums, find the next permutation of nums.
The replacement must be in place and use only constant extra memory.
Example 1:
Input: nums = [1,2,3]
Output: [1,3,2]
Example 2:
Input: nums = [3,2,1]
Output: [1,2,3]
Example 3:
Input: nums = [1,1,5]
Output: [1,5,1]
Constraints:
1 <= nums.length <= 1000 <= nums[i] <= 100
Solution
Tags: Permutation and Combination
Explanation
The explanation just follow the offical answer and Back To Back SWE's video:
The solution has 3 steps:
- Find the pivot and the right sublist.
- Swapping pivot and the rightmost number from right sublist that just greater than pivot.
- Reversing the right sublist.
Explanation part 0:
To find next permutation, we have to find the next greater number composed by the list of numbers.
Notice that the list of non-ascending numbers does not have next permutation since it composes the largest number. For example, [9 7 5 5 2 1] does not have next permutation.
Explanation part 1:
To generate next permutation, we must first find the sublist from the right that is in non-ascending order since it is not possible to re-arrange them to get the greater number.
For instance, in [9 7 1 5 5 2], it's not possible to get greater permutation by re-arrrangement of [5 5 2].
We call the left neighbour of the sublist a pivot. In the above example, 1 is the pivot.
Explanation part 2:
The next step is to swap the pivot and the rightmost minimum number from the sublist that just greater than the pivot.
[1]: Since the sublist will be reversed later. We choose the right most one to make sure the the reversed number is the minimum one.
Explanation part 3:
After swapping, the sublist still compose the greatest number as swapping does not change the order[2]. Thus, it is not the next greater number. To get the number we must reverse the right sublist.
[2]: (Optional) Prove that the swapping does not change the order of the sublist:
Consider the following list which \(a_i\) is the pivot, \([a_{i}, ..., a_{n-1} ]\) is the right sublist and \(a_j\) is the chosen number to be swapped. \[ [... a_i \lt a_{i+1} \ge ... \ge a_{j-1} \ge a_{j} \ge a_{j+1} \ge ... \ge a_{n-1}] \]
There are 4 facts have to be reminded:
- \( a_i \lt a_j \)
- \( a_j \le a_{j-1} \)
- \( a_{j+1} \le a_{j} \)
- \( \forall k \in \lbrace i+1, ..., n-1 \rbrace ( a_i \lt a_k \rightarrow a_j \le a_k ) \)
- since \(a_j\) is the minimum number amongst the numbers that greater than \(a_i\)
From fact (1) and fact (2), we get \( a_{j-1} \ge a_{i} \).
Assume \( a_{i} \lt a_{j+1} \), we get \( a_{j} \le a_{j+1} \) from fact (4) which contradicts the fact (3). Thus, \( a_{i} \ge a_{j+1} \).
We conclude that the swapping does not change the order:
\[ [... a_j \lt a_{i+1} \ge ... \ge a_{j-1} \ge a_{i} \ge a_{j+1} \ge ... \ge a_{n-1}] \]
Code (Rust)
impl Solution {
pub fn next_permutation(nums: &mut Vec<i32>) {
if let Some(i) = Self::find_pivot(nums) {
let j = Self::find_target(nums, i);
nums.swap(i,j);
&mut nums[i+1..].reverse();
} else {
nums.reverse();
}
}
fn find_pivot(nums : &[i32]) -> Option<usize> {
if nums.len() < 2 {
return None;
}
let (mut i, mut j) = (nums.len() - 2, nums.len() - 1);
while /*i >= 0 &&*/ j >= 1 {
if nums[i] < nums[j] {
return Some(i);
}
i = i.checked_sub(1).unwrap_or(0);
j = j.checked_sub(1).unwrap_or(0);
}
return None;
}
// find the right most index
// such that its elements is the smallest number
// which greater than the pivot value
fn find_target(nums : &[i32], pivot : usize) -> usize {
let pivot_value = nums[pivot];
let mut target_index = pivot+1;
let mut target_value = nums[target_index];
for j in pivot+2..nums.len() {
let v = nums[j];
if v > pivot_value && v <= target_value {
target_value = v;
target_index = j;
}
}
return target_index;
}
}
Complexity
Time Complexity
- \(T(n) = O(n)\)
Auxiliary Space
- \(S(n) = O(1)\)
Appendix A1 - Implementation of Permutation Iterator
pub struct PermutationIterator<T : Ord + Clone>(Option<Vec<T>>);
impl<T : Ord + Clone> PermutationIterator<T> {
pub fn new(mut elements : Vec<T>) -> Self {
elements.sort();
PermutationIterator(Some(elements))
}
fn next_permutation(&mut self) -> Option<Vec<T>> {
let res = self.0.clone();
self.0 = self.0.take().and_then(|mut v|{
let i = Self::find_pivot(&v)?;
let j = Self::find_target(&mut v, i);
v.swap(i,j);
let _ = &mut v[i+1..].reverse();
Some(v)
});
return res;
}
fn find_pivot(elements : &[T]) -> Option<usize> {
if elements.len() < 2 {
return None;
}
let (mut i, mut j) = (elements.len() - 2, elements.len() - 1);
while /* i >= 0 && */ j >= 1 {
if elements[i] < elements[j] {
return Some(i);
}
i = i.checked_sub(1).unwrap_or(0);
j = j.checked_sub(1).unwrap_or(0);
}
return None;
}
// find the right most index
// such that its elements is the smallest number
// which greater than the pivot value
fn find_target(elements : &mut [T], pivot : usize) -> usize {
let pivot_value = &elements[pivot];
let mut target_index = pivot+1;
let mut target_value = &elements[target_index];
for j in pivot+2..elements.len() {
let v = &elements[j];
if v > pivot_value && v <= target_value {
target_value = v;
target_index = j;
}
}
return target_index;
}
}
impl<T : Ord + Clone> Iterator for PermutationIterator<T> {
type Item = Vec<T>;
fn next(&mut self) -> Option<Self::Item> {
self.next_permutation()
}
}
36. Valid Sudoku
Description of Problem
Determine if a 9 x 9 Sudoku board is valid. Only the filled cells need to be validated according to the following rules:
- Each row must contain the digits
1-9without repetition. - Each column must contain the digits
1-9without repetition. - Each of the nine
3 x 3sub-boxes of the grid must contain the digits1-9without repetition.
Note:
- A Sudoku board (partially filled) could be valid but is not necessarily solvable.
- Only the filled cells need to be validated according to the mentioned rules.
Example 1:
Input: board =
[["5","3",".",".","7",".",".",".","."]
,["6",".",".","1","9","5",".",".","."]
,[".","9","8",".",".",".",".","6","."]
,["8",".",".",".","6",".",".",".","3"]
,["4",".",".","8",".","3",".",".","1"]
,["7",".",".",".","2",".",".",".","6"]
,[".","6",".",".",".",".","2","8","."]
,[".",".",".","4","1","9",".",".","5"]
,[".",".",".",".","8",".",".","7","9"]]
Output: true
Example 2:
Input: board =
[["8","3",".",".","7",".",".",".","."]
,["6",".",".","1","9","5",".",".","."]
,[".","9","8",".",".",".",".","6","."]
,["8",".",".",".","6",".",".",".","3"]
,["4",".",".","8",".","3",".",".","1"]
,["7",".",".",".","2",".",".",".","6"]
,[".","6",".",".",".",".","2","8","."]
,[".",".",".","4","1","9",".",".","5"]
,[".",".",".",".","8",".",".","7","9"]]
Output: false
Explanation: Same as Example 1, except with the 5 in the top left corner being modified to 8. Since there are two 8's in the top left 3x3 sub-box, it is invalid.
Constraints:
board.length == 9board[i].length == 9board[i][j]is a digit1-9or'.'.
Solution
Explanation
Just hardcoded and use only one counter to reduce auxiliary space.
Code
impl Solution {
pub fn is_valid_sudoku(board: Vec<Vec<char>>) -> bool {
// assert!(board.len() == 9);
// for i in 0..board.len() {
// assert!(board[i].len() == 9);
// }
let mut counter = vec![0; 9];
for i in (0..9).step_by(3) {
for j in (0..9).step_by(3) {
Solution::count(&mut counter, board[i][j]);
Solution::count(&mut counter, board[i][j+1]);
Solution::count(&mut counter, board[i][j+2]);
Solution::count(&mut counter, board[i+1][j]);
Solution::count(&mut counter, board[i+1][j+1]);
Solution::count(&mut counter, board[i+1][j+2]);
Solution::count(&mut counter, board[i+2][j]);
Solution::count(&mut counter, board[i+2][j+1]);
Solution::count(&mut counter, board[i+2][j+2]);
if counter.iter().any(|x| *x > 1) {
return false;
}
Solution::clear_count(&mut counter);
}
}
for i in 0..9 {
for j in 0..9 {
Solution::count(&mut counter, board[i][j]);
}
if counter.iter().any(|x| *x > 1) {
return false;
}
Solution::clear_count(&mut counter);
}
for j in 0..9 {
for i in 0..9 {
Solution::count(&mut counter, board[i][j]);
}
if counter.iter().any(|x| *x > 1) {
return false;
}
Solution::clear_count(&mut counter);
}
return true;
}
fn count(counter : &mut [u32], ch: char) {
match ch {
'1' => counter[0]+=1,
'2' => counter[1]+=1,
'3' => counter[2]+=1,
'4' => counter[3]+=1,
'5' => counter[4]+=1,
'6' => counter[5]+=1,
'7' => counter[6]+=1,
'8' => counter[7]+=1,
'9' => counter[8]+=1,
_ => {},
}
}
fn clear_count(counter: &mut [u32]) {
for i in 0..counter.len() {
counter[i] = 0;
}
}
}
39. Combination Sum
Description of the Problem
Given an array of distinct integers candidates and a target integer target, return a list of all unique combinations of candidates where the chosen numbers sum to target. You may return the combinations in any order.
The same number may be chosen from candidates an unlimited number of times. Two combinations are unique if the
frequency
of at least one of the chosen numbers is different.
The test cases are generated such that the number of unique combinations that sum up to target is less than 150 combinations for the given input.
Example 1:
Input: candidates = [2,3,6,7], target = 7
Output: [[2,2,3],[7]]
Explanation:
2 and 3 are candidates, and 2 + 2 + 3 = 7. Note that 2 can be used multiple times.
7 is a candidate, and 7 = 7.
These are the only two combinations.
Example 2:
Input: candidates = [2,3,5], target = 8
Output: [[2,2,2,2],[2,3,3],[3,5]]
Example 3:
Input: candidates = [2], target = 1
Output: []
Constraints:
1 <= candidates.length <= 302 <= candidates[i] <= 40- All elements of
candidatesare distinct. 1 <= target <= 40
Solution
Explantion
Hints: For every target value, we either select first candidate or not to select first candidate. (See the below code)
Code (Rust)
impl Solution {
pub fn combination_sum(candidates: Vec<i32>, target: i32) -> Vec<Vec<i32>> {
let mut ans = vec![];
let mut current_selection = vec![];
Solution::helper(&candidates, target, &mut current_selection, &mut ans);
return ans;
}
fn helper(
candidates : &[i32],
target: i32,
current_selection: &mut Vec<i32>,
ans: &mut Vec<Vec<i32>>
) {
// Meet the target
if target == 0 {
// Append Answer
ans.push(current_selection.clone());
// Do not have any candidate or current sum exceed the target
}else if candidates.len() == 0 || target < 0 {
return;
}else {
// Select the first candidate and then calculate the result
current_selection.push(candidates[0]);
Solution::helper(candidates, target - candidates[0], current_selection, ans);
current_selection.pop();
// Skip the first candidate and then calculate the result
Solution::helper(&candidates[1..], target, current_selection, ans);
}
}
}
46. Permutations
Description of the Problem
Given an array nums of distinct integers, return all the possible permutations. You can return the answer in any order.
Example 1:
Input: nums = [1,2,3]
Output: [[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
Example 2:
Input: nums = [0,1]
Output: [[0,1],[1,0]]
Example 3:
Input: nums = [1]
Output: [[1]]
Constraints:
1 <= nums.length <= 610 <= nums[i] <= 10All the integers ofnumsare unique.
Solution 1 - Utilise the answer from [60. Permutation Sequence]
Tags: Permutation and Combination
Code
impl Solution {
fn helper_permute(nums: &[i32])->Vec<Vec<i32>>{
if nums.len() == 0{
return vec![vec![]];
}
if nums.len() == 1{
return vec![nums.to_vec()];
}
let mut return_vec = vec![];
for i in 0..nums.len(){
let chosen = nums[i];
let permutations = Solution::helper_permute(&[&nums[0..i], &nums[i+1..]].concat());
for perm in permutations {
let permutations = [ &[chosen] , &perm[..] ].concat();
return_vec.push(permutations);
}
}
return return_vec;
}
pub fn permute(nums: Vec<i32>) -> Vec<Vec<i32>> {
return Solution::helper_permute(&nums);
}
}
Solution 2 - Reuse the iterator from [31. Next Permutation]
Tags: Permutation and Combination
Code
impl Solution {
pub fn permute(nums: Vec<i32>) -> Vec<Vec<i32>> {
let iter: PermutationIterator = PermutationIterator::new(nums);
let mut ans = vec![];
for v in iter {
ans.push(v);
}
return ans;
}
}
47. Permutations II
Description of Problem
Given a collection of numbers, nums, that might contain duplicates, return all possible unique permutations in any order.
Example 1:
Input: nums = [1,1,2]
Output:
[[1,1,2],
[1,2,1],
[2,1,1]]
Example 2:
Input: nums = [1,2,3]
Output: [[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
Constraints:
1 <= nums.length <= 8-10 <= nums[i] <= 10
Solution - Reuse the iterator from [31. Next Permutation]
Tags: Permutation and Combination
Code
impl Solution {
pub fn permute_unique(nums: Vec<i32>) -> Vec<Vec<i32>> {
PermutationIterator::new(nums).into_iter().collect()
}
}
48. Rotate Image
Description of Problem
You are given an n x n 2D matrix representing an image, rotate the image by 90 degrees (clockwise).
You have to rotate the image in-place, which means you have to modify the input 2D matrix directly. DO NOT allocate another 2D matrix and do the rotation.
Example 1:
Input: matrix = [[1,2,3],[4,5,6],[7,8,9]]
Output: [[7,4,1],[8,5,2],[9,6,3]]
Example 2:
Input: matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
Output: [[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]]
Constraints:
n == matrix.length == matrix[i].length1 <= n <= 201000 <= matrix[i][j] <= 1000
Solution 1
Explanation
Code (Rust)
#![allow(unused)] fn main() { impl Solution { pub fn rotate(matrix: &mut Vec<Vec<i32>>) { Solution::transpose(matrix); Solution::y_reflection(matrix); } fn transpose(matrix: &mut Vec<Vec<i32>>) { let n = matrix.len(); for i in 0..n { for j in (i+1)..n { let temp = matrix[i][j]; matrix[i][j] = matrix[j][i]; matrix[j][i] = temp; } } } fn y_reflection(matrix: &mut Vec<Vec<i32>>) { let n = matrix.len(); for i in 0..n { for j in 0..(n/2) { let temp = matrix[i][j]; matrix[i][j] = matrix[i][n - 1 - j]; matrix[i][n - 1 - j] = temp; } } } } }
Solution 2
Explanation
We can rotate elements from exterior to interior by swapping area 1 and 2, swapping area 2 and 3, and area 3 and 4.
Code (Rust)
#![allow(unused)] fn main() { impl Solution { pub fn rotate(matrix: &mut Vec<Vec<i32>>) { let mut i = 0; let n = matrix.len(); while i < n / 2 { // swap 1 2 for j in i..=(n-i-2){ let temp = matrix[i][j]; matrix[i][j] = matrix[j][n - i - 1]; matrix[j][n - i - 1] = temp; } // swap 2 3 for j in i..=(n-i-2){ let temp = matrix[i][j]; matrix[i][j] = matrix[n - i - 1][n - 1 - j]; matrix[n - i - 1][n - 1 - j] = temp; } // swap 3 4 for j in i..=(n-i-2){ let temp = matrix[i][j]; matrix[i][j] = matrix[n - 1 - j][i]; matrix[n - 1 - j][i] = temp; } i+=1; } } } }
Further Discussion
This problem though seems very easy, is very important in daily life. If we have to allocate another 2d array for rotation, we have to spend more memory on photo editing.
50. Pow(x, n)
Description of Problem
Implement pow(x, n), which calculates x raised to the power n (i.e., x^n).
Example 1:
Input: x = 2.00000, n = 10
Output: 1024.00000
Example 2:
Input: x = 2.10000, n = 3
Output: 9.26100
Example 3:
Input: x = 2.00000, n = -2
Output: 0.25000
Explanation: 2-2 = 1/22 = 1/4 = 0.25
Constraints:
-100.0 < x < 100.0-2^31 <= n <= 2^31-1nis an integer.- Either
xis not zero orn > 0. -10^4<=x^n<=10^4
Solution
Explantion
The core of the problem is to consider all edge cases and remember to handle the overflow/underflow cases. The calculation can be done by "Divide and Conquer" approach.
Code (Rust)
impl Solution {
fn my_pow(x : f64, n: i32) -> f64{
match (x, n){
(0.0, _) => 0.0,
(-1.0, n) => if n % 2 == 1 {-1.0} else {1.0},
(1.0, _) | (_, 0) => 1.0,
(x, i32::MIN) => 1.0 / Self::my_pow(x, -(n+1)),
(x, n) => {
if n < 0 {
1.0 / Self::my_pow(x, -n)
}
else{
let v = Self::my_pow(x, n/2);
match (n % 2 == 0) {
true => v * v,
false => v * v * x,
}
}
}
}
}
}
Complexity
- n is the exponent
Time complexity:
- \(T(n)=O(\log(n))\)
- In general, the number of functional calls is bound by \(\log(n)\).
Auxiliary Space:
- \(S(n)=O(\log(n))\)
- Same reason as the above-mentioned.
54. Spiral Matrix
Description of Problem
Given an m x n matrix, return all elements of the matrix in spiral order.
Example 1:
Input: matrix = [[1,2,3],[4,5,6],[7,8,9]]
Output: [1,2,3,6,9,8,7,4,5]
Example 2:
Input: matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
Output: [1,2,3,4,8,12,11,10,9,5,6,7]
Constraints:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 10-100 <= matrix[i][j] <= 100
Solution
Tags: Divide and Conquer
Explanation
The same manner as 59. Spiral Matrix II. However, we must consider 4 base cases at the end.
Code
impl Solution {
pub fn spiral_order(matrix: Vec<Vec<i32>>) -> Vec<i32> {
let mut m = matrix.len();
let mut n = matrix[0].len();
let mut row = 0;
let mut col = 0;
let mut v = vec![];
while m > 1 && n > 1 {
Solution::fill1(&matrix, &mut v, row, col, m, n);
Solution::fill2(&matrix, &mut v, row, col, m, n);
Solution::fill3(&matrix, &mut v, row, col, m, n);
Solution::fill4(&matrix, &mut v, row, col, m, n);
row+=1; col+=1;
m-=2; n-=2;
}
let mut i = 0;
while m > 1 && n == 1 && i < m {
v.push(matrix[row+i][col]);
i+=1;
}
let mut j = 0;
while n > 1 && m == 1 && j < n {
v.push(matrix[row][col+j]);
j+=1;
}
if m == 1 && n == 1{
v.push(matrix[row][col]);
}
return v;
}
fn fill1(
matrix : &Vec<Vec<i32>>,
v: &mut Vec<i32>,
row: usize,
col: usize,
m: usize,
n: usize
) {
for j in 0..=(n-2) {
v.push(matrix[row][col+j]);
}
}
fn fill2(
matrix : &Vec<Vec<i32>>,
v: &mut Vec<i32>,
row: usize,
col: usize,
m: usize,
n: usize
) {
for i in 0..=(m-2) {
v.push(matrix[row+i][col+n-1]);
}
}
fn fill3(
matrix : &Vec<Vec<i32>>,
v: &mut Vec<i32>,
row: usize,
col: usize,
m: usize,
n: usize
) {
for j in (1..=(n-1)).rev() {
v.push(matrix[row + m -1][col+j]);
}
}
fn fill4(
matrix : &Vec<Vec<i32>>,
v: &mut Vec<i32>,
row: usize,
col: usize,
m: usize,
n: usize
) {
for i in (1..=(m-1)).rev() {
v.push(matrix[row + i][col]);
}
}
}
55. Jump Game
Description of Problem
You are given an integer array nums. You are initially positioned at the array's first index, and each element in the array represents your maximum jump length at that position.
Return true if you can reach the last index, or false otherwise.
Example 1:
Input: nums = [2,3,1,1,4]
Output: true
Explanation: Jump 1 step from index 0 to 1, then 3 steps to the last index.
Example 2:
Input: nums = [3,2,1,0,4]
Output: false
Explanation: You will always arrive at index 3 no matter what. Its maximum jump length is 0, which makes it impossible to reach the last index.
Constraints:
1 <= nums.length <= 10^40 <= nums[i] <= 10^5
Solution
Explantion
The core concept is to record the current maximum reachable distance. For each node, if the node is currently reachable, then update the current maximum reachable distance. Otherwise, the final node is unreachable.
Code (Java)
class Solution {
public boolean canJump(int[] nums) {
int reachable = 0;
int n = nums.length;
for(int i = 0; i < n; i++){
if (reachable < i){
return false;
}
reachable = Math.max(reachable, i + nums[i]);
if (reachable >= n-1){
return true;
}
}
return true;
}
}
Complexity
Time complexity:
- \(T(n)=O(n)\)
Auxiliary Space:
- \(S(n)=O(1)\)
56. Merge Intervals
Description of Problem
Given an array of intervals where intervals[i] = [starti, endi], merge all overlapping intervals, and return an array of the non-overlapping intervals that cover all the intervals in the input.
Example 1:
Input: intervals = [[1,3],[2,6],[8,10],[15,18]]
Output: [[1,6],[8,10],[15,18]]
Explanation: Since intervals [1,3] and [2,6] overlap, merge them into [1,6].
Example 2:
Input: intervals = [[1,4],[4,5]]
Output: [[1,5]]
Explanation: Intervals [1,4] and [4,5] are considered overlapping.
Constraints:
1 <= intervals.length <= 10^4intervals[i].length == 20 <= starti <= endi <= 10^4
Solution
Tags: Stack
Explanation
We use the same manner in 452. Minimum Number of Arrows to Burst Balloons. In this case, we do not do intersection. Instead, we do union if there is an overlapping.
Code (Rust)
impl Solution {
pub fn merge(intervals: Vec<Vec<i32>>) -> Vec<Vec<i32>> {
let mut intervals = intervals;
intervals.sort_by(|a,b| a[0].cmp(&b[0]));
let mut stack : Vec<(Vec<i32>)> = Vec::new();
for int in intervals.into_iter() {
let (c, d) = (int[0], int[1]);
if let Some(v) = stack.last(){
let (a, b) = (v[0], v[1]);
if b >= c {
stack.pop();
stack.push(vec![a.min(c), b.max(d)]);
}else{
stack.push(int);
}
}else{
stack.push(int);
}
}
return stack;
}
}
Complexity
- n is length of
intervals
Time Complexity
- \( T(n) = \Theta(n \lg n+ n) \)
Auxiliary Space
- \( S(n) = O(n) \)
- For sorting
57. Insert Interval
Description of Problem
You are given an array of non-overlapping intervals intervals where intervals[i] = [starti, endi] represent the start and the end of the ith interval and intervals is sorted in ascending order by starti. You are also given an interval newInterval = [start, end] that represents the start and end of another interval.
Insert newInterval into intervals such that intervals is still sorted in ascending order by starti and intervals still does not have any overlapping intervals (merge overlapping intervals if necessary).
Return intervals after the insertion.
Example 1:
Input: intervals = [[1,3],[6,9]], newInterval = [2,5]
Output: [[1,5],[6,9]]
Example 2:
Input: intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval = [4,8]
Output: [[1,2],[3,10],[12,16]]
Explanation: Because the new interval [4,8] overlaps with [3,5],[6,7],[8,10].
Constraints:
0 <= intervals.length <= 10^4intervals[i].length == 20 <= starti <= endi <= 10^5intervalsis sorted by starti in ascending order.newInterval.length == 20 <= start <= end <= 10^5
Solution
Tags: Stack
Explanation
Since intervals is sorted, we can insert new element at proper position in O(n). And call solution of 56. Merge Intervals to solve the problem.
Code (Rust)
impl Solution {
pub fn insert(intervals: Vec<Vec<i32>>, new_interval: Vec<i32>) -> Vec<Vec<i32>> {
let mut intervals = intervals;
let y = new_interval[0];
let index = intervals.partition_point(|i| i[0] < y);
intervals.insert(index, new_interval);
return Self::merge(intervals);
}
// Copy solution of [56. Merge Intervals]
#[inline(always)]
fn merge(intervals: Vec<Vec<i32>>) -> Vec<Vec<i32>> {
//let mut intervals = intervals;
//intervals.sort_by(|a,b| a[0].cmp(&b[0]));
let mut stack : Vec<Vec<i32>> = Vec::new();
for int in intervals.into_iter() {
let (c, d) = (int[0], int[1]);
if let Some(v) = stack.last(){
let (a, b) = (v[0], v[1]);
if b >= c {
stack.pop();
stack.push(vec![a.min(c), b.max(d)]);
}else{
stack.push(int);
}
}else{
stack.push(int);
}
}
return stack;
}
}
Complexity
- n is length of
intervals
Time Complexity
- \( T(n) = \Theta(n) \)
Auxiliary Space
- \( S(n) = O(1) \)
59. Spiral Matrix II
Description of Problem
Given a positive integer n, generate an n x n matrix filled with elements from 1 to n^2 in spiral order.
Example 1:
Input: n = 3
Output: [[1,2,3],[8,9,4],[7,6,5]]
Example 2:
Input: n = 1
Output: [[1]]
Constraints:
1 <= n <= 20
Solution
Tags: Divide and Conquer
Explanation
Seqentially filling-in matrix from top, right, bottom left. This process reduce the problem size and continue the above process again.
Example (3x3 matrix):
Top:
| 1 | 2 | . |
| . | . | . |
| . | . | . |
Right:
| 1 | 2 | 3 |
| . | . | 4 |
| . | . | . |
Bottom:
| 1 | 2 | 3 |
| . | . | 4 |
| . | 6 | 5 |
Left:
| 1 | 2 | 3 |
| 8 | . | 4 |
| 7 | 6 | 5 |
Code
impl Solution {
pub fn generate_matrix(n: i32) -> Vec<Vec<i32>> {
let mut n = n as usize;
let mut matrix = vec![ vec![0; n]; n];
let mut counter = 1;
let (mut row, mut col) = (0, 0);
while n > 0 {
println!("Loop: {n}");
if n == 1 {
matrix[row][col] = counter;
counter+=1; n-=1;
} else if n > 1 {
Solution::fill1(&mut matrix, &mut counter, row, col, n);
Solution::fill2(&mut matrix, &mut counter, row, col, n);
Solution::fill3(&mut matrix, &mut counter, row, col, n);
Solution::fill4(&mut matrix, &mut counter, row, col, n);
row+=1; col+=1; n-=2;
}
}
return matrix;
}
fn fill1(
matrix : &mut Vec<Vec<i32>>,
counter: &mut i32,
row: usize,
col: usize,
n: usize
) {
for j in 0..=(n-2) {
matrix[row][col+j] = *counter;
*counter +=1
}
}
fn fill2(
matrix : &mut Vec<Vec<i32>>,
counter: &mut i32,
row: usize,
col: usize,
n: usize
) {
for i in 0..=(n-2) {
matrix[row+i][col+n-1] = *counter;
*counter +=1
}
}
fn fill3(
matrix : &mut Vec<Vec<i32>>,
counter: &mut i32,
row: usize,
col: usize,
n: usize
) {
for j in (1..=(n-1)).rev() {
matrix[row + n -1][col+j] = *counter;
*counter +=1
}
}
fn fill4(
matrix : &mut Vec<Vec<i32>>,
counter: &mut i32,
row: usize,
col: usize,
n: usize
) {
for i in (1..=(n-1)).rev() {
matrix[row + i][col] = *counter;
*counter +=1
}
}
}
62. Unique Paths
Description of Problem
There is a robot on an m x n grid. The robot is initially located at the top-left corner (i.e., grid[0][0]). The robot tries to move to the bottom-right corner (i.e., grid[m - 1][n - 1]). The robot can only move either down or right at any point in time.
Given the two integers m and n, return the number of possible unique paths that the robot can take to reach the bottom-right corner.
The test cases are generated so that the answer will be less than or equal to 2 * 10^9.
Example 1:
Input: m = 3, n = 7
Output: 28
Example 2:
Input: m = 3, n = 2
Output: 3
Explanation: From the top-left corner, there are a total of 3 ways to reach the bottom-right corner:
1. Right -> Down -> Down
2. Down -> Down -> Right
3. Down -> Right -> Down
Constraints:
1 <= m, n <= 100
Solution
Tags: Permutation and Combination Dynamic Programming
Explanation
The examples of the problem gives us hints. The number of unique path is the number of unique combination of Move Right and Move Down.
Thus, the solution is \( \frac{(m-1+n-1)!}{(m-1)!(n-1)!} \).
However, the calculation of the number will cause the integer overflow. Therefore, we have to use DP to calculate the number:
\[ \begin{align} P_{m,n} & = \frac{(m+n)!}{m! \ n!} \\ P_{m-1,n} + P_{m,n-1} & = \frac{(m-1+n)!}{(m-1)! \ n!} + \frac{(m+n-1)!}{m! \ (n-1)!} \\ & = \frac{m \ (m-1+n)!}{m \ (m-1)! \ n!} + \frac{(m+n-1)! \ n}{m! \ (n-1)! \ n} \\ & = \frac{m \ (m-1+n)! + (m+n-1)! \ n}{m! \ n!} \\ & = \frac{(m+n) \ (m-1+n)!}{m! \ n!} \\ & = P_{m,n} \end{align} \]
Code (Rust)
impl Solution {
pub fn unique_paths(m: i32, n: i32) -> i32 {
if m <= 1 || n <= 1 {
return 1;
}
let (m,n) = (m as usize, n as usize);
let mut dp = vec![ vec![1;n];m ];
for i in 1..m {
for j in 1..n{
dp[i][j] = dp[i][j-1] + dp[i-1][j];
}
}
return dp[m-1][n-1] as i32;
}
}
Complexity
Time Complexity
- \(T(m,n) = \Theta(m,n)\)
Auxiliary Space
- \(S(m,n) = O(m,n)\)
64. Minimum Path Sum
Description of Problem
Given a m x n grid filled with non-negative numbers, find a path from top left to bottom right, which minimizes the sum of all numbers along its path.
Note: You can only move either down or right at any point in time.
Example 1:
Input: grid = [[1,3,1],[1,5,1],[4,2,1]]
Output: 7
Explanation: Because the path 1 → 3 → 1 → 1 → 1 minimizes the sum.
Example 2:
Input: grid = [[1,2,3],[4,5,6]]
Output: 12
Constraints:
m == grid.lengthn == grid[i].length1 <= m, n <= 2000 <= grid[i][j] <= 200
Solution
Code (Rust)
impl Solution {
pub fn min_path_sum(grid: Vec<Vec<i32>>) -> i32 {
let m = grid.len();
let n = if m > 0 {grid[0].len()} else {0};
let mut sum = vec![ vec![0; n]; m];
for i in 0..m{
for j in 0..n{
match (i > 0,j > 0) {
(false, false) => {
sum[i][j] = grid[i][j];
},
(false, true) => {
sum[i][j] = grid[i][j] + sum[i][j-1];
},
(true, false) => {
sum[i][j] = grid[i][j] + sum[i-1][j];
},
(true, true) => {
sum[i][j] = grid[i][j] + sum[i-1][j].min(sum[i][j-1]);
},
}
}
}
return sum[m-1][n-1];
}
}
Complexity
Time Complexity
- \(T(m,n)=\Theta(m \ n)\)
Auxiliary Space
- \(S(m,n)=O(m \ n)\)
78. Subsets
Description of the Problem
Given an integer array nums of unique elements, return all possible subsets (the power set).
The solution set must not contain duplicate subsets. Return the solution in any order.
Example 1:
Input: nums = [1,2,3]
Output: [[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
Example 2:
Input: nums = [0]
Output: [[],[0]]
Constraints:
1 <= nums.length <= 10-10 <= nums[i] <= 10- All the numbers of
numsare unique.
Solution
Explanation
For any elements in a set, we have two options (Yes-No Question Method): either it is in the subset and it isn't in the subset.
Code (Rust)
impl Solution {
pub fn subsets(mut nums: Vec<i32>) -> Vec<Vec<i32>> {
return Self::dfs(&mut nums);
}
fn dfs(v : &mut Vec<i32> ) -> Vec<Vec<i32>> {
if v.len() == 0 {
return vec![vec![]];
}else {
let last = v
.pop()
.expect("Should have a number");
// Set of set which does not contain the last element
let mut no_comb = Self::dfs(v);
// Set of set which **does** contain the last element
let mut yes_comb = no_comb.clone();
for set in yes_comb.iter_mut() {
set.push(last);
}
// Combine into one
no_comb.extend(yes_comb);
return no_comb;
}
}
}
Complexity (n is the number of elements in the set)
Time complexity:
- \( \Theta(n^2) \)
- Recursive Approach: \(T(n) = T(n - 1) + c \cdot (n-1) + c \cdot n\)
Auxiliary Space:
- \( \Theta(n) \)
- \(n\) for stack calls
98. Validate Binary Search Tree
Description of the Problem
Given the root of a binary tree, determine if it is a valid binary search tree (BST).
A valid BST is defined as follows:
The left subtree of a node contains only nodes with keys less than the node's key. The right subtree of a node contains only nodes with keys greater than the node's key. Both the left and right subtrees must also be binary search trees.
Example 1:
Input: root = [2,1,3]
Output: true
Example 2:
Input: root = [5,1,4,null,null,3,6]
Output: false
Explanation: The root node's value is 5 but its right child's value is 4.
Constraints:
- The number of nodes in the tree is in the range
[1, 10^4]. -2^31 <= Node.val <= 2^31 - 1
Solution
Tags: Binary Search Tree
Explanation
The problem itself explains how to form a solution.
The left subtree of a node contains only nodes with keys less than the node's key.
The right subtree of a node contains only nodes with keys greater than the node's key.
To check the above properies, each parent node must know the in-order traversal of both sub-trees. When in-order traversals are available, they can be compared with the parent value.
To speed up the evaluation of the properties, the recursive function return true when the properties are matched, otherwise it return false. If parent node receives false from a child, the function skips the comparsion (Reminder: The order of boolean expressions matters).
Code
use std::rc::Rc;
use std::cell::RefCell;
impl Solution{
pub fn is_valid_bst(root : Option<Rc<RefCell<TreeNode>>>) -> bool {
let (is_valid, _) = Solution::verify(root);
return is_valid;
}
fn verify(node : Option<Rc<RefCell<TreeNode>>>) -> (bool, Vec<i32>){
if let Some(node) = node {
let node = node.borrow();
let (is_left_valid, mut left_vec) = Solution::verify(node.left.clone());
let (is_right_valid, right_vec) = Solution::verify(node.right.clone());
let is_this_valid = is_left_valid && is_right_valid
&& left_vec.iter().all( |l| *l < node.val )
&& right_vec.iter().all( |r| node.val < *r );
left_vec.push(node.val);
left_vec.extend(right_vec);
return (is_this_valid, left_vec);
}
return (true, vec![]);
}
}
Complexity
- n is the number of node and h is height of tree
Time complexity:
- Worst case: \(O(n^2)\)
- Recursive formula: \( T(n) = T(n-1) + T(1) + cn \)
- For balance tree: \(O(n \log n)\)
- Recursive formula: \( T(n) = 2 \ T(n/2) + cn \)
Auxiliary Space:
- \( O(n) \)
- The size of call stack and list of number are bound by height of the tree and the number of nodes. Also, the height cannot exceed the number of tree nodes.
113. Path Sum II
Description of the Problem
Given the root of a binary tree and an integer targetSum, return all root-to-leaf paths where the sum of the node values in the path equals targetSum. Each path should be returned as a list of the node values, not node references.
A root-to-leaf path is a path starting from the root and ending at any leaf node. A leaf is a node with no children.
Example 1:
Input: root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
Output: [[5,4,11,2],[5,8,4,5]]
Explanation: There are two paths whose sum equals targetSum:
5 + 4 + 11 + 2 = 22
5 + 8 + 4 + 5 = 22
Example 2:
Input: root = [1,2,3], targetSum = 5
Output: []
Example 3:
Input: root = [1,2], targetSum = 0
Output: []
Constraints:
The number of nodes in the tree is in the range [0, 5000].
-1000 <= Node.val <= 1000-1000 <= targetSum <= 1000
Solution
Tags: Permutation and Combination
Explanation
39. Combination Sum explains the approach we used.
Code(Rust)
use std::rc::Rc;
use std::cell::RefCell;
impl Solution {
pub fn path_sum(root: Option<Rc<RefCell<TreeNode>>>, target_sum: i32) -> Vec<Vec<i32>> {
let mut answer = Vec::new();
Self::dfs(root, target_sum, &mut Vec::new(), &mut answer);
answer
}
fn dfs(
node: Option<Rc<RefCell<TreeNode>>>,
target_sum: i32,
v: &mut Vec<i32>,
answer: &mut Vec<Vec<i32>>,
) {
if let Some(n) = node {
let val = n.borrow().val;
let l = n.borrow().left.clone();
let r = n.borrow().right.clone();
v.push(val);
if target_sum == val && l.is_none() && r.is_none() {
answer.push(v.clone());
}
Self::dfs(l, target_sum - val, v, answer);
Self::dfs(r, target_sum - val, v, answer);
v.pop();
}
}
}
Complexity (n is the number of node and h is height of tree)
Time complexity:
- Worst case: \(\Theta(n)\)
- Traverse all nodes
Auxiliary Space:
- \( O(h) \)
- The size of temp array and call stack are bound by the height of the tree
143. Reorder List
Description of Problem
You are given the head of a singly linked-list. The list can be represented as:
L0 → L1 → … → Ln - 1 → Ln
Reorder the list to be on the following form:
L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → …
You may not modify the values in the list's nodes. Only nodes themselves may be changed.
Example 1:
Input: head = [1,2,3,4]
Output: [1,4,2,3]
Example 2:
Input: head = [1,2,3,4,5]
Output: [1,5,2,4,3]
Constraints:
- The number of nodes in the list is in the range
[1, 5 * 10^4]. 1 <= Node.val <= 1000
Solution
Tags: LinkedList
Explanation
Simply speaking, find the middle node using fast and slow pointers, cut the list into two lists, reverse the latter and combine them.
Code (C++)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
void reorderList(ListNode* head) {
ListNode* fast = head;
ListNode* slow = head;
// 1. Find the middle node
while(fast->next != nullptr && fast->next->next != nullptr){
slow = slow->next;
fast = fast->next->next;
}
// 2. Cut and Reverse
ListNode* curr = slow->next;
ListNode* prev = nullptr;
slow->next = nullptr; // Cut
// Reverse
while(curr != nullptr){
ListNode* temp = curr;
curr = temp->next;
temp->next = prev;
prev = temp;
}
// 3. Merge
ListNode* list1 = head; ListNode* list2 = prev;
while(list1 != nullptr && list2 != nullptr){
ListNode* temp1 = list1->next;
ListNode* temp2 = list2->next;
list1->next = list2;
list2->next = temp1;
list1 = temp1;
list2 = temp2;
}
}
};
Complexity
Time Complexity:
- \(T(n)=O(n)\)
- There are only nearly constant number of n iterations
Auxiliary Space:
- \(S(n)=O(1)\)
- Use only constant number of variables
146. LRU Cache
Description of the Problem
Design a data structure that follows the constraints of a Least Recently Used (LRU) cache.
Implement the LRUCache class:
LRUCache(int capacity)Initialize the LRU cache with positive sizecapacity.int get(int key)Return the value of the key if thekeyexists, otherwise return-1.void put(int key, int value)Update the value of thekeyif the key exists. Otherwise, add thekey-valuepair to the cache. If the number of keys exceeds thecapacityfrom this operation, evict the least recently used key.
The functions get and put must each run in O(1) average time complexity.
Example 1:
Input
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
Output
[null, null, null, 1, null, -1, null, -1, 3, 4]
Explanation
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // cache is {1=1}
lRUCache.put(2, 2); // cache is {1=1, 2=2}
lRUCache.get(1); // return 1
lRUCache.put(3, 3); // LRU key was 2, evicts key 2, cache is {1=1, 3=3}
lRUCache.get(2); // returns -1 (not found)
lRUCache.put(4, 4); // LRU key was 1, evicts key 1, cache is {4=4, 3=3}
lRUCache.get(1); // return -1 (not found)
lRUCache.get(3); // return 3
lRUCache.get(4); // return 4
Constraints:
1 <= capacity <= 30000 <= key <= 10^40 <= value <= 10^5- At most
2 * 10^5calls will be made togetandput.
Solution 1 - Simple Idea (Does not meet the requirement)
Explanation
The whole idea is provided by NeetCode's Video:
Double-ended queuestores key-value pairs where the head is the least recently used (LRU) element and the tail is the most recently used (MRU) element.HashMapstores the pointer of nodes of the deque.HashMapprovides constant time insert and query on average.
The following code is just a simplified version of his solution which does not meet the requirement of the problem (The functions get and put must each run in O(1) average time complexity). However, once we implmment double-end queue, the following code can be easily modified in order to meet the requirement.
Code (Rust)
use std::collections::{HashMap, VecDeque};
struct LRUCache{
capacity : usize,
hash_map : HashMap<i32, i32>,
deque : VecDeque<i32>,
}
impl LRUCache {
fn new(capacity: i32) -> LRUCache {
return LRUCache {
capacity : capacity.try_into().unwrap(),
hash_map: HashMap::new(),
deque: VecDeque::new()
};
}
fn get(&mut self, key : i32) -> i32 {
if let Some(&value) = self.hash_map.get(&key) {
self.move_into_back(key);
return value;
}
return -1;
}
fn put(&mut self, key : i32, value: i32) {
if let Some(value_ref) = self.hash_map.get_mut(&key) {
*value_ref = value;
self.move_into_back(key);
return;
}
if self.deque.len() >= self.capacity {
let lru_key = self.deque.pop_front();
if let Some(lru_key) = lru_key {
self.hash_map.remove(&lru_key);
}
}
self.hash_map.insert(key.clone(), value.clone());
self.deque.push_back(key);
}
fn move_into_back(&mut self, key : i32){
let i = self.deque.iter().position(|&x| x == key).unwrap();
self.deque.remove(i);
self.deque.push_back(key);
}
}
Solution 2
Explanation
It is so difficult to implement Safe LinkedList with Rust.
Fortunately, Learn Rust With Entirely Too Many Linked Lists provides good demostration for the implementation of a safe LinkedList (see: A Bad Safe Deque)
The source code of std::collections::LinkedList also provides a very good demostration for LinkedList.
Remember to use Unit Test when implementing these data strctures, it helps you DEBUG :).
Code (Rust)
** For implmentation details of double-end queue, please see Apppendix A1
struct LRUCache {
cache : base::LRUCache<i32, i32>,
}
impl LRUCache {
fn new(capacity: i32) -> Self {
LRUCache {
cache : base::LRUCache::new(capacity as usize)
}
}
fn get(&mut self, key: i32) -> i32 {
self.cache.get(&key).unwrap_or(-1)
}
fn put(&mut self, key: i32, value: i32) {
self.cache.put(key, value);
}
}
mod base {
// -- Snip --
// Please see Appendix A1
}
Complexity
Time Complexity
- get: \(O(1)\)
- put: \(O(1)\)
Auxiliary Space
- get: \(O(1)\)
- put: \(O(1)\)
Appendix A1 - Implementation Details of LRUCache using Safe Deque
//! # Least Recently Used Cache
//! A LRU cache supports Generics with trait bounds.
use std::{hash::Hash, collections::HashMap, cell::RefCell, rc::Rc};
type NodeRef<T> = Rc<RefCell<Node<T>>>;
/// `K` must be `Copy` to remind "callers" that the `K` should be small
/// Otherwise it will be expensive to copy the key.
pub struct LRUCache<K, V>
where
K: Copy + Eq + Hash,
V: Clone
{
capacity: usize,
hash_map: HashMap<K, NodeRef<(K,V)>>,
deque: Deque<(K,V)>,
}
/// The idea of the implementation of this deque mostly comes from the **Learn Rust With Entirely Too Many Linked Lists**
/// see: [A Bad but Safe Doubly-Linked Deque](https://rust-unofficial.github.io/too-many-lists/fourth-final.html)
/// The idea of `unsafe fn unlink_node(&mut self, node: &NodeRef<T>)` comes from the offcial implementation of `std::collections::LinkedList`
struct Deque<T> {
len: usize,
front: Option<NodeRef<T>>,
back: Option<NodeRef<T>>,
}
#[derive(Debug)]
struct Node<T> {
val: T,
prev: Option<NodeRef<T>>,
next: Option<NodeRef<T>>,
}
impl<K, V> LRUCache<K, V>
where
K: Copy + Eq + Hash,
V: Clone
{
pub fn new(capacity: usize) -> Self {
LRUCache {
capacity,
hash_map: HashMap::new(),
deque: Deque::new(),
}
}
pub fn get(&mut self, key: &K) -> Option<V> {
self.hash_map.get_mut(key).map(|node_ref| {
unsafe { self.deque.move_node_into_back(node_ref) };
node_ref.borrow().val.1.clone()
})
}
pub fn put(&mut self, key: K, value: V) {
if let Some(node_ref) = self.hash_map.get_mut(&key) {
unsafe { self.deque.move_node_into_back(node_ref) };
node_ref.borrow_mut().val.1 = value;
return;
}
if self.hash_map.len() >= self.capacity {
let old_node = self.deque.pop_front_node().unwrap();
let old_key = &old_node.borrow().val.0;
self.hash_map.remove(old_key);
}
let node_ref = Deque::create_node_ref((key, value));
self.hash_map.insert(key, node_ref.clone());
unsafe { self.deque.push_back_node(node_ref) };
}
}
impl<T> Deque<T> {
/* "Public" Interfaces */
fn new() -> Self {
Deque {
len: 0,
front: None,
back: None,
}
}
#[allow(dead_code)]
fn push_front(&mut self, val: T) {
let new_front = Self::create_node_ref(val);
// Safety: `new_front` is newly created
unsafe { self.push_front_node(new_front) };
}
#[allow(dead_code)]
fn push_back(&mut self, val: T) {
let new_back = Self::create_node_ref(val);
// Safety: `new_back` is newly created
unsafe { self.push_back_node(new_back) };
}
#[allow(dead_code)]
fn pop_front(&mut self) -> Option<T> {
self.pop_front_node()
.map(|old_front| Rc::try_unwrap(old_front).ok().unwrap().into_inner().val)
}
#[allow(dead_code)]
fn pop_back(&mut self) -> Option<T> {
self.pop_back_node()
.map(|old_back| Rc::try_unwrap(old_back).ok().unwrap().into_inner().val)
}
/* "Private" Auxiliary Functions */
/// # Safety
/// The node must have only one strong reference.
/// It cause problem when the node is popped later otherwise
#[allow(dead_code)]
unsafe fn push_front_node(&mut self, new_front: NodeRef<T>) {
match self.front.take() {
Some(old_front) => {
old_front.borrow_mut().prev = Some(new_front.clone());
new_front.borrow_mut().next = Some(old_front);
new_front.borrow_mut().prev = None;
self.front = Some(new_front);
},
None => {
self.front = Some(new_front.clone());
self.back = Some(new_front);
}
}
self.len += 1;
}
/// # Safety
/// The node must have only one strong reference.
/// It cause problem when the node is popped later otherwise
unsafe fn push_back_node(&mut self, new_back: NodeRef<T>) {
match self.back.take() {
Some(old_back) => {
old_back.borrow_mut().next = Some(new_back.clone());
new_back.borrow_mut().prev = Some(old_back);
new_back.borrow_mut().next = None;
self.back = Some(new_back);
},
None => {
self.back = Some(new_back.clone());
self.front = Some(new_back);
}
}
self.len += 1;
}
fn pop_front_node(&mut self) -> Option<NodeRef<T>> {
self.front.take().map(|old_front| {
match old_front.borrow_mut().next.take() {
Some(new_front) => {
new_front.borrow_mut().prev = None;
self.front = Some(new_front);
},
None => {
self.back = None;
}
}
self.len -= 1;
old_front
})
}
#[allow(dead_code)]
fn pop_back_node(&mut self) -> Option<NodeRef<T>> {
self.back.take().map(|old_back| {
match old_back.borrow_mut().prev.take() {
Some(new_back) => {
new_back.borrow_mut().next = None;
self.back = Some(new_back);
},
None => {
self.front = None;
}
}
self.len -= 1;
old_back
})
}
/// # Safety
/// see reason from the below method
unsafe fn move_node_into_back(&mut self, node: &NodeRef<T>) {
unsafe { self.unlink_node(node) };
self.push_back_node(node.clone());
}
/// # Safety
/// Warning: it does not check whether `node` belongs to the lists.
unsafe fn unlink_node(&mut self, node: &NodeRef<T>) {
let prev = node.borrow_mut().prev.take();
let next = node.borrow_mut().next.take();
if let Some(ref prev) = prev {
prev.borrow_mut().next = next.clone();
} else {
self.front = next.clone();
}
if let Some(ref next) = next {
next.borrow_mut().prev = prev;
} else {
self.back = prev;
}
self.len -= 1;
}
fn create_node_ref(val : T) -> NodeRef<T> {
Rc::new(RefCell::new(Node::new(val)))
}
}
impl<T> Node<T> {
fn new(val: T) -> Self {
Node { val, prev: None, next: None }
}
}
#[cfg(test)]
mod cache_tests{
use crate::LRUCache;
#[test]
fn test_01(){
let mut cache = LRUCache::new(2);
cache.put(1,1);
cache.put(2,2);
assert_eq!(cache.get(&1),Some(1));
cache.put(3,3);
assert_eq!(cache.get(&2),None);
cache.put(4,4);
assert_eq!(cache.get(&1),None);
assert_eq!(cache.get(&3),Some(3));
assert_eq!(cache.get(&4),Some(4));
}
#[test]
fn test_02(){
let mut cache = LRUCache::new(2);
cache.put(1,1);
cache.put(2,2);
assert_eq!(cache.get(&1),Some(1));
cache.put(2,3);
assert_eq!(cache.get(&2),Some(3));
cache.put(2,3);
}
}
#[cfg(test)]
mod deque_tests {
use crate::Deque;
#[test]
fn pop_front_test(){
let mut deque = Deque::<i32>::new();
deque.push_front(3);
deque.push_front(2);
deque.push_front(1);
deque.push_back(4);
deque.push_back(5);
deque.push_back(6);
assert_eq!(deque.pop_front(), Some(1));
assert_eq!(deque.pop_front(), Some(2));
assert_eq!(deque.pop_front(), Some(3));
assert_eq!(deque.pop_front(), Some(4));
assert_eq!(deque.pop_front(), Some(5));
assert_eq!(deque.pop_front(), Some(6));
}
// Pop Back Test
#[test]
fn pop_back_test(){
let mut deque = Deque::<i32>::new();
deque.push_front(3);
deque.push_front(2);
deque.push_front(1);
deque.push_back(4);
deque.push_back(5);
deque.push_back(6);
assert_eq!(deque.pop_back(), Some(6));
assert_eq!(deque.pop_back(), Some(5));
assert_eq!(deque.pop_back(), Some(4));
assert_eq!(deque.pop_back(), Some(3));
assert_eq!(deque.pop_back(), Some(2));
assert_eq!(deque.pop_back(), Some(1));
}
// Push Test
#[test]
fn push_test(){
let mut deque = Deque::<i32>::new();
deque.push_front(3);
deque.push_front(2);
deque.push_front(1);
deque.push_back(4);
deque.push_back(5);
deque.push_back(6);
let mut front = deque.front.clone();
for i in 1..=6 {
if let Some(node) = front.clone() {
let val = node.borrow().val;
assert_eq!(val, i);
} else{
panic!("There should be an element in the list");
}
front = front.and_then(
|rc| {
let rc = rc.borrow();
let rc = rc.next.clone();
rc
}
);
}
let mut back = deque.back.clone();
for i in (1..=6).rev() {
if let Some(node) = back.clone() {
let val = node.borrow().val;
assert_eq!(val, i);
} else{
panic!("There should be an element in the list");
}
back = back.and_then(
|rc| {
let rc = rc.borrow();
let rc = rc.prev.clone();
rc
}
);
}
}
// unlink test
#[test]
fn unlink_test(){
unsafe {
let mut deque = Deque::<i32>::new();
let node_6 = Deque::create_node_ref(6);
let node_5 = Deque::create_node_ref(5);
let node_4 = Deque::create_node_ref(4);
let node_3 = Deque::create_node_ref(3);
let node_2 = Deque::create_node_ref(2);
let node_1 = Deque::create_node_ref(1);
deque.push_front_node(node_3.clone());
deque.push_front_node(node_2);
deque.push_front_node(node_1);
deque.push_back_node(node_4);
deque.push_back_node(node_5);
deque.push_back_node(node_6);
deque.unlink_node(&node_3);
for i in &[1,2,4,5,6] {
let i = *i;
let j = deque.pop_front().unwrap();
assert_eq!(i, j);
}
}
}
}
Appendix A2 - Implementation of LRUCache using std::collections::linked_list::LinkedList
//! # Least Recently Used Cache
//! Using unsafe `LinkedList` from std::collections::linked_list
use std::{collections::HashMap, hash::Hash, marker::PhantomData, ptr::NonNull};
type NodePtr<T> = NonNull<Node<T>>;
pub struct LRUCache<K, V>
where
K: Copy + Eq + Hash,
V: Clone
{
capacity: usize,
hash_map: HashMap<K, NodePtr<(K,V)>>,
deque: LinkedList<(K,V)>,
}
struct LinkedList<T> {
len: usize,
front: Option<NodePtr<T>>,
back: Option<NodePtr<T>>,
_marker: PhantomData<Box<Node<T>>>,
}
#[derive(Debug)]
struct Node<T> {
val: T,
prev: Option<NodePtr<T>>,
next: Option<NodePtr<T>>,
}
impl<K, V> LRUCache<K, V>
where
K: Copy + Eq + Hash,
V: Clone
{
pub fn new(capacity: usize) -> Self {
LRUCache {
capacity,
hash_map: HashMap::new(),
deque: LinkedList::new()
}
}
pub fn get(&mut self, key: &K) -> Option<V> {
self.hash_map.get_mut(key).map(|node_ptr| unsafe {
self.deque.move_node_into_back(*node_ptr);
(*node_ptr.as_ptr()).val.1.clone()
})
}
pub fn put(&mut self, key: K, value: V) {
if let Some(node_ptr) = self.hash_map.get_mut(&key) {
unsafe {
self.deque.move_node_into_back(*node_ptr);
(*node_ptr.as_ptr()).val.1 = value;
return;
}
}
if self.hash_map.len() >= self.capacity {
let old_node = self.deque.pop_front_node().unwrap();
let old_key = (*old_node).val.0;
self.hash_map.remove(&old_key);
}
let node_ptr = LinkedList::create_node_ptr((key, value));
self.hash_map.insert(key, node_ptr.clone());
unsafe { self.deque.push_back_node(node_ptr) };
}
}
// The implementation is copied and modified from `std::collections::linked_list`
impl<T> LinkedList<T> {
fn new() -> Self {
LinkedList {
len: 0,
front: None,
back: None,
_marker: PhantomData,
}
}
#[allow(unused)]
unsafe fn push_front_node(&mut self, node: NonNull<Node<T>>) {
unsafe {
(*node.as_ptr()).next = self.front;
(*node.as_ptr()).prev = None;
let node = Some(node);
match self.front {
None => self.back = node,
Some(front) => (*front.as_ptr()).prev = node,
}
self.front = node;
self.len += 1;
}
}
#[allow(unused)]
unsafe fn push_back_node(&mut self, node: NonNull<Node<T>>) {
unsafe {
(*node.as_ptr()).next = None;
(*node.as_ptr()).prev = self.back;
let node = Some(node);
match self.back {
None => self.front = node,
Some(back) => (*back.as_ptr()).next = node,
}
self.back = node;
self.len += 1;
}
}
fn pop_front_node(&mut self) -> Option<Box<Node<T>>> {
self.front.map(|node| unsafe {
let node = Box::from_raw(node.as_ptr());
self.front = node.next;
match self.front {
None => self.back = None,
Some(front) => (*front.as_ptr()).prev = None,
}
self.len -= 1;
node
})
}
#[allow(unused)]
fn pop_back_node(&mut self) -> Option<Box<Node<T>>> {
self.back.map(|node| unsafe {
let node = Box::from_raw(node.as_ptr());
self.back = node.prev;
match self.back {
None => self.front = None,
Some(back) => (*back.as_ptr()).next = None,
}
self.len -= 1;
node
})
}
/// # Safety
/// see reason from the below method
unsafe fn move_node_into_back(&mut self, node: NodePtr<T>) {
unsafe { self.unlink_node(node) };
self.push_back_node(node.clone());
}
unsafe fn unlink_node(&mut self, mut node: NonNull<Node<T>>) {
let node = unsafe { node.as_mut() };
match node.prev {
Some(prev) => unsafe { (*prev.as_ptr()).next = node.next },
None => self.front = node.next,
};
match node.next {
Some(next) => unsafe { (*next.as_ptr()).prev = node.prev },
None => self.back = node.prev,
};
self.len -= 1;
}
fn create_node_ptr(val: T) -> NodePtr<T> {
let node = Box::leak(Box::new(Node::new(val)));
NonNull::new(node).unwrap()
}
}
impl<T> Node<T> {
fn new(val: T) -> Self {
Node { val, prev: None, next: None }
}
}
#[cfg(test)]
mod cache_tests{
use crate::LRUCache;
#[test]
fn test_01(){
let mut cache = LRUCache::new(2);
cache.put(1,1);
cache.put(2,2);
assert_eq!(cache.get(&1),Some(1));
cache.put(3,3);
assert_eq!(cache.get(&2),None);
cache.put(4,4);
assert_eq!(cache.get(&1),None);
assert_eq!(cache.get(&3),Some(3));
assert_eq!(cache.get(&4),Some(4));
}
#[test]
fn test_02(){
let mut cache = LRUCache::new(2);
cache.put(1,1);
cache.put(2,2);
assert_eq!(cache.get(&1),Some(1));
cache.put(2,3);
assert_eq!(cache.get(&2),Some(3));
cache.put(2,3);
}
}
150. Evaluate Reverse Polish Notation
Description of the Problem
You are given an array of strings tokens that represents an arithmetic expression in a Reverse Polish Notation.
Evaluate the expression. Return an integer that represents the value of the expression.
Note that:
- The valid operators are
'+','-','*', and'/'. - Each operand may be an integer or another expression.
- The division between two integers always truncates toward zero.
- There will not be any division by zero.
- The input represents a valid arithmetic expression in a reverse polish notation.
- The answer and all the intermediate calculations can be represented in a 32-bit integer.
Example 1:
Input: tokens = ["2","1","+","3","*"]
Output: 9
Explanation: ((2 + 1) * 3) = 9
Example 2:
Input: tokens = ["4","13","5","/","+"]
Output: 6
Explanation: (4 + (13 / 5)) = 6
Example 3:
Input: tokens = ["10","6","9","3","+","-11","*","/","*","17","+","5","+"]
Output: 22
Explanation: ((10 * (6 / ((9 + 3) * -11))) + 17) + 5
= ((10 * (6 / (12 * -11))) + 17) + 5
= ((10 * (6 / -132)) + 17) + 5
= ((10 * 0) + 17) + 5
= (0 + 17) + 5
= 17 + 5
= 22
Constraints:
1 <= tokens.length <= 10^4tokens[i]is either an operator:"+","-","*", or"/", or an integer in the range[-200, 200].
Solution
Explanation
Simply speaking, when the token is an number, push into the stack; when the token is an operator, pop two numbers and calculate the result, push the result back to the stack.
Code (Rust)
impl Solution {
pub fn eval_rpn(tokens: Vec<String>) -> i32 {
let mut stack = vec![];
for token in tokens {
match(token.as_str()){
"+" => {
let b = stack.pop().unwrap();
let a = stack.pop().unwrap();
stack.push(a + b);
},
"-" => {
let b = stack.pop().unwrap();
let a = stack.pop().unwrap();
stack.push(a - b);
},
"*" => {
let b = stack.pop().unwrap();
let a = stack.pop().unwrap();
stack.push(a * b);
},
"/" => {
let b = stack.pop().unwrap();
let a = stack.pop().unwrap();
stack.push(a / b);
},
_ => {
stack.push(token.parse::<i32>().unwrap());
},
}
}
if stack.len() != 1{
panic!("Invalid Token");
}else{
return stack.pop().unwrap();
}
}
}
Complexity (n is the number of tokens)
Time Complexity:
- \( O(n) \)
Auxiliary Space:
- \( O(n) \)
- The size of the stack is bound by number of tokens
151. Reverse Words in a String
Description of the Problem
Given an input string s, reverse the order of the words.
A word is defined as a sequence of non-space characters. The words in s will be separated by at least one space.
Return a string of the words in reverse order concatenated by a single space.
Note that s may contain leading or trailing spaces or multiple spaces between two words. The returned string should only have a single space separating the words. Do not include any extra spaces.
Example 1:
Input: s = "the sky is blue"
Output: "blue is sky the"
Example 2:
Input: s = " hello world "
Output: "world hello"
Explanation: Your reversed string should not contain leading or trailing spaces.
Example 3:
Input: s = "a good example"
Output: "example good a"
Explanation: You need to reduce multiple spaces between two words to a single space in the reversed string.
Constraints:
1 <= s.length <= 104scontains English letters (upper-case and lower-case), digits, and spaces ' '.- There is at least one word in
s.
Follow-up: If the string data type is mutable in your language, can you solve it in-place with O(1) extra space?
Solution
Tags: Memory Management
Explanation
Simple Idea:
- To reverse each word in a string, do mirroring to each word and then do mirroring to the whole string.
- To do mirroring for each word, we have to scan each word (using sliding windows, i.e. tokenise)
- The follow-up question requires us to do almost any operations in-place. We can first copy each token to suitable place by sliding windows method. For example,
____ABCbecomesABC_ABC.
Reminder:
- (*) To fullfill the follow-up question, do not create too much copy of the
String. Keep in mind that even if some methods/functions do not havenewkeyword, the code behind these methods/functions may containnewkeyword in their implementation (i.e. they use extra space). For example, in Java,.substring(i, j)will create newStringin Heap. To know more about this, please look at the source code.- Rust provides source code in their offcial website.
- You can also look at the source code of Java via IDE.
- In my opinion, the key idea of the problems is to illistrate you are able to acheive \( O(1) \) conceptually. It is not necessary to implement it so carefully.
"Extra/auxiliary space" in my definition excludes input space and output space
Code (Rust)
impl Solution {
pub fn reverse_words(s: String) -> String {
let space_in_u8 = 32;
// According to RustDoc: "This consumes the `String`, so we do not need to copy its contents"
// i.e. convert it into Vec<u8> costs O(1) Space
let mut v = s.into_bytes();
// i, j for sliding window,
// k is location of cell to be filled-in
let (mut i, mut j, mut k, n) = (0,0,0,v.len());
while j < n {
match (v[i] == space_in_u8, v[j]==space_in_u8){
// Case 1: Sliding window contains only space, move two pointers
(true, true) => {i+=1; j+=1;},
// Impossible case
(true, false) => {panic!("Reaches impossible case");},
// Case 2: sliding window complete the scanning of a word
(false, true) => {
// If the "current result" has some word, append space
if k > 0 {
v[k] = space_in_u8;
k+=1;
}
// v[k..k+j-i] = v[i..j].reverse()
Solution::copy_and_reverse(&mut v, i, j, &mut k);
// reset pointer location by right j by 1, i points to where j locates
j+=1;
i=j;
},
// Case 3: Sliding window contains only characters
// It may not complete the scanning
(false, false) => {
j+=1;
// If j reaches the end of string, do copy_and_reverse
if j == n {
if k > 0 {
v[k] = space_in_u8;
k+=1;
}
Solution::copy_and_reverse(&mut v, i, j, &mut k);
}
}
}
}
v.truncate(k); // cut unnecessary characters
Solution::reverse_string(&mut v, 0, k); // reverse the whole string
// Convert Vec<u8> back to String
// It costs O(1) according to String implmentation (see source code of Rust)
// i.e. give ownership of Vec<u8> to String Struct
return unsafe { String::from_utf8_unchecked(v) };
}
// v[k..k+j-i] = v=[i..j].reverse()
fn copy_and_reverse(v: &mut Vec<u8>, begin: usize, end: usize, k: &mut usize){
let k_origin = *k;
// v[k..k+j-i] = v=[i..j]
for i in (begin..end){
v[*k] = v[i];
*k +=1;
}
Solution::reverse_string(v, k_origin, k_origin+end-begin);
}
// v[k..k+j-i].reverse()
fn reverse_string(v: &mut Vec<u8>, begin: usize, end: usize){
let (mut i, mut j) = (begin, end - 1);
while i < j {
let tmp = v[i];
v[i] = v[j];
v[j] = tmp;
i+=1;
j-=1;
}
}
}
Complexity (\(n\) is length of the string)
Time complexity:
- \( O(2n) \)
- Mirroring the whole string cost \( n / 2 \)
- Copying and mirroring a token cost \( m + m / 2 \) where m is the length of token. Since sum of the length of tokens does not exceed \(n\). The total cost less than \( 3n/2 \)
- The combined complexity is \( O(2n) \)
Auxiliary Space:
- \( O(1) \)
- Depends on Programming Language and implementation
- Conceptually it can acheive O(1) Space
Further Discussion
Tags: Turing Machine
Limitation of a Programming Language and Turing Equivalence(?)
Some people argue that each language has its limitation. For instance, Java cannot actually acheive \(O(1)\) extra space in this problem.
To some extent, I will agree. Theoretically, however, if each programming language simluates Universal Turing Machine, they should be equivalent. This implies that there is no operation Rust can do but Java can't. The only matter is the cost for one language to simulate another. Just like to simulates Two-Tape Turing Machine by the One-Tape, we need more steps/operations in One-Tape Turing Machine.
155. Min Stack
Description of Problem
Design a stack that supports push, pop, top, and retrieving the minimum element in constant time.
Implement the MinStack class:
MinStack()initializes the stack object.void push(int val)pushes the elementvalonto the stack.void pop()removes the element on the top of the stack.int top()gets the top element of the stack.int getMin()retrieves the minimum element in the stack. You must implement a solution withO(1)time complexity for each function.
Example 1:
Input
["MinStack","push","push","push","getMin","pop","top","getMin"]
[[],[-2],[0],[-3],[],[],[],[]]
Output
[null,null,null,null,-3,null,0,-2]
Explanation
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.getMin(); // return -3
minStack.pop();
minStack.top(); // return 0
minStack.getMin(); // return -2
Constraints:
-2^31 <= val <= 2^31 - 1- Methods
pop,topandgetMinoperations will always be called on non-empty stacks. - At most
3 * 10^4calls will be made topush,pop,top, andgetMin.
Solution
Tags: Stack
Explanation
Store the current minimum element on each element in the stack. And therefore, the top of the stack must contain the current minimum number.
Code
struct MinStack {
// (value, min value it knows)
stack : Vec<(i32,i32)>
}
/**
* `&self` means the method takes an immutable reference.
* If you need a mutable reference, change it to `&mut self` instead.
*/
impl MinStack {
fn new() -> Self {
MinStack {
stack: Vec::new()
}
}
fn push(&mut self, val: i32) {
if self.stack. len() > 0 {
self.stack.push((
val, val.min( self.get_min() )
));
} else {
self.stack.push( (val, val));
}
}
fn pop(&mut self) {
assert!(self.stack.len() > 0);
self.stack.pop();
}
fn top(&self) -> i32 {
assert!(self.stack.len() > 0);
let n = self.stack. len();
return self.stack[n - 1].0;
}
fn get_min(&self) -> i32 {
assert! (self.stack.len() > 0);
let n = self.stack. len();
return self.stack[n - 1].1;
}
}
/**
* Your MinStack object will be instantiated and called as such:
* let obj = MinStack::new();
* obj.push(val);
* obj.pop();
* let ret_3: i32 = obj.top();
* let ret_4: i32 = obj.get_min();
*/
Complexity
Time Complexity
- \(T(n) = O(1)\)
Auxiliary Space
- \(S(n) = O(1)\)
167. Two Sum II - Input Array Is Sorted
Description of Problem
Given a 1-indexed array of integers numbers that is already sorted in non-decreasing order, find two numbers such that they add up to a specific target number. Let these two numbers be numbers[index1] and numbers[index2] where 1 <= index1 < index2 <= numbers.length.
Return the indices of the two numbers, index1 and index2, added by one as an integer array [index1, index2] of length 2.
The tests are generated such that there is exactly one solution. You may not use the same element twice.
Your solution must use only constant extra space.
Example 1:
Input: numbers = [2,7,11,15], target = 9
Output: [1,2]
Explanation: The sum of 2 and 7 is 9. Therefore, index1 = 1, index2 = 2. We return [1, 2].
Example 2:
Input: numbers = [2,3,4], target = 6
Output: [1,3]
Explanation: The sum of 2 and 4 is 6. Therefore index1 = 1, index2 = 3. We return [1, 3].
Example 3:
Input: numbers = [-1,0], target = -1
Output: [1,2]
Explanation: The sum of -1 and 0 is -1. Therefore index1 = 1, index2 = 2. We return [1, 2].
Constraints:
2 <= numbers.length <= 3 * 10^4-1000 <= numbers[i] <= 1000numbersis sorted in non-decreasing order.-1000 <= target <= 1000- The tests are generated such that there is exactly one solution.
Solution
Tags: Two Pointers
Explanation
Since the array is sorted, we can use two pointers to find the solution. First, point to the first and last elements. If the sum is too big, move the right pointer to make it smaller and vice versa.
Code (Rust)
impl Solution {
pub fn two_sum(numbers: Vec<i32>, target: i32) -> Vec<i32> {
let (mut i, mut j) = (0, numbers.len() - 1);
loop {
let sum = numbers[i] + numbers[j];
if sum == target {
break;
} else if sum < target {
i+=1;
} else {
j-=1;
}
}
return vec![i as i32 + 1, j as i32 + 1];
}
}
Complexity
Time Complexity
- \( O(n) \)
Auxiliary Space
- \( O(1) \)
176. Second Highest Salary
Description of Problem
Table: Employee
+-------------+------+
| Column Name | Type |
+-------------+------+
| id | int |
| salary | int |
+-------------+------+
id is the primary key (column with unique values) for this table.
Each row of this table contains information about the salary of an employee.
Write a solution to find the second highest salary from the Employee table. If there is no second highest salary, return null (return None in Pandas).
The result format is in the following example.
Example 1:
Input:
Employee table:
+----+--------+
| id | salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
Output:
+---------------------+
| SecondHighestSalary |
+---------------------+
| 200 |
+---------------------+
Example 2:
Input:
Employee table:
+----+--------+
| id | salary |
+----+--------+
| 1 | 100 |
+----+--------+
Output:
+---------------------+
| SecondHighestSalary |
+---------------------+
| null |
+---------------------+
Solution
Tags: SQL Subquery
Code 1 (MySQL) - Using ROW_NUMBER()
-- Write your MySQL query statement below
SELECT IF(MAX(row_num) > 1, t.salary, NULL) AS SecondHighestSalary
FROM (
SELECT ROW_NUMBER() OVER (
ORDER BY e.salary DESC
) AS row_num, COUNT(1) AS row_count, e.salary
FROM Employee e
GROUP BY e.salary
) t
WHERE row_num = 2;
Code 2 - Using plainly subquery (MySQL)
SELECT MAX(salary) AS SecondHighestSalary
FROM Employee
WHERE salary < (SELECT MAX(Salary) FROM Employee)
178. Rank Scores
Description of Problem
Table: Scores
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| score | decimal |
+-------------+---------+
id is the primary key (column with unique values) for this table.
Each row of this table contains the score of a game. Score is a floating point value with two decimal places.
Write a solution to find the rank of the scores. The ranking should be calculated according to the following rules:
- The scores should be ranked from the highest to the lowest.
- If there is a tie between two scores, both should have the same ranking.
- After a tie, the next ranking number should be the next consecutive integer value. In other words, there should be no holes between ranks.
Return the result table ordered by
scorein descending order.
The result format is in the following example.
Example 1:
Input:
Scores table:
+----+-------+
| id | score |
+----+-------+
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
+----+-------+
Output:
+-------+------+
| score | rank |
+-------+------+
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
+-------+------+
Solution
Tags: SQL DENSE_RANK()
Code
SELECT
score,
DENSE_RANK() OVER (ORDER BY score DESC) AS `rank`
FROM Scores
ORDER BY score DESC;
177. Nth Highest Salary
Description of Problem
Table: Employee
+-------------+------+
| Column Name | Type |
+-------------+------+
| id | int |
| salary | int |
+-------------+------+
id is the primary key (column with unique values) for this table.
Each row of this table contains information about the salary of an employee.
Write a solution to find the nth highest salary from the Employee table. If there is no nth highest salary, return null.
The result format is in the following example.
Example 1:
Input:
Employee table:
+----+--------+
| id | salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
n = 2
Output:
+------------------------+
| getNthHighestSalary(2) |
+------------------------+
| 200 |
+------------------------+
Example 2:
Input:
Employee table:
+----+--------+
| id | salary |
+----+--------+
| 1 | 100 |
+----+--------+
n = 2
Output:
+------------------------+
| getNthHighestSalary(2) |
+------------------------+
| null |
+------------------------+
Solution
Tags: SQL
Code (MySQL)
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
SET N=N-1;
RETURN (
SELECT DISTINCT salary
FROM Employee
ORDER BY salary DESC
LIMIT 1 OFFSET N
);
END
179. Largest Number
Description of the Problem
Given a list of non-negative integers nums, arrange them such that they form the largest number and return it.
Since the result may be very large, so you need to return a string instead of an integer.
Example 1:
Input: nums = [10,2]
Output: "210"
Example 2:
Input: nums = [3,30,34,5,9]
Output: "9534330"
Constraints:
- 1 <= nums.length <= 100
- 0 <= nums[i] <= 10^9
Solution
Tags: Greedy
Explanation
Greediness of the Problem
Greedy-choice Properties
To acheive the largest number, we have to choose the most signficant digits that make the whole number largest. And
to choose the most signficant digits, simply pick the number in nums such that their "concatenation" is the largest.
For example, in [3,30,34,5,9], 9 is the suitable choice because:
- 9 3 _ > 3 9 _
- 9 3 0 > 3 0 9
- 9 3 4 > 3 4 9
- 9 5 _ > 5 9 _
i.e. If 9 is in position of the most signficant digits, the whole number is the largest.
Thus, before choosing numbers, we can sort the nums by their "concatenation value" in descending order.
Optimal Substructure Properties
After choosing the most signficant digits, the remaining problem is to find most signficant digits for remaining positions of the whole number.
Code (Rust)
impl Solution {
pub fn largest_number(mut nums: Vec<i32>) -> String {
nums
.sort_by(
|a,b| format!("{}", b)
.cmp(
&format!("{}", a)
)
);
nums.into_iter()
.fold(
String::from(""),
|mut acc, x|
if acc == "0" {
x.to_string()
}
else {
acc.push_str(&x.to_string());
acc
}
)
}
}
Complexity (\(n\) is length of the array)
Time complexity:
- \( O(n \lg n) \)
- For any Greedy algorithm, \( O(n \lg n + f(n) ) \) is its time complexity where \( f(n) \) is the time to check whether the current choice match the requirement of the problem (Technically, it is to check whether the choice makes an Independent Set, see Wikipedia: Matroid). Since, any concatenation of numbers makes valid number, in this case \( f(n) = O(1) \)
Auxiliary Space:
- \( O(n \lg n) \)
- My implementation creates \( O(n \lg n) \)
Stringfor numerical comparison in total although they are create temporarily anddropquickly after comparison.
- My implementation creates \( O(n \lg n) \)
180. Consecutive Numbers
Description of Problem
Table: Logs
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| num | varchar |
+-------------+---------+
In SQL, id is the primary key for this table.
id is an autoincrement column.
Find all numbers that appear at least three times consecutively.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Logs table:
+----+-----+
| id | num |
+----+-----+
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 1 |
| 6 | 2 |
| 7 | 2 |
+----+-----+
Output:
+-----------------+
| ConsecutiveNums |
+-----------------+
| 1 |
+-----------------+
Explanation: 1 is the only number that appears consecutively for at least three times.
Solution
Tags: SQL
Explanation
Combine left-shifted rows, right-shifted rows and original rows. Return unique rows that have the same value.
For example:
Origin: [1 1 1 2 1 2 2]
Left-shifted: [1 1 2 1 2 2 x]
Right-shifted: [x 1 1 1 2 1 2]
----------------------------------
Result: [x 1 x x x x x]
Code (MySQL)
SELECT DISTINCT l1.Num AS ConsecutiveNums
FROM Logs l1
INNER JOIN Logs l2
ON l1.Id = l2.Id - 1 AND l1.Num = l2.Num
INNER JOIN Logs l3
ON l2.Id = l3.Id - 1 AND l2.Num = l3.Num;
184. Department Highest Salary
Description of Problem
Table: Employee
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| id | int |
| name | varchar |
| salary | int |
| departmentId | int |
+--------------+---------+
id is the primary key (column with unique values) for this table.
departmentId is a foreign key (reference columns) of the ID from the Department table.
Each row of this table indicates the ID, name, and salary of an employee. It also contains the ID of their department.
Table: Department
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| name | varchar |
+-------------+---------+
id is the primary key (column with unique values) for this table. It is guaranteed that department name is not NULL.
Each row of this table indicates the ID of a department and its name.
Write a solution to find employees who have the highest salary in each of the departments.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Employee table:
+----+-------+--------+--------------+
| id | name | salary | departmentId |
+----+-------+--------+--------------+
| 1 | Joe | 70000 | 1 |
| 2 | Jim | 90000 | 1 |
| 3 | Henry | 80000 | 2 |
| 4 | Sam | 60000 | 2 |
| 5 | Max | 90000 | 1 |
+----+-------+--------+--------------+
Department table:
+----+-------+
| id | name |
+----+-------+
| 1 | IT |
| 2 | Sales |
+----+-------+
Output:
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Jim | 90000 |
| Sales | Henry | 80000 |
| IT | Max | 90000 |
+------------+----------+--------+
Explanation: Max and Jim both have the highest salary in the IT department and Henry has the highest salary in the Sales department.
Solution
Tags: SQL Joins
Code (MySQL)
-- Write your MySQL query statement below
SELECT t2.Department, e1.name AS Employee, t2.max_salary AS salary
FROM Employee e1
INNER JOIN (
-- Get the maximum salary of each department
SELECT MAX(salary) AS max_salary, d.id AS departmentId, d.name AS Department
FROM Employee e
-- Get the Department Name
INNER JOIN Department d
ON d.id = e.departmentId
GROUP BY d.Id, d.name
) t2
ON e1.salary = t2.max_salary
AND e1.departmentId = t2.departmentId
;
198. House Robber
Description of Problem
You are a professional robber planning to rob houses along a street. Each house has a certain amount of money stashed, the only constraint stopping you from robbing each of them is that adjacent houses have security systems connected and it will automatically contact the police if two adjacent houses were broken into on the same night.
Given an integer array nums representing the amount of money of each house, return the maximum amount of money you can rob tonight without alerting the police.
Example 1:
Input: nums = [1,2,3,1]
Output: 4
Explanation: Rob house 1 (money = 1) and then rob house 3 (money = 3).
Total amount you can rob = 1 + 3 = 4.
Example 2:
Input: nums = [2,7,9,3,1]
Output: 12
Explanation: Rob house 1 (money = 2), rob house 3 (money = 9) and rob house 5 (money = 1).
Total amount you can rob = 2 + 9 + 1 = 12.
Constraints:
1 <= nums.length <= 1000 <= nums[i] <= 400
Solution
Tags: Dynamic Programming
Explanation
Let \(S_i\) be maximum gain when house 0 to house i(inclusively) are available.
\[
\begin{align}
S_0 & = nums[0] \\
S_1 & = \max(nums[0], nums[1]) \\
S_i & = \max( nums[i] + S_{i-2}, S_{i-1} ) \\
\end{align}
\]
Explanation for the third equation, there are two cases when you consider robbing house i:
- If we rob house
i, housei-1is not avilable. The gain is thenums[i]plus the previous two maximum gain \(S_{i-2}\). - If we do not rob house
i, we can only consider house0to housei-1.
Code
impl Solution {
pub fn rob(nums: Vec<i32>) -> i32 {
let n = nums.len();
let mut s = vec![0 ; n];
s[0] = nums[0];
if n > 1 {
s[1] = nums[0].max(nums[1]);
}
for i in 2..n {
s[i] = s[i-1].max(nums[i] + s[i-2])
}
return s[n - 1];
}
}
Complexity
- n is length of
nums
Time Complexity
- \( S(n) = \Theta(n) \)
Auxiliary Space
- \( S(n) = O(n) \)
199. Binary Tree Right Side View
Description of Problem
Given the root of a binary tree, imagine yourself standing on the right side of it, return the values of the nodes you can see ordered from top to bottom.
Example 1:
Input: root = [1,2,3,null,5,null,4]
Output: [1,3,4]
Example 2:
Input: root = [1,null,3]
Output: [1,3]
Example 3:
Input: root = []
Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 100]. -100 <= Node.val <= 100
Solution
Tags: Breadth First Search
Explanation
Use two queues to store tree nodes while performing breadth-first search:
queue1stores tree nodes are ready to be explored.queue2stores tree nodes being appended during BFS.
Perform BFS while queue1 is not empty:
- Read the last node (the right most) in
queue1 - For each node in
queue1, append its left node and right node in order intoqueue2. - At the end of an iteration, exchange two queues.
Code (Rust)
// Definition for a binary tree node.
// #[derive(Debug, PartialEq, Eq)]
// pub struct TreeNode {
// pub val: i32,
// pub left: Option<Rc<RefCell<TreeNode>>>,
// pub right: Option<Rc<RefCell<TreeNode>>>,
// }
//
// impl TreeNode {
// #[inline]
// pub fn new(val: i32) -> Self {
// TreeNode {
// val,
// left: None,
// right: None
// }
// }
// }
use std::rc::Rc;
use std::cell::RefCell;
use std::collections::VecDeque;
impl Solution {
pub fn right_side_view(root: Option<Rc<RefCell<TreeNode>>>) -> Vec<i32> {
let mut queue1 = VecDeque::new();
let mut queue2 = VecDeque::new();
let mut ans = vec![];
if let Some(node) = root{
queue1.push_back(Some(node));
}
while !queue1.is_empty(){
if let Some(&Some(ref node)) = queue1.back(){
let node = node.borrow();
ans.push(node.val);
}
while let Some(Some(node)) = queue1.pop_front(){
let node = node.borrow();
if let Some(left) = node.left.clone(){
queue2.push_back(Some(left));
}
if let Some(right) = node.right.clone(){
queue2.push_back(Some(right));
}
}
let temp = queue1;
queue1 = queue2;
queue2 = temp;
}
return ans;
}
}
Complexity
- n is the number of nodes in tree
- h is the height of tree
Time Complexity
- \( T(n) = \Theta(n) \)
Auxiliary Space
- \( S(h) = O(2^h) \)
200. Number of Islands
Description of Problem
Given an m x n 2D binary grid grid which represents a map of '1's (land) and '0's (water), return the number of islands.
An island is surrounded by water and is formed by connecting adjacent lands horizontally or vertically. You may assume all four edges of the grid are all surrounded by water.
Example 1:
Input: grid = [
["1","1","1","1","0"],
["1","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"]
]
Output: 1
Example 2:
Input: grid = [
["1","1","0","0","0"],
["1","1","0","0","0"],
["0","0","1","0","0"],
["0","0","0","1","1"]
]
Output: 3
Constraints:
m == grid.lengthn == grid[i].length1 <= m, n <= 300grid[i][j]is'0'or'1'.
Solution
Tags: Depth First Search
Explanation
We use the same manner in 547. Number of Provinces.
Code (Rust)
#[derive(Clone, Copy, Debug, PartialEq)]
enum Colour{
White,
Gray,
Black,
}
use Colour::{White, Gray, Black};
impl Solution {
pub fn num_islands(grid: Vec<Vec<char>>) -> i32 {
let m = grid.len();
let n = grid[0].len();
let mut count = 0;
let mut colours = vec![ vec![White; n] ; m];
for i in 0..m {
for j in 0..n{
if grid[i][j] == '1' && colours[i][j] == White {
Self::dfs((i,j), &grid, &mut colours);
count+=1;
}
}
}
return count;
}
fn dfs(node : (usize, usize), grid : &Vec<Vec<char>>, colours : &mut Vec<Vec<Colour>>) {
let m = grid.len();
let n = grid[0].len();
let (i, j) = node;
colours[i][j] = Gray;
if Self::is_available(&grid, &colours, i-1, j, m, n) {
colours[i-1][j] = Gray;
Self::dfs((i-1,j), grid, colours);
}
// LEFT
if Self::is_available(&grid, &colours, i, j-1, m, n) {
colours[i][j-1] = Gray;
Self::dfs((i,j-1), grid, colours);
}
// RIGHT
if Self::is_available(&grid, &colours, i, j+1, m, n) {
colours[i][j+1] = Gray;
Self::dfs((i,j+1), grid, colours);
}
// BOTTOM
if Self::is_available(&grid, &colours, i+1, j, m, n) {
colours[i+1][j] = Gray;
Self::dfs((i+1,j), grid, colours);
}
colours[i][j] = Black;
}
#[inline(always)]
fn is_available(
grid: &Vec<Vec<char>>,
colours : &Vec<Vec<Colour>>,
i : usize,
j : usize,
m : usize,
n : usize
) -> bool {
return
0 <= i && i < m
&& 0 <= j && j < n
&& grid[i][j] == '1'
&& colours[i][j] == White
;
}
}
Complexity
Time Complexity
- \( T(m,n) = O(m \cdot n) \)
Auxiliary Space
- \( S(m,n) = O(\min(m,n)) \)
207. Course Schedule
Description of Problem
There are a total of numCourses courses you have to take, labeled from 0 to numCourses - 1. You are given an array prerequisites where prerequisites[i] = [ai, bi] indicates that you must take course b_i first if you want to take course a_i.
For example, the pair [0, 1], indicates that to take course 0 you have to first take course 1.
Return true if you can finish all courses. Otherwise, return false.
Example 1:
Input: numCourses = 2, prerequisites = [[1,0]]
Output: true
Explanation: There are a total of 2 courses to take.
To take course 1 you should have finished course 0. So it is possible.
Example 2:
Input: numCourses = 2, prerequisites = [[1,0],[0,1]]
Output: false
Explanation: There are a total of 2 courses to take.
To take course 1 you should have finished course 0, and to take course 0 you should also have finished course 1. So it is impossible.
Constraints:
1 <= numCourses <= 20000 <= prerequisites.length <= 5000prerequisites[i].length == 20 <= a_i, b_i < numCourses- All the pairs prerequisites[i] are unique.
Solution
Tags: Graph Theory
Explanation
The method is the same as 210. Course Schedule II. By topological sorting, we can detect the cycle in the graph.
Code (Rust)
use std::collections::HashMap;
impl Solution {
pub fn can_finish(num_courses: i32, prerequisites: Vec<Vec<i32>>) -> bool {
let num_courses = num_courses as usize;
let mut adj_list : Vec<Vec<usize>> = vec![ vec![] ; num_courses ];
let mut is_gray : Vec<bool> = vec![false; num_courses];
let mut is_black : Vec<bool> = vec![false; num_courses];
for p in prerequisites.into_iter(){
let (c1, c2) = (p[1] as usize, p[0] as usize);
adj_list[c1].push(c2);
}
let mut has_loop = false;
for vertex in (0..num_courses) {
if !is_black[vertex] && !is_gray[vertex] && !has_loop {
has_loop = Self::visit(vertex, &adj_list, &mut is_gray, &mut is_black);
}
}
!has_loop
}
fn visit(
vertex : usize,
adj_list : &Vec<Vec<usize>>,
is_gray : &mut Vec<bool>,
is_black : &mut Vec<bool>
) -> bool {
for &v in adj_list[vertex].iter() {
match (is_black[v], is_gray[v]){
(false, false) => {
is_gray[v] = true;
if Self::visit(v, adj_list, is_gray, is_black) == true {
return true;
}
is_gray[v] = false;
}
(false, true) => return true,
_ => {}
}
}
is_black[vertex] = true;
return false;
}
}
208. Implement Trie (Prefix Tree)
Description of Problem
A trie (pronounced as "try") or prefix tree is a tree data structure used to efficiently store and retrieve keys in a dataset of strings. There are various applications of this data structure, such as autocomplete and spellchecker.
Implement the Trie class:
Trie()Initializes the trie object.void insert(String word)Inserts the stringwordinto the trie.boolean search(String word)Returnstrueif the stringwordis in the trie (i.e., was inserted before), andfalseotherwise.boolean startsWith(String prefix)Returnstrueif there is a previously inserted stringwordthat has the prefix prefix, andfalseotherwise.
Example 1:
Input
["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
[[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
Output
[null, null, true, false, true, null, true]
Explanation
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // return True
trie.search("app"); // return False
trie.startsWith("app"); // return True
trie.insert("app");
trie.search("app"); // return True
Constraints:
1 <= word.length, prefix.length <= 2000wordandprefixconsist only of lowercase English letters.- At most
3 * 10^4calls in total will be made toinsert,search, andstartsWith.
Solution 1 - using HashMap with Lazy Initialisation
Tags: Trie
Code
import java.util.HashMap;
import java.util.Map;
class Trie {
private Map<Character,Trie> children;
private boolean isLastChar;
public Trie() {
this.children = null;
this.isLastChar = false;
}
public Trie(boolean isLastChar) {
this.children = null;
this.isLastChar = isLastChar;
}
public boolean isLastChar(){
return this.isLastChar;
}
public void setIsLastChar(boolean isLastChar){
this.isLastChar = isLastChar;
}
public void insert(String word) {
Trie curr = this;
int n = word.length();
for (int i = 0; curr != null && i < n; i++){
if (curr.children == null){
curr.children = new HashMap();
}
Trie next = curr.children.get(word.charAt(i));
if ( next == null ){
Trie next_children = new Trie(i == n - 1 ? true: false);
curr.children.put(word.charAt(i), next_children);
curr = next_children;
}else {
if (i == n - 1) {next.setIsLastChar(true);}
curr = next;
}
}
}
public boolean search(String word) {
Trie curr = this;
int n = word.length();
for (int i = 0; curr != null && i < n; i++){
Trie next = curr.children != null ? curr.children.get(word.charAt(i)) : null;
if ( next == null ){
return false;
}else {
curr = next;
}
}
return curr != null ? curr.isLastChar() : false;
}
public boolean startsWith(String prefix) {
Trie curr = this;
int n = prefix.length();
for (int i = 0; i < n; i++){
Trie next = curr.children != null ? curr.children.get(prefix.charAt(i)) : null;
if ( next == null ){
return false;
}else {
curr = next;
}
}
return curr != null ? true : false;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/
Solution 2 - using Array
Tags: Trie
Code
class Trie {
private Trie[] children;
private boolean isLastChar;
public Trie() {
this.children = new Trie[26];
this.isLastChar = false;
}
public Trie(boolean isLastChar) {
this.children = new Trie[26];
this.isLastChar = isLastChar;
}
public boolean isLastChar(){
return this.isLastChar;
}
public void setIsLastChar(boolean isLastChar){
this.isLastChar = isLastChar;
}
public void insert(String word) {
Trie curr = this;
int n = word.length();
for (int i = 0; curr != null && i < n; i++){
Trie next = curr.children[word.charAt(i) - 'a'];
if ( next == null ){
Trie next_children = new Trie(i == n - 1 ? true: false);
curr.children[word.charAt(i) - 'a'] = next_children;
curr = next_children;
}else {
if (i == n - 1) {next.setIsLastChar(true);}
curr = next;
}
}
}
public boolean search(String word) {
Trie curr = this;
int n = word.length();
for (int i = 0; curr != null && i < n; i++){
Trie next = curr.children[word.charAt(i) - 'a'];
if ( next == null ){
return false;
}else {
curr = next;
}
}
return curr != null ? curr.isLastChar() : false;
}
public boolean startsWith(String prefix) {
Trie curr = this;
int n = prefix.length();
for (int i = 0; i < n; i++){
Trie next = curr.children[prefix.charAt(i) - 'a'];
if ( next == null ){
return false;
}else {
curr = next;
}
}
return curr != null ? true : false;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/
Solution 3 - using Array with Lazy initialisation
Tags: Trie
It does not consume less RAM however.
Code
class Trie {
private Trie[] children;
private boolean isLastChar;
public Trie() {
this.children = null;
this.isLastChar = false;
}
public Trie(boolean isLastChar) {
this.children = null;
this.isLastChar = isLastChar;
}
public boolean isLastChar(){
return this.isLastChar;
}
public void setIsLastChar(boolean isLastChar){
this.isLastChar = isLastChar;
}
public void insert(String word) {
Trie curr = this;
int n = word.length();
for (int i = 0; curr != null && i < n; i++){
if (curr.children == null) {
curr.children = new Trie[26];
}
Trie next = curr.children == null ? null : curr.children[word.charAt(i) - 'a'];
if ( next == null ){
Trie next_children = new Trie(i == n - 1 ? true: false);
curr.children[word.charAt(i) - 'a'] = next_children;
curr = next_children;
}else {
if (i == n - 1) {next.setIsLastChar(true);}
curr = next;
}
}
}
public boolean search(String word) {
Trie curr = this;
int n = word.length();
for (int i = 0; curr != null && i < n; i++){
Trie next = curr.children == null ? null : curr.children[word.charAt(i) - 'a'];
if ( next == null ){
return false;
}else {
curr = next;
}
}
return curr != null ? curr.isLastChar() : false;
}
public boolean startsWith(String prefix) {
Trie curr = this;
int n = prefix.length();
for (int i = 0; i < n; i++){
Trie next = curr.children == null ? null : curr.children[prefix.charAt(i) - 'a'];
if ( next == null ){
return false;
}else {
curr = next;
}
}
return curr != null ? true : false;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/
210. Course Schedule II
Description of the Problem
There are a total of numCourses courses you have to take, labeled from 0 to numCourses - 1. You are given an array prerequisites where prerequisites[i] = [a_i, b_i] indicates that you must take course bi first if you want to take course a_i.
- For example, the pair
[0, 1], indicates that to take course0you have to first take course1.
Return the ordering of courses you should take to finish all courses. If there are many valid answers, return any of them. If it is impossible to finish all courses, return an empty array.
Example 1:
Input: numCourses = 2, prerequisites = [[1,0]]
Output: [0,1]
Explanation: There are a total of 2 courses to take. To take course 1 you should have finished course 0. So the correct course order is [0,1].
Example 2:
Input: numCourses = 4, prerequisites = [[1,0],[2,0],[3,1],[3,2]]
Output: [0,2,1,3]
Explanation: There are a total of 4 courses to take. To take course 3 you should have finished both courses 1 and 2. Both courses 1 and 2 should be taken after you finished course 0.
So one correct course order is [0,1,2,3]. Another correct ordering is [0,2,1,3].
Example 3:
Input: numCourses = 1, prerequisites = []
Output: [0]
Constraints:
1 <= numCourses <= 20000 <= prerequisites.length <= numCourses * (numCourses - 1)prerequisites[i].length == 20 <= a_i, b_i < numCoursesa_i != b_i- All the pairs
[a_i, b_i]are distinct.
Solution
Tags: Graph Theory
Explanation
To get the proper order of courses, we use Depth First Search to do Topological Sorting. For the detailed explanation. Please see Introduction to Algorithms (CLRS) 3rd Ed. (Section 22.4)
Code (Rust)
use std::collections::{HashMap, VecDeque};
impl Solution {
pub fn find_order(num_courses: i32, prerequisites: Vec<Vec<i32>>) -> Vec<i32> {
let num_courses = num_courses as usize;
let mut adj_list : Vec<Vec<usize>> = vec![ vec![] ; num_courses ];
let mut is_gray : Vec<bool> = vec![false; num_courses];
let mut is_black : Vec<bool> = vec![false; num_courses];
let mut order : VecDeque<i32> = VecDeque::new();
for p in prerequisites.into_iter(){
let (c1, c2) = (p[1] as usize, p[0] as usize);
adj_list[c1].push(c2);
}
let mut has_loop = false;
for vertex in (0..num_courses) {
if !is_black[vertex] && !is_gray[vertex] && !has_loop {
has_loop = Self::visit(vertex, &adj_list, &mut is_gray, &mut is_black, &mut order);
}
}
if !has_loop { order.into_iter().collect::<Vec<i32>>() } else { vec![] }
}
fn visit(
vertex : usize,
adj_list : &Vec<Vec<usize>>,
is_gray : &mut Vec<bool>,
is_black : &mut Vec<bool>,
order : &mut VecDeque<i32>
) -> bool {
for &v in adj_list[vertex].iter() {
match (is_black[v], is_gray[v]){
(false, false) => {
is_gray[v] = true;
if Self::visit(v, adj_list, is_gray, is_black, order) == true {
return true;
}
is_gray[v] = false;
}
(false, true) => return true,
_ => {}
}
}
is_black[vertex] = true;
order.push_front(vertex as i32);
return false;
}
}
215. Kth Largest Element in an Array
Description of Problem
Given an integer array nums and an integer k, return the kth largest element in the array.
Note that it is the kth largest element in the sorted order, not the kth distinct element.
Can you solve it without sorting?
Example 1:
Input: nums = [3,2,1,5,6,4], k = 2
Output: 5
Example 2:
Input: nums = [3,2,3,1,2,4,5,5,6], k = 4
Output: 4
Constraints:
1 <= k <= nums.length <= 10^5-10^4 <= nums[i] <= 10^4
Solution
Tags: Heap
Explanation
Use a bounded-sized min-heap to store element and pop the top element when the size of heap is greater than k.
Code (Rust)
impl Solution {
pub fn find_kth_largest(nums: Vec<i32>, k: i32) -> i32 {
use std::collections::BinaryHeap;
use std::cmp::Reverse;
let mut heap = BinaryHeap::new();
let k = k as usize;
for n in nums.into_iter(){
heap.push(Reverse(n));
if heap.len() > k {
heap.pop();
}
}
return heap
.pop()
.expect("Should have at least one element in heap")
.0;
}
}
Complexity
- n is length of
nums
Time Complexity
- \( T(n,k) = \Theta( n \cdot (\lg k + 1) ) \)
Auxiliary Space
- \( S(n,k) = \Theta( k ) \)
216. Combination Sum III
Description of Problem
Find all valid combinations of k numbers that sum up to n such that the following conditions are true:
- Only numbers
1through9are used. - Each number is used at most once. Return a list of all possible valid combinations. The list must not contain the same combination twice, and the combinations may be returned in any order.
Example 1:
Input: k = 3, n = 7
Output: [[1,2,4]]
Explanation:
1 + 2 + 4 = 7
There are no other valid combinations.
Example 2:
Input: k = 3, n = 9
Output: [[1,2,6],[1,3,5],[2,3,4]]
Explanation:
1 + 2 + 6 = 9
1 + 3 + 5 = 9
2 + 3 + 4 = 9
There are no other valid combinations.
Example 3:
Input: k = 4, n = 1
Output: []
Explanation: There are no valid combinations.
Using 4 different numbers in the range [1,9], the smallest sum we can get is 1+2+3+4 = 10 and since 10 > 1, there are no valid combination.
Constraints:
2 <= k <= 91 <= n <= 60
Solution
Tags: Backtracking Divide and Conquer
Explanation
For any candidate number, either use it or not to use.
Code (Rust)
impl Solution {
pub fn combination_sum3(k: i32, n: i32) -> Vec<Vec<i32>> {
let mut ans = vec![];
let mut current_selection = vec![];
Self::helper(&[1,2,3,4,5,6,7,8,9], n, k as usize, &mut current_selection, &mut ans);
return ans;
}
fn helper(
candidates : &[i32],
target: i32,
k : usize,
current_selection: &mut Vec<i32>,
ans: &mut Vec<Vec<i32>>
) {
// Meet the target
if target == 0 && current_selection.len() == k{
// Append Answer
ans.push(current_selection.clone());
// Do not have any candidate or current sum exceed the target
}else if candidates.len() == 0 || target < 0 {
return;
}else {
// Select the first candidate and then calculate the result
current_selection.push(candidates[0]);
Solution::helper(
&candidates[1..],
target - candidates[0],
k,
current_selection,
ans
);
current_selection.pop();
// Skip the first candidate and then calculate the result
Solution::helper(
&candidates[1..],
target,
k,
current_selection,
ans
);
}
}
}
237. Delete Node in a Linked List
Description of the Problem
There is a singly-linked list head and we want to delete a node node in it.
You are given the node to be deleted node. You will not be given access to the first node of head.
All the values of the linked list are unique, and it is guaranteed that the given node node is not the last node in the linked list.
Delete the given node. Note that by deleting the node, we do not mean removing it from memory. We mean:
- The value of the given node should not exist in the linked list.
- The number of nodes in the linked list should decrease by one.
- All the values before
nodeshould be in the same order. - All the values after
nodeshould be in the same order.
Custom testing:
- For the input, you should provide the entire linked list
headand the node to be givennode.nodeshould not be the last node of the list and should be an actual node in the list. - We will build the linked list and pass the node to your function.
- The output will be the entire list after calling your function.
Example 1:
Input: head = [4,5,1,9], node = 5
Output: [4,1,9]
Explanation: You are given the second node with value 5, the linked list should become 4 -> 1 -> 9 after calling your function.
Example 2:
Input: head = [4,5,1,9], node = 1
Output: [4,5,9]
Explanation: You are given the third node with value 1, the linked list should become 4 -> 5 -> 9 after calling your function.
Constraints:
- The number of the nodes in the given list is in the range
[2, 1000]. -1000 <= Node.val <= 1000The value of each node in the list is unique. Thenodeto be deleted is in the list and is not a tail node.
Solution
Code (Java)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public void deleteNode(ListNode node) {
if(node != null){
node.val = node.next.val;
node.next = node.next.next;
}
}
}
238. Product of Array Except Self
Description of Problem
Given an integer array nums, return an array answer such that answer[i] is equal to the product of all the elements of nums except nums[i].
The product of any prefix or suffix of nums is guaranteed to fit in a 32-bit integer.
You must write an algorithm that runs in O(n) time and without using the division operation.
Example 1:
Input: nums = [1,2,3,4]
Output: [24,12,8,6]
Example 2:
Input: nums = [-1,1,0,-3,3]
Output: [0,0,9,0,0]
Constraints:
2 <= nums.length <= 105-30 <= nums[i] <= 30- The product of any prefix or suffix of
numsis guaranteed to fit in a 32-bit integer.
Follow up: Can you solve the problem in O(1) extra Auxiliary Space? (The output array does not count as extra space for Auxiliary Space analysis.)
Solution
Tags: Prefix Sum
Explanation
Without consideration of division, we can express the answer by the following equations \[ f(x_i) = X_{0..i} \cdot X_{(i+1)..n} \text{ where } X_{i..j} = \prod_{k=i}^{j-1} x_k \text{ and } x_k \text{ is element in the array with index k}\]
By observation, \(X_{0..i}\) is the product of prefixes of \(x_i\) and \(X_{(i+1)..n}\) is the product of suffixes of \(x_i\).
For Prefixes: \[ \begin{matrix} \left [ x_0, x_1, ... ,x_{n-2} ,x_{n-1} \right ] & \longrightarrow & \left [ 1, x_0, ... ,x_{n-3} ,x_{n-2} \right ] \\ & \longrightarrow & \left [ 1, x_0, ... ,\prod_{k=0}^{n-3} x_k, \prod_{k=0}^{n-2} x_k \right ] \\ & \longrightarrow & \left [ 1, X_{0..1}, ... ,X_{0..n-2}, X_{0..n-1} \right ] \end{matrix} \]
For Suffixes: \[ \begin{matrix} \left [ x_0, x_1, ... ,x_{n-2} ,x_{n-1} \right ] & \longrightarrow & \left [ x_1, x_2, ... ,x_{n-1} ,1 \right ] \\ & \longrightarrow & \left [ \prod_{k=1}^{n-1} x_k, \prod_{k=2}^{n-1} x_k, ... ,\prod_{k=n-1}^{n-1} x_k, 1 \right ] \\ & \longrightarrow & \left [ X_{1..n}, X_{2..n}, ... , X_{n-1..n}, 1 \right ] \end{matrix} \]
And combine the prefixes and suffixes into single result.
Code (Rust)
impl Solution {
pub fn product_except_self(nums: Vec<i32>) -> Vec<i32> {
let n = nums.len();
let mut result = vec![1; n];
let (mut left_state, mut right_state) = (1, 1);
for i in 0..n {
result[i] *= left_state;
left_state *= nums[i];
result[n - i - 1] *= right_state;
right_state *= nums[n - i - 1];
}
return result;
}
}
Complexity
- n is number of elements in the array
Time complexity:
- \(\Theta(n)\)
Auxiliary Space:
- \(O(1)\)
279. Perfect Squares
Description of Problem
Given an integer n, return the least number of perfect square numbers that sum to n.
A perfect square is an integer that is the square of an integer; in other words, it is the product of some integer with itself. For example, 1, 4, 9, and 16 are perfect squares while 3 and 11 are not.
Example 1:
Input: n = 12
Output: 3
Explanation: 12 = 4 + 4 + 4.
Example 2:
Input: n = 13
Output: 2
Explanation: 13 = 4 + 9.
Constraints:
1 <= n <= 10^4
Solution
Tags: Dynamic Programming
Explanation
We can solve the problem by the sub-problem. Consider the least number of perfect square numbers that sum to n. We can find *the least number of perfect square numbers that sum to n - 1*2, n - 2*2, n - 3*3, ...
\[ \begin{align} A[n] & = 0 & \text{if } n \le 0 \\ A[n] & = 1 + min_{j \in \lbrace 1,2,3,...\rbrace} \lbrace A[n - j^2] \rbrace & \text{otherwise} \end{align} \]
Code
impl Solution {
pub fn num_squares(n: i32) -> i32 {
let n = n as usize;
let mut dp = vec![i32::MAX ; n + 1];
dp[0] = 0;
dp[1] = 1;
for target in 2..=n {
for candidate in 1..{
if target >= candidate * candidate {
dp[target] = dp[target].min(dp[target - candidate * candidate] + 1);
}else {
break;
}
}
}
return dp[n] as i32;
}
}
Complexity
Time Complexity
- \(T(n) = \Theta(n^{3/2}) = \Theta(n^{1.5}) \)
- Iterate over the
dparray - The inner loop runs \(\sqrt{n}\) times.
- Iterate over the
Auxiliary Space
- \(S(n) = O(n)\)
322. Coin Change
Description of the Problem
You are given an integer array coins representing coins of different denominations and an integer amount representing a total amount of money.
Return the fewest number of coins that you need to make up that amount. If that amount of money cannot be made up by any combination of the coins, return -1.
You may assume that you have an infinite number of each kind of coin.
Example 1:
Input: coins = [1,2,5], amount = 11
Output: 3
Explanation: 11 = 5 + 5 + 1
Example 2:
Input: coins = [2], amount = 3
Output: -1
Example 3:
Input: coins = [1], amount = 0
Output: 0
Constraints:
1 <= coins.length <= 121 <= coins[i] <= 2^31 - 10 <= amount <= 10^4.
Solution
Tags: Permutation and Combination Dynamic Programming
Explanation
Intuitively, if the amount of coins is "divisible", the fewest possible number of coins is 1. Thus, if the amount is equals to one of the denominations, then it should return 1.
For any amount of coins, we can try every possible denominator to find the minimum number of coins. See the following equations:
\[ \text{min_coins}(n) = \begin{cases} 0 & \text{if n is 0} \\ 1 & \text{if n is one of the denominators} \\ +\infty & \text{if n is negative} \\ \min_{c \ \in \ Denominators} \{ 1 + \text{min_coins}(n-c) \} & \text{otherwise} \end{cases} \]
However, recursive approach may be very slow. It is more preferable to use Dynamic Programming approach because each solution is depended on smaller sub-solution.
Code
impl Solution {
pub fn coin_change(coins: Vec<i32>, amount: i32) -> i32 {
let amount = amount as usize;
let mut dp = vec![None ; amount + 1];
dp[0] = Some(0);
for i in 1..=amount{
for &chosen_coin in coins.iter() {
if i >= chosen_coin as usize {
let mx = dp[i];
let my = dp[i-chosen_coin as usize];
dp[i] = match (mx,my){
(None,None)=>None,
(Some(x),None)=>Some(x),
(None,Some(y))=>Some(y+1),
(Some(x),Some(y))=>Some(x.min(y+1)),
};
}
}
}
if let Some(sol) = dp[amount] { sol } else { -1 }
}
}
Complexity
Time complexity:
- \(O(n k)\)
- \(n\) is amount of money and \(k\) is number of coins of different denominations
Auxiliary Space:
- \( \Theta(n) \)
328. Odd Even Linked List
Description of Problem
Given the head of a singly linked list, group all the nodes with odd indices together followed by the nodes with even indices, and return the reordered list.
The first node is considered odd, and the second node is even, and so on.
Note that the relative order inside both the even and odd groups should remain as it was in the input.
You must solve the problem in O(1) extra space complexity and O(n) time complexity.
Example 1:
Input: head = [1,2,3,4,5]
Output: [1,3,5,2,4]
Example 2:
Input: head = [2,1,3,5,6,4,7]
Output: [2,3,6,7,1,5,4]
Constraints:
- The number of nodes in the linked list is in the range
[0, 10^4]. -10^6 <= Node.val <= 10^6
Solution
Tags: LinkedList
Explanation
Please look at LeetCoder25's Solution
Code (C++)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* oddEvenList(ListNode* head) {
if (head == nullptr || head->next == nullptr){
return head;
}
ListNode * odd = head;
ListNode * evenHead = head->next;
ListNode * even = evenHead;
while(odd->next != nullptr && even->next != nullptr){
odd->next = even->next;
even->next = odd->next->next;
odd = odd->next;
even = even->next;
}
odd->next = evenHead;
return head;
}
};
Complexity
- n is the length of the linkedlist
Time Complexity
- \( T(n) = O(n) \)
Auxiliary Space
- \( S(n) = O(1) \)
Reference
334. Increasing Triplet Subsequence
Description of Problem
Given an integer array nums, return true if there exists a triple of indices (i, j, k) such that i < j < k and nums[i] < nums[j] < nums[k]. If no such indices exists, return false.
Example 1:
Input: nums = [1,2,3,4,5]
Output: true
Explanation: Any triplet where i < j < k is valid.
Example 2:
Input: nums = [5,4,3,2,1]
Output: false
Explanation: No triplet exists.
Example 3:
Input: nums = [2,1,5,0,4,6]
Output: true
Explanation: The triplet (3, 4, 5) is valid because nums[3] == 0 < nums[4] == 4 < nums[5] == 6.
Constraints:
1 <= nums.length <= 5 * 10^5-2^31 <= nums[i] <= 2^31 - 1
Follow up: Could you implement a solution that runs in O(n) time complexity and O(1) space complexity?
Solution
Code
impl Solution {
pub fn increasing_triplet(nums: Vec<i32>) -> bool {
let (mut smaller, mut bigger) = (i32::MAX, i32::MAX);
for n in nums.into_iter(){
// keep updating the smaller and bigger
if n <= smaller {smaller = n;}
else if n <= bigger {bigger = n;}
// until we find the biggest
else {return true;}
}
return false;
}
}
Complexity
- n is length of
nums
Time Complexity
- \( T(n) = O(n) \)
Auxiliary Space
- \( S(n) = O(1) \)
347. Top K Frequent Elements
Description of the Problem
Given an integer array nums and an integer k, return the k most frequent elements. You may return the answer in any order.
Example 1:
Input: nums = [1,1,1,2,2,3], k = 2
Output: [1,2]
Example 2:
Input: nums = [1], k = 1
Output: [1]
Constraints:
1 <= nums.length <= 10^510^4 <= nums[i] <= 10^4kis in the range[1, the number of unique elements in the array].- It is guaranteed that the answer is unique.
Follow up: Your algorithm's time complexity must be better than O(n log n), where n is the array's size.
Solution
Tags: Heap
Explanation
Count the number of occurrence of each number. Insert them into bounded-size min heap according to their number of occurrence. Since each insertion remove element with the smallest number of occurrence if the min heap is full, the remaining elements in the heap must be the Top K most-frequent elements.
Code
use std::collections::{HashMap, BinaryHeap};
#[derive(Eq,PartialEq)]
struct Counter(i32,i32);
impl Ord for Counter {
fn cmp(&self, other: &Self) -> std::cmp::Ordering{
other.1.cmp(&self.1)
}
}
impl PartialOrd for Counter {
fn partial_cmp(&self, other: &Self) -> Option<std::cmp::Ordering>{
Some(other.1.cmp(&self.1))
}
}
impl Solution {
pub fn top_k_frequent(nums: Vec<i32>, k: i32) -> Vec<i32> {
let k = k as usize;
let mut counterMap = HashMap::new();
nums.into_iter().for_each(
|n| {
let mut count = counterMap.get_mut(&n);
if count.is_none(){
counterMap.insert(n,1);
}else{
*count.unwrap() += 1;
}
}
);
let mut min_heap = BinaryHeap::new();
counterMap.into_iter().for_each(
|(key,val)| {
min_heap.push(Counter(key,val));
if min_heap.len() > k {
min_heap.pop();
}
}
);
return min_heap.into_iter().rev().map(|Counter(v,_)| v ).collect::<Vec<i32>>();
}
}
Complexity (n is the size of array)
Time complexity:
- Worst case: \(O(n + n \log k)\)
- \( n \) for counting
- \(\log k\) for insertion of an element in bounded min heap
Auxiliary Space:
- \( O(n) \)
- The size of counter is bound by the number of elements.
371. Sum of Two Integers
Description of the Problem
Given two integers a and b, return the sum of the two integers without using the operators + and -.
Example 1:
Input: a = 1, b = 2
Output: 3
Example 2:
Input: a = 2, b = 3
Output: 5
Constraints:
-1000 <= a, b <= 1000
Solution
Tags: Bit Manipulation
Explanation
The following code explains itself if you know how to perform addition of binary numbers by yourself.
Code (Rust)
impl Solution {
pub fn get_sum(a: i32, b: i32) -> i32 {
let mut a = a;
let mut b = b;
while(b != 0){
let sum = a ^ b;
let carry = a & b;
a = sum;
b = carry << 1;
}
return a;
}
}
Complexity (m is the length of list1 and n is the length of list2)
Time complexity:
- \(O(1)\)
- In lowest level the time is bound by a constant since the number of bits in an integer is constant
Auxiliary Space:
- \( O(1) \)
375. Guess Number Higher or Lower II
Description of Problem
We are playing the Guessing Game. The game will work as follows:
- I pick a number between
1andn. - You guess a number.
- If you guess the right number, you win the game.
- If you guess the wrong number, then I will tell you whether the number I picked is higher or lower, and you will continue guessing.
- Every time you guess a wrong number
x, you will payxdollars. If you run out of money, you lose the game.
Given a particular n, return the minimum amount of money you need to guarantee a win regardless of what number I pick.
Example 1:
Input: n = 10
Output: 16
Explanation: The winning strategy is as follows:
- The range is [1,10]. Guess 7.
- If this is my number, your total is $0. Otherwise, you pay $7.
- If my number is higher, the range is [8,10]. Guess 9.
- If this is my number, your total is $7. Otherwise, you pay $9.
- If my number is higher, it must be 10. Guess 10. Your total is $7 + $9 = $16.
- If my number is lower, it must be 8. Guess 8. Your total is $7 + $9 = $16.
- If my number is lower, the range is [1,6]. Guess 3.
- If this is my number, your total is $7. Otherwise, you pay $3.
- If my number is higher, the range is [4,6]. Guess 5.
- If this is my number, your total is $7 + $3 = $10. Otherwise, you pay $5.
- If my number is higher, it must be 6. Guess 6. Your total is $7 + $3 + $5 = $15.
- If my number is lower, it must be 4. Guess 4. Your total is $7 + $3 + $5 = $15.
- If my number is lower, the range is [1,2]. Guess 1.
- If this is my number, your total is $7 + $3 = $10. Otherwise, you pay $1.
- If my number is higher, it must be 2. Guess 2. Your total is $7 + $3 + $1 = $11.
The worst case in all these scenarios is that you pay $16. Hence, you only need $16 to guarantee a win.
Example 2:
Input: n = 1
Output: 0
Explanation: There is only one possible number, so you can guess 1 and not have to pay anything.
Example 3:
Input: n = 2
Output: 1
Explanation: There are two possible numbers, 1 and 2.
- Guess 1.
- If this is my number, your total is $0. Otherwise, you pay $1.
- If my number is higher, it must be 2. Guess 2. Your total is $1.
The worst case is that you pay $1.
Constraints:
1 <= n <= 200
Solution
Tags: Dynamic Programming,Game Theory
Explanation
Denote \( S_{i,j} \) as a solution of a sub-problem which is the minimum of amount of money to guarentee the successful guess while the range is i to j (inclusively). Suppose we pick k, the amount to guarentee the successful guess is \( k+ \max(S_{i,k-1}, S_{k+1,j}) \). Hence, we get the recursive formula.
\[
S_{i,j} =
\begin{cases}
0 & \text{if } i \ge j \\
\min_{k \in \lbrace i,i+1,...,j \rbrace} \lbrace k + \max(S_{i,k-1}, S_{k+1,j}) \rbrace & \text{if } i \lt j
\end{cases}
\]
We observe that the Solution of \(S_{i,j}\) depends on either the solutions on the left or the bottom in the dp table. Thus, the algorithm loops over the dp table diagonally (It makes the below code hard to read.).
Exmaple of diagonal loop
Suppose it is 5x5 dp table:
1 2 3 4 5
1 2 3 4
1 2 3
1 2
1
Number i represents the i-th inner loop
Code (Rust)
impl Solution {
pub fn get_money_amount(n: i32) -> i32 {
let n = n as usize;
let mut dp = vec![ vec![0 ; n + 1] ; n + 1];
for i in 1..n {
for j in 0..(n-i){
let mut min = i32::MAX;
let row = 1 + j;
let col = 1 + j + i;
for k in row..=col {
let a = if row >= 0 && row <= n && k >= 1 && k <= n + 1 { dp[row][k - 1] } else { 0 };
let b = if col >= 0 && col <= n && k + 1 >= 0 && k + 1 <= n {dp[k+1][col] } else { 0 };
min = min.min( k as i32 + a.max(b) );
}
dp[row][col] = min;
}
}
return dp[1][n];
}
}
Complexity
Time Complexity
- \(T(n) = Theta(n^2)\)
Auxiliary Space
- \(S(n) = Theta(n^2)\)
435. Non-overlapping Intervals
Description of the Problem
Given an array of intervals intervals where intervals[i] = [starti, endi], return the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping.
Example 1:
Input: intervals = [[1,2],[2,3],[3,4],[1,3]]
Output: 1
Explanation: [1,3] can be removed and the rest of the intervals are non-overlapping.
Example 2:
Input: intervals = [[1,2],[1,2],[1,2]]
Output: 2
Explanation: You need to remove two [1,2] to make the rest of the intervals non-overlapping.
Example 3:
Input: intervals = [[1,2],[2,3]]
Output: 0
Explanation: You don't need to remove any of the intervals since they're already non-overlapping.
Constraints:
1 <= intervals.length <= 105intervals[i].length == 2-5 * 10^4 <= starti < endi <= 5 * 10^4
Solution
Tags: Greedy,Stack
Explanation
The problem is equivalent to classical Activity Selection Problem which is to maximise the number of compatiable activities. Thus, in the following explanation, we assume that our goal is to maximise the number of activities in our schdule.
To solve the above problem, we choose activities one-by-one with earliest finish time (Greedy Algorithm).
Optimal Substructure Property
Suppose an activity \(a_k\) with interval \((s_k, f_k)\) is in optimal schedule from \(f_i\) to \(s_j\). The optimal solution can be divided into 3 parts: \( A_{ik} \cup a_k \cup A_{kj} \) where \( A_{ik} \) is optimal schedule start after \(f_i\) and finsih before \(s_k\) and \( A_{kj} \) is optimal schedule start after \(f_k\) and finsih before \(s_j\).
In other word, we can use Divide-and-Conquer to find optimal solution. i.e. choose an activity \(a_k\) such that the combined solution is maximum.
\[ \arg\max_{k} | A_{0k} \cup a_k \cup A_{kn} | \]
Greedy-choice Property
Suppose we have an optimal schedule \(A^*\) contains \(a_k\) which has earliest finish time in \( A^* \).
Suppose \( a_j \) has earliest finish time in the set of activities.
Replace \( a_k \) by \( a_j \) still yield the optimal schedule.
Code (Java)
class Solution {
public int eraseOverlapIntervals(int[][] intervals) {
Arrays.sort(intervals, (ai, aj) -> ai[1] - aj[1]);
int count = 0;
final int [] prev = intervals[0];
int prev_start = prev[0];
int prev_end = prev[1];
for(int i = 1; i < intervals.length; i++){
int[] curr = intervals[i];
int curr_start = curr[0];
int curr_end = curr[1];
if(curr_start < prev_end ){
count ++;
}
else{
prev_start = curr_start;
prev_end = curr_end;
}
}
return count;
}
}
Complexity
Time complexity:
- \(O(n\lg n + n)\)
- Sorting + Selection
Auxiliary Space:
- \( O(1) \)
Further Discussion
It is absolutely a bad way to implement a tuple (a, b) by Array. Especially since Rust support tuples, storing two number (start time and finish time) in Vector is not the good practice. The following code is alternative implementation and solution.
type Interval = (i32, i32);
struct Solution{}
impl Solution {
pub fn erase_overlap_intervals(intervals: Vec<Interval>) -> i32 {
let mut intervals = intervals;
intervals.sort_by( |(_,f1), (_,f2)| f1.cmp(&f2) );
let mut count = 0;
let (mut prev_start, mut prev_end) = intervals[0];
for (curr_start, curr_end) in intervals.into_iter().skip(1) {
if curr_start < prev_end {
count += 1;
}
else{
prev_start = curr_start;
prev_end = curr_end;
}
}
return count;
}
}
fn main(){
println!("{}", Solution::erase_overlap_intervals( vec![(1,2),(2,3),(3,4),(1,3)] ) );
println!("{}", Solution::erase_overlap_intervals( vec![(1,2),(1,2),(1,2)] ) );
println!("{}", Solution::erase_overlap_intervals( vec![(1,2),(2,3)] ) );
}
443. String Compression
Given an array of characters chars, compress it using the following algorithm:
Begin with an empty string s. For each group of consecutive repeating characters in chars:
- If the group's length is
1, append the character tos. - Otherwise, append the character followed by the group's length.
The compressed string s should not be returned separately, but instead, be stored in the input character array chars. Note that group lengths that are 10 or longer will be split into multiple characters in chars.
After you are done modifying the input array, return the new length of the array.
You must write an algorithm that uses only constant extra space.
Example 1:
Input: chars = ["a","a","b","b","c","c","c"]
Output: Return 6, and the first 6 characters of the input array should be: ["a","2","b","2","c","3"]
Explanation: The groups are "aa", "bb", and "ccc". This compresses to "a2b2c3".
Example 2:
Input: chars = ["a"]
Output: Return 1, and the first character of the input array should be: ["a"]
Explanation: The only group is "a", which remains uncompressed since it's a single character.
Example 3:
Input: chars = ["a","b","b","b","b","b","b","b","b","b","b","b","b"]
Output: Return 4, and the first 4 characters of the input array should be: ["a","b","1","2"].
Explanation: The groups are "a" and "bbbbbbbbbbbb". This compresses to "ab12".
Constraints:
1 <= chars.length <= 2000chars[i]is a lowercase English letter, uppercase English letter, digit, or symbol.
Solution
Tags: Turing Machines String Two Pointers
Explanation
The solution uses "Two Pointers" method. Imagine that there is a Turing Machine with read_head and write_head to process string chars; the machine is defined as following:
- The machine has two states: the character count
countand previous character read by the machineprev - The machine has two heads:
read_headandwrite_head - The procedure continues as the following until the
read_headreaches the null character of the string:- If the machine read the same characters as
prev,read_headmove right and increment the count; - otherwise (either read different character or
read_headreaches the end), keep movingwrite_headwhen writing 1prevand the "count" on the tape. After all, reset the machine state by settingcount = 0andprev = chars[read_head]; movingread_headto right.
- If the machine read the same characters as
Code (Rust)
impl Solution {
pub fn compress(chars: &mut Vec<char>) -> i32 {
let mut count = 1;
let mut prev = chars[0];
let (mut read_head, mut write_head) = (1,0);
while read_head <= chars.len() {
if read_head < chars.len() && prev == chars[read_head] {
count+=1;
}else {
// Writing prev character
chars[write_head] = prev;
write_head+=1;
// Writing the "count"
if count > 1{
for c in count.to_string().chars(){
chars[write_head] = c;
write_head +=1;
}
}
// Reset the machine state
if read_head < chars.len() { prev = chars[read_head] };
count = 1;
}
read_head+=1; // read_head move to right
}
return write_head as i32;
}
}
Complexity
- \(n\) is length of
chars
Time Complexity
- \(T(n) = \Theta(n)\)
read_headandwrite_headmoves at most \(n\) steps.
Auxiliary Space
- \(S(n) = O(1)\)
452. Minimum Number of Arrows to Burst Balloons
Description of Problem
There are some spherical balloons taped onto a flat wall that represents the XY-plane. The balloons are represented as a 2D integer array points where points[i] = [xstart, xend] denotes a balloon whose horizontal diameter stretches between xstart and xend. You do not know the exact y-coordinates of the balloons.
Arrows can be shot up directly vertically (in the positive y-direction) from different points along the x-axis. A balloon with xstart and xend is burst by an arrow shot at x if xstart <= x <= xend. There is no limit to the number of arrows that can be shot. A shot arrow keeps traveling up infinitely, bursting any balloons in its path.
Given the array points, return the minimum number of arrows that must be shot to burst all balloons.
Example 1:
Input: points = [[10,16],[2,8],[1,6],[7,12]]
Output: 2
Explanation: The balloons can be burst by 2 arrows:
- Shoot an arrow at x = 6, bursting the balloons [2,8] and [1,6].
- Shoot an arrow at x = 11, bursting the balloons [10,16] and [7,12].
Example 2:
Input: points = [[1,2],[3,4],[5,6],[7,8]]
Output: 4
Explanation: One arrow needs to be shot for each balloon for a total of 4 arrows.
Example 3:
Input: points = [[1,2],[2,3],[3,4],[4,5]]
Output: 2
Explanation: The balloons can be burst by 2 arrows:
- Shoot an arrow at x = 2, bursting the balloons [1,2] and [2,3].
- Shoot an arrow at x = 4, bursting the balloons [3,4] and [4,5].
Constraints:
1 <= points.length <= 10^5points[i].length == 2-2^31 <= xstart < xend <= 2^31 - 1
Solution
Tags: Stack
Explanation
Consider intervals \(I_{i,j} = \lbrace x | i \le x \le j \rbrace\), \(I_{u,w} = \lbrace x | u \le x \le w \rbrace\). If they have no intersection (i.e. overlapping), nothing to do.
Otherwise, without loss of generality, let's say \( i \le u \), their intersection \( I_{i,j} \cap I_{u,w} \) becomes \(\lbrace x | \max(i,u) \le x \le \min(j,w) \rbrace\).
If \(I_1, I_2, I_3\) have an intersection (i.e. they can be burst by one arrow shot), we can get the intersection by \( (I_1 \cap I_2) \cap I_3 \).
Hence, first sort the intervals by x_start. Then keep doing intersection with last interval in the stack or push a non-overlapping interval to the stack. After that, we get the set of disjoint intervals where the number of elements equals to the minimum number of arrows that must be shot to burst all balloons.
Code (Rust)
impl Solution {
pub fn find_min_arrow_shots(points: Vec<Vec<i32>>) -> i32 {
let mut points = points;
points.sort_by( |v1, v2| v1[0].cmp(&v2[0]));
let mut stack : Vec<(i32,i32)> = vec![];
for p in points.into_iter() {
let (c, d) = (p[0], p[1]);
if let Some(t) = stack.last() {
let (a,b) = (t.0, t.1);
if b >= c {
stack.pop();
stack.push( ( a.max(c),b.min(d) ) );
}else{
stack.push( (c,d) );
}
}else {
stack.push( (c,d) );
}
}
return stack.len() as i32;
}
}
Complexity
- n is length of
points
Time Complexity
- \( T(n) = \Theta(n) \)
Auxiliary Space
- \( S(n) = O(n) \)
518. Coin Change II
Description of Problem
You are given an integer array coins representing coins of different denominations and an integer amount representing a total amount of money.
Return the number of combinations that make up that amount. If that amount of money cannot be made up by any combination of the coins, return 0.
You may assume that you have an infinite number of each kind of coin.
The answer is guaranteed to fit into a signed 32-bit integer.
Example 1:
Input: amount = 5, coins = [1,2,5]
Output: 4
Explanation: there are four ways to make up the amount:
5=5
5=2+2+1
5=2+1+1+1
5=1+1+1+1+1
Example 2:
Input: amount = 3, coins = [2]
Output: 0
Explanation: the amount of 3 cannot be made up just with coins of 2.
Example 3:
Input: amount = 10, coins = [10]
Output: 1
Constraints:
1 <= coins.length <= 3001 <= coins[i] <= 5000- All the values of
coinsare unique. 0 <= amount <= 5000
Solution
Tags: Dynamic Programming
Explanation
Binary Selection Method
If the amount is a positive number and the number of coins available is not zero, then there are two disjoint cases: to use the current coin and not to use it. (see the following equations)
\[ w(coins, sum) = \begin{cases} 0 & \text{if } sum \lt 0 \\ 1 & \text{if } sum = 0 \\ 0 & \text{if } sum \gt 0 \land coins = \varnothing \\ w(coins, sum - c) + w(coins \setminus \{ c \} , sum) & \text{otherwise; for some c in coins} \end{cases} \]
Dynamic Programming using less space
We can also use less space. If we rewrite the recursive equation, you will get the update equation of 1-D DP table.
(coin_idx indicates that coins[0] to coins[coin_indx] are avaiable coins and coins[coin_indx] is the current selection.)
\[ w(coin\_idx, sum) = w(coins, sum - coins[ coin\_idx ]) + w(coin\_idx - 1 , sum) \] \[ \Longleftrightarrow w(sum)^{(t)} = w(sum - coins[ t ])^{(t)} + w(sum)^{(t - 1)} \]
Code (Rust)
impl Solution {
pub fn change(amount: i32, coins: Vec<i32>) -> i32 {
let m = amount as usize;
let n = coins.len();
let mut dp = vec![ vec![0; m+1]; n ];
// If it is divisible by the smallest coin
for (j,x) in (0..=amount).enumerate() {
dp[0][j] = if x % coins[0] == 0 {1} else {0};
}
// Use the equations
for i in 1..n {
for j in 0..=m {
let c = coins[i] as usize;
dp[i][j] =
if j >= c { dp[i][j-c] } else {0}
+ if i > 0 { dp[i-1][j] } else {0}
}
}
dp[n-1][m]
}
}
Code (Rust) - With less Space
impl Solution {
pub fn change(amount: i32, coins: Vec<i32>) -> i32 {
let m = amount as usize;
let n = coins.len();
let mut dp = vec![ 0; m+1 ];
dp[0] = 1;
for i in 0..n {
for j in 1..=m {
let c = coins[i] as usize;
dp[j] += if j >= c { dp[j-c] } else {0}
}
}
dp[m]
}
}
Complexity (m is the amount and n is number of coins)
Time complexity:
- \(O(mn)\)
Auxiliary Space:
- \( O(m) \)
Further Discussion
- For more optimised solution see vanAmsen's solution
547. Number of Provinces
Description of Problem
There are n cities. Some of them are connected, while some are not. If city a is connected directly with city b, and city b is connected directly with city c, then city a is connected indirectly with city c.
A province is a group of directly or indirectly connected cities and no other cities outside of the group.
You are given an n x n matrix isConnected where isConnected[i][j] = 1 if the ith city and the jth city are directly connected, and isConnected[i][j] = 0 otherwise.
Return the total number of provinces.
Example 1:
Input: isConnected = [[1,1,0],[1,1,0],[0,0,1]]
Output: 2
Example 2:
Input: isConnected = [[1,0,0],[0,1,0],[0,0,1]]
Output: 3
Constraints:
1 <= n <= 200n == isConnected.lengthn == isConnected[i].lengthisConnected[i][j]is1or0.isConnected[i][i] == 1isConnected[i][j] == isConnected[j][i]
Solution
Tags: Depth First Search,Graph Theory
Explanation
Perform depth-first-search on each node until all nodes are explored:
- Mark the current as gray node (exploring node).
- Perform depth-first-search in adjancent white nodes (unexplored nodes).
- When complete exploration of each adjancent white nodes, mark the current node as black node (explored node).
Since a depth-first-search from node i traverses all nodes that reachable from node i. Hence, the count of depth-first-search performed is the number of provinces.
Code (Rust)
#[derive(Clone, Copy, Debug, PartialEq)]
enum Colour{
White,
Gray,
Black,
}
use Colour::{White, Gray, Black};
impl Solution {
pub fn find_circle_num(is_connected: Vec<Vec<i32>>) -> i32 {
let n = is_connected.len();
let mut count = 0;
let mut colour = vec![White ; n];
for node in 0..n {
if colour[node] == White{
Self::dfs(node, &is_connected, &mut colour);
count+=1;
}
}
return count;
}
fn dfs(node : usize, is_connected : &Vec<Vec<i32>>, colour : &mut Vec<Colour>) {
colour[node] = Gray;
for (i, &b) in is_connected[node].iter().enumerate() {
if b == 1 && colour[i] == White {
Self::dfs(i, is_connected, colour);
}
}
colour[node] = Black;
}
}
Complexity
- \(|V|\) is the number of nodes
- \(|E|\) is the number of edges
Time Complexity
- \( T(|V|,|E|) = \Theta(|V|) \)
Auxiliary Space
- \(S(|V|,|E|) = \Theta(|V|)\)
- Keep track of node colours
550. Game Play Analysis IV
Description of Problem
Table: Activity
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| player_id | int |
| device_id | int |
| event_date | date |
| games_played | int |
+--------------+---------+
(player_id, event_date) is the primary key (combination of columns with unique values) of this table.
This table shows the activity of players of some games.
Each row is a record of a player who logged in and played a number of games (possibly 0) before logging out on someday using some device.
Write a solution to report the fraction of players that logged in again on the day after the day they first logged in, rounded to 2 decimal places. In other words, you need to count the number of players that logged in for at least two consecutive days starting from their first login date, then divide that number by the total number of players.
The result format is in the following example.
Example 1:
Input:
Activity table:
+-----------+-----------+------------+--------------+
| player_id | device_id | event_date | games_played |
+-----------+-----------+------------+--------------+
| 1 | 2 | 2016-03-01 | 5 |
| 1 | 2 | 2016-03-02 | 6 |
| 2 | 3 | 2017-06-25 | 1 |
| 3 | 1 | 2016-03-02 | 0 |
| 3 | 4 | 2018-07-03 | 5 |
+-----------+-----------+------------+--------------+
Output:
+-----------+
| fraction |
+-----------+
| 0.33 |
+-----------+
Explanation:
Only the player with id 1 logged back in after the first day he had logged in so the answer is 1/3 = 0.33
Solution
Tags: SQL Advanced Select Joins
Code (MySQL)
-- Write your MySQL query statement below
WITH p AS (
SELECT player_id, MIN(event_date) as event_date
FROM Activity
GROUP BY player_id
)
SELECT ROUND(AVG(IF(a.player_id IS NULL, 0, 1)),2) AS fraction
FROM p
LEFT JOIN Activity AS a
ON p.player_id = a.player_id
AND DATEDIFF(p.event_date, a.event_date) = -1;
570. Managers with at Least 5 Direct Reports
Description of the Problem
Table: Employee
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| name | varchar |
| department | varchar |
| managerId | int |
+-------------+---------+
id is the primary key (column with unique values) for this table.
Each row of this table indicates the name of an employee, their department, and the id of their manager.
If managerId is null, then the employee does not have a manager.
No employee will be the manager of themself.
Write a solution to find managers with at least five direct reports.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Employee table:
+-----+-------+------------+-----------+
| id | name | department | managerId |
+-----+-------+------------+-----------+
| 101 | John | A | null |
| 102 | Dan | A | 101 |
| 103 | James | A | 101 |
| 104 | Amy | A | 101 |
| 105 | Anne | A | 101 |
| 106 | Ron | B | 101 |
+-----+-------+------------+-----------+
Output:
+------+
| name |
+------+
| John |
+------+
Solution
Tags: SQL Grouping
Code (MySQL)
SELECT e2.name
FROM Employee e1
INNER JOIN Employee e2
ON e1.managerId = e2.id
GROUP BY e1.managerId
HAVING COUNT(1) >= 5;
585. Investments in 2016
Description of Problem
Table: Insurance
+-------------+-------+
| Column Name | Type |
+-------------+-------+
| pid | int |
| tiv_2015 | float |
| tiv_2016 | float |
| lat | float |
| lon | float |
+-------------+-------+
pid is the primary key (column with unique values) for this table.
Each row of this table contains information about one policy where:
pid is the policyholder's policy ID.
tiv_2015 is the total investment value in 2015 and tiv_2016 is the total investment value in 2016.
lat is the latitude of the policy holder's city. It's guaranteed that lat is not NULL.
lon is the longitude of the policy holder's city. It's guaranteed that lon is not NULL.
Write a solution to report the sum of all total investment values in 2016 tiv_2016, for all policyholders who:
- have the same
tiv_2015value as one or more other policyholders, and are not located in the same city as any - other policyholder (i.e., the (lat, lon) attribute pairs must be unique).
Round tiv_2016 to two decimal places.
The result format is in the following example.
Example 1:
Input:
Insurance table:
+-----+----------+----------+-----+-----+
| pid | tiv_2015 | tiv_2016 | lat | lon |
+-----+----------+----------+-----+-----+
| 1 | 10 | 5 | 10 | 10 |
| 2 | 20 | 20 | 20 | 20 |
| 3 | 10 | 30 | 20 | 20 |
| 4 | 10 | 40 | 40 | 40 |
+-----+----------+----------+-----+-----+
Output:
+----------+
| tiv_2016 |
+----------+
| 45.00 |
+----------+
Explanation:
The first record in the table, like the last record, meets both of the two criteria.
The tiv_2015 value 10 is the same as the third and fourth records, and its location is unique.
The second record does not meet any of the two criteria. Its tiv_2015 is not like any other policyholders and its location is the same as the third record, which makes the third record fail, too.
So, the result is the sum of tiv_2016 of the first and last record, which is 45.
Solution
Tags: SQL Subquery
The Solution shows the use of EXISTS and NOT EXISTS.
Code (MySQL)
-- Write your MySQL query statement below
SELECT ROUND(SUM(i.tiv_2016),2) as tiv_2016
FROM Insurance i
WHERE EXISTS (
SELECT 1
FROM Insurance i2
WHERE i2.tiv_2015 = i.tiv_2015
AND i2.pid != i.pid
)
AND NOT EXISTS (
SELECT 1
FROM Insurance i2
WHERE i2.lat = i.lat
AND i2.lon = i.lon
AND i2.pid != i.pid
);
602. Friend Requests II: Who Has the Most Friends
Description of Problem
Table: RequestAccepted
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| requester_id | int |
| accepter_id | int |
| accept_date | date |
+----------------+---------+
(requester_id, accepter_id) is the primary key (combination of columns with unique values) for this table.
This table contains the ID of the user who sent the request, the ID of the user who received the request, and the date when the request was accepted.
Write a solution to find the people who have the most friends and the most friends number.
The test cases are generated so that only one person has the most friends.
The result format is in the following example.
Example 1:
Input:
RequestAccepted table:
+--------------+-------------+-------------+
| requester_id | accepter_id | accept_date |
+--------------+-------------+-------------+
| 1 | 2 | 2016/06/03 |
| 1 | 3 | 2016/06/08 |
| 2 | 3 | 2016/06/08 |
| 3 | 4 | 2016/06/09 |
+--------------+-------------+-------------+
Output:
+----+-----+
| id | num |
+----+-----+
| 3 | 3 |
+----+-----+
Explanation:
The person with id 3 is a friend of people 1, 2, and 4, so he has three friends in total, which is the most number than any others.
Follow up: In the real world, multiple people could have the same most number of friends. Could you find all these people in this case?
Solution
Tags: SQL Advanced Select
Answer to follow-up question
ORDER BY num and set LIMIT
Code (MySQL)
-- Write your MySQL query statement below
WITH p AS (
SELECT requester_id as id
FROM RequestAccepted
UNION ALL
SELECT accepter_id as id
FROM RequestAccepted
)
SELECT id, COUNT(1) as num
FROM p
GROUP BY p.id
ORDER BY num DESC
LIMIT 1;
608. Tree Node
Description of Problem
Table: Tree
+-------------+------+
| Column Name | Type |
+-------------+------+
| id | int |
| p_id | int |
+-------------+------+
id is the column with unique values for this table.
Each row of this table contains information about the id of a node and the id of its parent node in a tree.
The given structure is always a valid tree.
Each node in the tree can be one of three types:
- "Leaf": if the node is a leaf node.
- "Root": if the node is the root of the tree.
- "Inner": If the node is neither a leaf node nor a root node.
Write a solution to report the type of each node in the tree.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Tree table:
+----+------+
| id | p_id |
+----+------+
| 1 | null |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 2 |
+----+------+
Output:
+----+-------+
| id | type |
+----+-------+
| 1 | Root |
| 2 | Inner |
| 3 | Leaf |
| 4 | Leaf |
| 5 | Leaf |
+----+-------+
Explanation:
Node 1 is the root node because its parent node is null and it has child nodes 2 and 3.
Node 2 is an inner node because it has parent node 1 and child node 4 and 5.
Nodes 3, 4, and 5 are leaf nodes because they have parent nodes and they do not have child nodes.
Example 2:
Input:
Tree table:
+----+------+
| id | p_id |
+----+------+
| 1 | null |
+----+------+
Output:
+----+-------+
| id | type |
+----+-------+
| 1 | Root |
+----+-------+
Explanation: If there is only one node on the tree, you only need to output its root attributes.
Note: This question is the same as 3054: Binary Tree Nodes.
Solution
Tags: SQL
Code (MySQL)
SELECT
id,
CASE
WHEN p_id IS NULL THEN 'Root'
WHEN id IN (SELECT p_id FROM Tree) THEN 'Inner'
ELSE 'Leaf'
END AS 'type'
FROM Tree self
GROUP BY self.id
;
626. Exchange Seats
Description of Problem
Table: Seat
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| student | varchar |
+-------------+---------+
id is the primary key (unique value) column for this table.
Each row of this table indicates the name and the ID of a student.
id is a continuous increment.
Write a solution to swap the seat id of every two consecutive students. If the number of students is odd, the id of the last student is not swapped.
Return the result table ordered by id in ascending order.
The result format is in the following example.
Example 1:
Input:
Seat table:
+----+---------+
| id | student |
+----+---------+
| 1 | Abbot |
| 2 | Doris |
| 3 | Emerson |
| 4 | Green |
| 5 | Jeames |
+----+---------+
Output:
+----+---------+
| id | student |
+----+---------+
| 1 | Doris |
| 2 | Abbot |
| 3 | Green |
| 4 | Emerson |
| 5 | Jeames |
+----+---------+
Explanation:
Note that if the number of students is odd, there is no need to change the last one's seat.
Solution
Tags: SQL Advanced Select
Code (MySQL)
-- Write your MySQL query statement below
WITH p AS (
SELECT MAX(id) as max_id FROM Seat
)
SELECT
IF(
MOD(s.id, 2) = 0 ,
s.id - 1,
IF(s.id = p.max_id, s.id, s.id + 1)
) AS id,
s.student
FROM Seat s
INNER JOIN p
ORDER BY id
;
735. Asteroid Collision
Description of Problem
We are given an array asteroids of integers representing asteroids in a row.
For each asteroid, the absolute value represents its size, and the sign represents its direction (positive meaning right, negative meaning left). Each asteroid moves at the same speed.
Find out the state of the asteroids after all collisions. If two asteroids meet, the smaller one will explode. If both are the same size, both will explode. Two asteroids moving in the same direction will never meet.
Example 1:
Input: asteroids = [5,10,-5]
Output: [5,10]
Explanation: The 10 and -5 collide resulting in 10. The 5 and 10 never collide.
Example 2:
Input: asteroids = [8,-8]
Output: []
Explanation: The 8 and -8 collide exploding each other.
Example 3:
Input: asteroids = [10,2,-5]
Output: [10]
Explanation: The 2 and -5 collide resulting in -5. The 10 and -5 collide resulting in 10.
Constraints:
2 <= asteroids.length <= 10^4-1000 <= asteroids[i] <= 1000asteroids[i] != 0
Solution
Tags: Stack
Explanation
Construct a stack that store only stable asteroids (which means no collision i.e. no pair of (-->,<--) in the stack).
If there is collision when appending new asteroid, keep colliding until the stack is stable.
Code (Rust)
impl Solution {
pub fn asteroid_collision(asteroids: Vec<i32>) -> Vec<i32> {
let mut stack : Vec<i32> = vec![];
for incoming in asteroids.into_iter(){
let mut incoming = incoming;
// Keep collide when (rightmost)--> <--(incoming)
while let Some(&rightmost) = stack.last() {
if rightmost > 0 && incoming < 0 && rightmost.abs() < incoming.abs() {
// `rightmost` is destroyed, remain `incoming`
stack.pop();
}else if rightmost > 0 && incoming < 0 && rightmost.abs() > incoming.abs(){
// `incoming` is destroyed, remain `rightmost`
stack.pop();
incoming = rightmost
}else if rightmost > 0 && incoming < 0 && rightmost.abs() == incoming.abs(){
// Both are destroyed
stack.pop();
incoming = 0;
break;
}else{
// Collision does not happen
break;
}
}
// The incoming asteroid still exist, append into the stack
if incoming != 0 {
stack.push(incoming);
}
}
return stack;
}
}
Complexity
- n is length of
asteroids
Time Complexity
\( T(n) = \Theta(n) \)
Auxiliary Space
\( S(n) = O(n) \)
739. Daily Temperatures
Description of Problem
Given an array of integers temperatures represents the daily temperatures, return an array answer such that answer[i] is the number of days you have to wait after the ith day to get a warmer temperature. If there is no future day for which this is possible, keep answer[i] == 0 instead.
Example 1:
Input: temperatures = [73,74,75,71,69,72,76,73]
Output: [1,1,4,2,1,1,0,0]
Example 2:
Input: temperatures = [30,40,50,60]
Output: [1,1,1,0]
Example 3:
Input: temperatures = [30,60,90]
Output: [1,1,0]
Constraints:
1 <= temperatures.length <= 10^530 <= temperatures[i] <= 100
Solution
Tags: Monotonic Stack
The best problem about Monotonic Stack for beginners.
Explanation
Solve the problem by monotonic stack where the top of the stack is the smallest element in the stack: Loop over the array reversely; before insertion of the current element, remove all elements that less than or equal to the current elements from the top.
Since we need to calculate the distance of current element and next greater element (NGE), the stack stores index instead of value of an element.
For convinence of proof, assume our monotonic stack stores (index, value) tuples.
Loop invariant: The value of the top of the stack is the smallest value in the stack AND it is greater than the current element
- Initialisation: Stack is empty, thus it is vacuously true.
- Maintenance: Suppose the invariant is true before an iteration. Now consider the current element before insertion:
- The algorithm removes all elements where their value are less than or equal to the value of current element.
- After all, the stack contains only elements where their value greater than the value of the current element. The value of the top of the stack is still the smallest value among the values in the stack.
- Thus, the loop invariant preserves. The algorithm insert the current element.
- Termination: The loop invariant is true at the termination.
Example
- If we want to insert
75, we have to remove69and72. - If we want ot insert
71, we have to remove69. - If we want ot insert
50, we don't need to remove any element.
Code (Rust)
impl Solution {
pub fn daily_temperatures(temperatures: Vec<i32>) -> Vec<i32> {
let mut mono_stack = Vec::new();
let n = temperatures.len();
let mut ans = vec![0; n];
for i in (0..n).rev() {
while let Some(&j) = mono_stack.last() {
if temperatures[i] >= temperatures[j] {
mono_stack.pop();
}else{
break;
}
}
if let Some(&j) = mono_stack.last() {
ans[i] = (j - i) as i32;
}else {
ans[i] = 0;
}
mono_stack.push(i);
}
return ans;
}
}
Complexity
- \(n\) is length of
temperatures
Time Complexity
- \(S(n) = \Theta(2n) = \Theta(n)\)
- Iterate
temperatures - Pop at most \(n\) elements
- Iterate
Auxiliary Space
- \(S(n) = O(n)\)
- Store at most \(n\) elements
790. Domino and Tromino Tiling
Description of Problem
You have two types of tiles: a 2 x 1 domino shape and a tromino shape. You may rotate these shapes.
Given an integer n, return the number of ways to tile an 2 x n board. Since the answer may be very large, return it modulo 10^9 + 7.
In a tiling, every square must be covered by a tile. Two tilings are different if and only if there are two 4-directionally adjacent cells on the board such that exactly one of the tilings has both squares occupied by a tile.
Example 1:
Input: n = 3
Output: 5
Explanation: The five different ways are show above.
Example 2:
Input: n = 1
Output: 1
Constraints:
1 <= n <= 1000
Solution
Tags: Dynamic Programming
Explanation
Code (Rust)
impl Solution {
pub fn num_tilings(n: i32) -> i32 {
const MOD : u64 = 1_000_000_007;
let n = n as usize;
let mut lambda = vec![0 ; 3];
let mut mu = vec![0 ; 3];
for i in 1..=2 {
if n >= i{
lambda[i % 3] = i as u64;
mu[i % 3] = i as u64;
}
}
for i in 3..=n{
lambda[i % 3] =
(lambda[(i - 1) % 3] ) % MOD
+ (lambda[(i - 2) % 3] ) % MOD
+ (2 * mu[(i - 2) % 3] ) % MOD;
lambda[i % 3] = lambda[i % 3] % MOD;
mu[i % 3] =
(mu[(i - 1) % 3]) % MOD
+ (lambda[(i - 1) % 3]) % MOD;
mu[i % 3] = mu[i % 3] % MOD;
}
return lambda[n % 3] as i32;
}
}
Complexity
Time Complexity
- \( T(n) = \Theta(n) \)
Auxiliary Space
- \( S(n) = \Theta(n) \)
- \( S(n) = O(1) \) (With Space Optimisation)
Reference
841. Keys and Rooms
Description of Problem
There are n rooms labeled from 0 to n - 1 and all the rooms are locked except for room 0. Your goal is to visit all the rooms. However, you cannot enter a locked room without having its key.
When you visit a room, you may find a set of distinct keys in it. Each key has a number on it, denoting which room it unlocks, and you can take all of them with you to unlock the other rooms.
Given an array rooms where rooms[i] is the set of keys that you can obtain if you visited room i, return true if you can visit all the rooms, or false otherwise.
Example 1:
Input: rooms = [[1],[2],[3],[]]
Output: true
Explanation:
We visit room 0 and pick up key 1.
We then visit room 1 and pick up key 2.
We then visit room 2 and pick up key 3.
We then visit room 3.
Since we were able to visit every room, we return true.
Example 2:
Input: rooms = [[1,3],[3,0,1],[2],[0]]
Output: false
Explanation: We can not enter room number 2 since the only key that unlocks it is in that room.
Constraints:
n == rooms.length2 <= n <= 10000 <= rooms[i].length <= 10001 <= sum(rooms[i].length) <= 30000 <= rooms[i][j] < n- All the values of
rooms[i]are unique.
Solution
Tags: Depth First Search Graph Theory
Explanation
We use the same manner in 547. Number of Provinces. Perform depth-first-serach on node 0 and see whether all nodes are black.
Code (Rust)
#[derive(Clone, Copy, Debug, PartialEq)]
enum Colour{
White,
Gray,
Black,
}
use Colour::{White, Gray, Black};
impl Solution {
pub fn can_visit_all_rooms(rooms: Vec<Vec<i32>>) -> bool {
let n = rooms.len();
let mut colour = vec![White ; n];
Self::dfs(0, &rooms, &mut colour);
return colour.into_iter().all(|c| c == Black);
}
fn dfs(n : usize, rooms : &Vec<Vec<i32>>, colour : &mut Vec<Colour>) {
colour[n] = Gray;
for &i in rooms[n].iter() {
let i = i as usize;
if colour[i] == White {
Self::dfs(i, rooms, colour);
}
}
colour[n] = Black;
}
}
Complexity
- \(|V|\) is the number of nodes
- \(|E|\) is the number of edges
Time Complexity
- \( T(|V|,|E|) = \Theta(|V|) \)
Auxiliary Space
- \(S(|V|,|E|) = \Theta(|V|)\)
- Keep track of node colours
901. Online Stock Span
Description of Problem
Design an algorithm that collects daily price quotes for some stock and returns the span of that stock's price for the current day.
The span of the stock's price in one day is the maximum number of consecutive days (starting from that day and going backward) for which the stock price was less than or equal to the price of that day.
- For example, if the prices of the stock in the last four days is
[7,2,1,2]and the price of the stock today is2, then the span of today is4because starting from today, the price of the stock was less than or equal2for4consecutive days. - Also, if the prices of the stock in the last four days is
[7,34,1,2]and the price of the stock today is8, then the span of today is3because starting from today, the price of the stock was less than or equal8for3consecutive days.
Implement the StockSpanner class:
StockSpanner()Initializes the object of the class.int next(int price)Returns the span of the stock's price given that today's price isprice.
Example 1:
Input
["StockSpanner", "next", "next", "next", "next", "next", "next", "next"]
[[], [100], [80], [60], [70], [60], [75], [85]]
Output
[null, 1, 1, 1, 2, 1, 4, 6]
Explanation
StockSpanner stockSpanner = new StockSpanner();
stockSpanner.next(100); // return 1
stockSpanner.next(80); // return 1
stockSpanner.next(60); // return 1
stockSpanner.next(70); // return 2
stockSpanner.next(60); // return 1
stockSpanner.next(75); // return 4, because the last 4 prices (including today's price of 75) were less than or equal to today's price.
stockSpanner.next(85); // return 6
Constraints:
1 <= price <= 10^5- At most
10^4calls will be made tonext.
Solution
Tags: Monotonic Stack
Explanation
Create a monotonic stack that stores tuples (price, days) (days means the number of consecutive days that price of stock is smaller than or equal to price) in decreasing order in terms of price along stack grwoing direction. That means the top of the stack is always the smallest element.
When a new element price comes, there are two possible cases:
- If the top element of the stack is greater, that means there is no consecutive preivous days where stock price is smaller than or equal to the new price. Hence, insert
(price, 1)into the stack. - Otherwise, keep remove the top element and increment
countbydays. After all, insert(price, count+1).
For example:
1. [(100,1)] // Just insert 100
2. [(100,1), (80,1)] // Just insert 80
3. [(100,1), (80,1), (60,1)] // Just insert 60
4. [(100,1), (80,1), (70,2)] // In order to insert 70, pop 60
5. [(100,1), (80,1), (70,2), (60, 1)] // Just insert 60
6. [(100,1), (80,1), (75, 4)] // In order to insert 70, pop 60 and 70
7. [(100,1), (85, 6)] // In order to insert 70, pop 65 and 80
Code
struct StockSpanner {
monotonic_stack : Vec<(i32,i32)>
}
/**
* `&self` means the method takes an immutable reference.
* If you need a mutable reference, change it to `&mut self` instead.
*/
impl StockSpanner {
fn new() -> Self {
StockSpanner {
monotonic_stack : Vec::new()
}
}
fn next(&mut self, price: i32) -> i32 {
if let Some(&(top, _)) = self.monotonic_stack.last(){
if top > price {
self.monotonic_stack.push((price, 1));
return 1;
}else {
let mut pop_count = 0;
// keep popping smaller elements
while let Some(&(top, days)) = self.monotonic_stack.last(){
if top <= price {
self.monotonic_stack.pop();
pop_count+=days;
}else{
break;
}
}
self.monotonic_stack.push((price, pop_count+1));
return pop_count+1;
}
}else{
self.monotonic_stack.push((price, 1));
return 1;
}
}
}
/**
* Your StockSpanner object will be instantiated and called as such:
* let obj = StockSpanner::new();
* let ret_1: i32 = obj.next(price);
*/
Complexity
- n is the number of
int next(int price)requests
Time Complexity
- \(T(n) = O(n) \)
Auxiliary Space
- \(S(n) = O(n) \)
994. Rotting Oranges
Description of Problem
You are given an m x n grid where each cell can have one of three values:
0representing an empty cell,1representing a fresh orange, or2representing a rotten orange.
Every minute, any fresh orange that is 4-directionally adjacent to a rotten orange becomes rotten.
Return the minimum number of minutes that must elapse until no cell has a fresh orange. If this is impossible, return -1.
Example 1:
Input: grid = [[2,1,1],[1,1,0],[0,1,1]]
Output: 4
Example 2:
Input: grid = [[2,1,1],[0,1,1],[1,0,1]]
Output: -1
Explanation: The orange in the bottom left corner (row 2, column 0) is never rotten, because rotting only happens 4-directionally.
Example 3:
Input: grid = [[0,2]]
Output: 0
Explanation: Since there are already no fresh oranges at minute 0, the answer is just 0.
Constraints:
m == grid.lengthn == grid[i].length1 <= m, n <= 10grid[i][j]is0,1, or2.
Solution
Tags: Breadth First Search
Explanation
Very simple, just use BFS to simulate the process of rotting oranges.
Code (Rust)
#[derive(Clone, Copy, Debug, PartialEq)]
enum Colour{
White,
Gray,
Black,
}
use Colour::{White, Gray, Black};
impl Solution {
pub fn oranges_rotting(grid: Vec<Vec<i32>>) -> i32 {
use std::collections::VecDeque;
let m = grid.len();
let n = grid[0].len();
let mut colours = vec![ vec![White ;n];m ];
let mut depth = 0;
let mut queue1 = VecDeque::new();
let mut queue2 = VecDeque::new();
let mut count_rotten = 0;
let mut count_fresh = 0;
// Put all rotten organges into queue1
for i in 0..m{
for j in 0..n{
if grid[i][j] == 2 {
queue1.push_back((i,j));
colours[i][j] = Black;
count_rotten+=1;
}else if grid[i][j] == 1 {
count_fresh+=1;
}
}
}
// Deal with special cases
// Case 1: The grid has no fresh oranges
if count_fresh == 0 {
return 0;
}
// Case 2: The grid has only fresh oranges
else if count_rotten == 0{
return -1;
}
// Case 3: The grid has fresh oranges and rotton oranges
while !queue1.is_empty(){
while let Some((i,j)) = queue1.pop_front(){
// UP
if Self::is_available(&grid, &colours, i-1, j, m, n) {
colours[i-1][j] = Gray;
queue2.push_back((i-1, j));
}
// LEFT
if Self::is_available(&grid, &colours, i, j-1, m, n) {
colours[i][j-1] = Gray;
queue2.push_back((i,j-1));
}
// RIGHT
if Self::is_available(&grid, &colours, i, j+1, m, n) {
colours[i][j+1] = Gray;
queue2.push_back((i,j+1));
}
// BOTTOM
if Self::is_available(&grid, &colours, i+1, j, m, n) {
colours[i+1][j] = Gray;
queue2.push_back((i+1,j));
}
// Finish the exploration of the node
colours[i][j] = Black;
}
depth+=1;
let temp = queue1;
queue1 = queue2;
queue2 = temp;
}
// Check whether all oranges are rotten?
for i in 0..m{
for j in 0..n{
if colours[i][j] != Black && (grid[i][j] == 2 || grid[i][j] == 1) {
return - 1;
}
}
}
return depth - 1;
}
#[inline(always)]
fn is_available(
grid: &Vec<Vec<i32>>,
colours : &Vec<Vec<Colour>>,
i : usize,
j : usize,
m : usize,
n : usize
) -> bool {
return
0 <= i && i < m
&& 0 <= j && j < n
&& grid[i][j] == 1
&& colours[i][j] == White
;
}
}
Complexity
Time Complexity
- \( T(m,n) = O(m \cdot n) \)
1004. Max Consecutive Ones III
Description of Problem
Given a binary array nums and an integer k, return the maximum number of consecutive 1's in the array if you can flip at most k 0's.
Example 1:
Input: nums = [1,1,1,0,0,0,1,1,1,1,0], k = 2
Output: 6
Explanation: [1,1,1,0,0,1,1,1,1,1,1]
Bolded numbers were flipped from 0 to 1. The longest subarray is underlined.
Example 2:
Input: nums = [0,0,1,1,0,0,1,1,1,0,1,1,0,0,0,1,1,1,1], k = 3
Output: 10
Explanation: [0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,1,1,1,1]
Bolded numbers were flipped from 0 to 1. The longest subarray is underlined.
Constraints:
1 <= nums.length <= 10^5nums[i]is either0or1.0 <= k <= nums.length
Solution
Tags: Sliding Window Two Pointers
Explanation
Imagine that there is a double-linked list (deque) that stores 1s and at most k 0s. Loop over the array and do the following:
- When
1comes, put it into the back of deque - When
0comes, there are two possible case:- The deque stores less than
k0s (i.e. the new0is available in the deque). In this case, put0into the the back of deque - The deque already stores
k0s. In this case, remove elements from the front of the deque until new0is available.
- The deque stores less than
Code
impl Solution {
pub fn longest_ones(nums: Vec<i32>, k: i32) -> i32 {
let (n, k) = (nums.len(), k as usize);
let (mut i, mut j) = (0, 0);
let mut count_zeros = 0;
let mut max = 0;
while j < n {
if nums[j] == 0 {
count_zeros+=1;
}
while count_zeros > k {
if nums[i] == 0 { count_zeros-=1; }
i+=1;
}
max = max.max(j - i + 1);
j+=1;
}
return max as i32;
}
}
Complexity
- n is length of
nums - X is the total number of elements pop from the deque
Time Complexity
- \( T(n) = O(n) \)
- The time complexity is O(n+X) since the deque push
nelements and popXelements. Xis less than or equal ton- \(O(n+X) = O(2n) = O(n) \)
- The time complexity is O(n+X) since the deque push
Auxiliary Space
- \( S(n) = O(1) \)
1045. Customers Who Bought All Products
Description
Table: Customer
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| customer_id | int |
| product_key | int |
+-------------+---------+
This table may contain duplicates rows.
customer_id is not NULL.
product_key is a foreign key (reference column) to Product table.
Table: Product
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| product_key | int |
+-------------+---------+
product_key is the primary key (column with unique values) for this table.
Write a solution to report the customer ids from the Customer table that bought all the products in the Product table.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Customer table:
+-------------+-------------+
| customer_id | product_key |
+-------------+-------------+
| 1 | 5 |
| 2 | 6 |
| 3 | 5 |
| 3 | 6 |
| 1 | 6 |
+-------------+-------------+
Product table:
+-------------+
| product_key |
+-------------+
| 5 |
| 6 |
+-------------+
Output:
+-------------+
| customer_id |
+-------------+
| 1 |
| 3 |
+-------------+
Explanation:
The customers who bought all the products (5 and 6) are customers with IDs 1 and 3.
Solution
Tags: SQL Grouping
Code (MySQL)
-- Write your MySQL query statement below
SELECT c.customer_id
FROM Customer c
GROUP BY c.customer_id
HAVING COUNT(DISTINCT c.product_key) = (SELECT COUNT(1) FROM Product);
1070. Product Sales Analysis III
Description of Problem
Table: Sales
+-------------+-------+
| Column Name | Type |
+-------------+-------+
| sale_id | int |
| product_id | int |
| year | int |
| quantity | int |
| price | int |
+-------------+-------+
(sale_id, year) is the primary key (combination of columns with unique values) of this table.
product_id is a foreign key (reference column) to Product table.
Each row of this table shows a sale on the product product_id in a certain year.
Note that the price is per unit.
Table: Product
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| product_id | int |
| product_name | varchar |
+--------------+---------+
product_id is the primary key (column with unique values) of this table.
Each row of this table indicates the product name of each product.
Write a solution to select the product id, year, quantity, and price for the first year of every product sold.
Return the resulting table in any order.
The result format is in the following example.
Example 1:
Input:
Sales table:
+---------+------------+------+----------+-------+
| sale_id | product_id | year | quantity | price |
+---------+------------+------+----------+-------+
| 1 | 100 | 2008 | 10 | 5000 |
| 2 | 100 | 2009 | 12 | 5000 |
| 7 | 200 | 2011 | 15 | 9000 |
+---------+------------+------+----------+-------+
Product table:
+------------+--------------+
| product_id | product_name |
+------------+--------------+
| 100 | Nokia |
| 200 | Apple |
| 300 | Samsung |
+------------+--------------+
Output:
+------------+------------+----------+-------+
| product_id | first_year | quantity | price |
+------------+------------+----------+-------+
| 100 | 2008 | 10 | 5000 |
| 200 | 2011 | 15 | 9000 |
+------------+------------+----------+-------+
Solution
Tags: SQL Joins
Explanation
Rows GROUP BY product_id and first_year is are unique. Thus, ROW_NUMBER with PARTITION does not work.
Code (MySQL)
-- Write your MySQL query statement below
WITH p AS (
SELECT MIN(year) first_year, product_id, year
FROM Sales
GROUP BY product_id
)
SELECT s.product_id, p.first_year, s.quantity, s.price
FROM Sales s
INNER JOIN p
ON s.product_id = p.product_id
AND s.year = p.first_year;
1143. Longest Common Subsequence
Description of Problem
Given two strings text1 and text2, return the length of their longest common subsequence. If there is no common subsequence, return 0.
A subsequence of a string is a new string generated from the original string with some characters (can be none) deleted without changing the relative order of the remaining characters.
- For example,
"ace"is a subsequence of"abcde".
A common subsequence of two strings is a subsequence that is common to both strings.
Example 1:
Input: text1 = "abcde", text2 = "ace"
Output: 3
Explanation: The longest common subsequence is "ace" and its length is 3.
Example 2:
Input: text1 = "abc", text2 = "abc"
Output: 3
Explanation: The longest common subsequence is "abc" and its length is 3.
Example 3:
Input: text1 = "abc", text2 = "def"
Output: 0
Explanation: There is no such common subsequence, so the result is 0.
Constraints:
1 <= text1.length, text2.length <= 1000text1andtext2consist of only lowercase English characters.
Solution
Tags: Dynamic Programming
Explanation
Look at explanation of LCS from Wikipedia.
Let \(X_i\) and \(Y_i\) are substring of s1 and s2 from index 0 to i (exclusively) (i.e. \(X_i = (x_0,x_1,...x_{i-1})\)) and \(||\) be concatenation opertor.
\[
LCS(X_i, Y_i) =
\begin{cases}
\epsilon & \text{if i = 0 or j = 0} \\
LCS(X_{i-1}, Y_{i-1}) || x_{i-1} & \text{if i > 0 and j > 0 and } x_{i-1} = y_{i-1} \\
\max(LCS(X_{i}, Y_{i-1}), LCS(X_{i-1},Y_{i})) & \text{if i > 0 and j > 0 and }x_{i-1} \ne y_{i-1}
\end{cases}
\]
Since the problem requires us return the length, it requires no back-tracking. We can reduce the space used into 2 rows.
Code (Rust)
impl Solution {
pub fn longest_common_subsequence(text1: String, text2: String) -> i32 {
let (s1, s2) = (text1.as_bytes(), text2.as_bytes());
let (m, n) = (s1.len(), s2.len());
let mut dp = vec![ vec![ 0 ; n ] ; 2];
let mut k = 0;
for i in 0..m{
for j in 0..n{
let n_len = if i >= 1 && j >= 0 {
dp[k^1][j]
} else {
0
};
let w_len = if i >= 0 && j >= 1 {
dp[k][j-1]
} else {
0
};
let nw_len = if i >= 1 && j >= 1 {
dp[k^1][j-1]
} else {
0
};
dp[k][j] = if s1[i] == s2[j] {
1+nw_len
} else if n_len > w_len {
n_len
}else {
w_len
};
}
k^=1;
}
return dp[(m-1) % 2][n-1];
}
}
Complexity
- m is length of
s1 - n is length of
s2
Time Complexity
- \( T(m,n) = \Theta(m \cdot n) \)
Auxiliary Space
- \( S(m,n) = \Theta(m \cdot n) \)
- \( S(m,n) = \Theta(n) \) with space optimisation
1158. Market Analysis I
Description of Problem
Table: Users
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| user_id | int |
| join_date | date |
| favorite_brand | varchar |
+----------------+---------+
user_id is the primary key (column with unique values) of this table.
This table has the info of the users of an online shopping website where users can sell and buy items.
Table: Orders
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| order_id | int |
| order_date | date |
| item_id | int |
| buyer_id | int |
| seller_id | int |
+---------------+---------+
order_id is the primary key (column with unique values) of this table.
item_id is a foreign key (reference column) to the Items table.
buyer_id and seller_id are foreign keys to the Users table.
Table: Items
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| item_id | int |
| item_brand | varchar |
+---------------+---------+
item_id is the primary key (column with unique values) of this table.
Write a solution to find for each user, the join date and the number of orders they made as a buyer in 2019.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Users table:
+---------+------------+----------------+
| user_id | join_date | favorite_brand |
+---------+------------+----------------+
| 1 | 2018-01-01 | Lenovo |
| 2 | 2018-02-09 | Samsung |
| 3 | 2018-01-19 | LG |
| 4 | 2018-05-21 | HP |
+---------+------------+----------------+
Orders table:
+----------+------------+---------+----------+-----------+
| order_id | order_date | item_id | buyer_id | seller_id |
+----------+------------+---------+----------+-----------+
| 1 | 2019-08-01 | 4 | 1 | 2 |
| 2 | 2018-08-02 | 2 | 1 | 3 |
| 3 | 2019-08-03 | 3 | 2 | 3 |
| 4 | 2018-08-04 | 1 | 4 | 2 |
| 5 | 2018-08-04 | 1 | 3 | 4 |
| 6 | 2019-08-05 | 2 | 2 | 4 |
+----------+------------+---------+----------+-----------+
Items table:
+---------+------------+
| item_id | item_brand |
+---------+------------+
| 1 | Samsung |
| 2 | Lenovo |
| 3 | LG |
| 4 | HP |
+---------+------------+
Output:
+-----------+------------+----------------+
| buyer_id | join_date | orders_in_2019 |
+-----------+------------+----------------+
| 1 | 2018-01-01 | 1 |
| 2 | 2018-02-09 | 2 |
| 3 | 2018-01-19 | 0 |
| 4 | 2018-05-21 | 0 |
+-----------+------------+----------------+
Solution
Tags: SQL
Code
# Write your MySQL query statement below
SELECT
u.user_id AS buyer_id,
u.join_date,
IF(o.buyer_id IS NOT NULL, COUNT('X') , 0) AS orders_in_2019
FROM Users u
LEFT JOIN Orders o
ON u.user_id = o.buyer_id
AND YEAR(o.order_date) = 2019
GROUP BY u.user_id, u.join_date
1161. Maximum Level Sum of a Binary Tree
Description of Problem
Given the root of a binary tree, the level of its root is 1, the level of its children is 2, and so on.
Return the smallest level x such that the sum of all the values of nodes at level x is maximal.
Example 1:
Input: root = [1,7,0,7,-8,null,null]
Output: 2
Explanation:
Level 1 sum = 1.
Level 2 sum = 7 + 0 = 7.
Level 3 sum = 7 + -8 = -1.
So we return the level with the maximum sum which is level 2.
Example 2:
Input: root = [989,null,10250,98693,-89388,null,null,null,-32127]
Output: 2
Constraints:
- The number of nodes in the tree is in the range
[1, 104]. -10^5 <= Node.val <= 10^5
Solution
Tags: Breadth First Search
Explanation
Use the same manner in 199. Binary Tree Right Side View.
Code
// Definition for a binary tree node.
// #[derive(Debug, PartialEq, Eq)]
// pub struct TreeNode {
// pub val: i32,
// pub left: Option<Rc<RefCell<TreeNode>>>,
// pub right: Option<Rc<RefCell<TreeNode>>>,
// }
//
// impl TreeNode {
// #[inline]
// pub fn new(val: i32) -> Self {
// TreeNode {
// val,
// left: None,
// right: None
// }
// }
// }
use std::rc::Rc;
use std::cell::RefCell;
use std::collections::VecDeque;
impl Solution {
pub fn level_with_max_sum_sum(root: Option<Rc<RefCell<TreeNode>>>) -> i32 {
let mut queue1 = VecDeque::new();
let mut queue2 = VecDeque::new();
let mut max_sum = i32::MIN;
let (mut level, mut level_with_max_sum) = (0,0);
if let Some(node) = root{
queue1.push_back(Some(node));
}
while !queue1.is_empty(){
level+=1;
let mut sum = 0;
while let Some(Some(node)) = queue1.pop_front(){
let node = node.borrow();
sum += node.val;
let left = node.left.clone();
let right = node.right.clone();
if left.is_some(){
queue2.push_back(left);
}
if right.is_some(){
queue2.push_back(right);
}
}
if sum > max_sum {
max_sum = sum;
level_with_max_sum = level
}
let temp = queue1;
queue1 = queue2;
queue2 = temp;
}
return level_with_max_sum;
}
}
Complexity
- n is the number of nodes in tree
- h is the height of tree
Time Complexity
- \( T(n) = \Theta(n) \)
Auxiliary Space
- \( S(h) = O(2^h) \)
1164. Product Price at a Given Date
Description of Problem
Table: Products
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| product_id | int |
| new_price | int |
| change_date | date |
+---------------+---------+
(product_id, change_date) is the primary key (combination of columns with unique values) of this table.
Each row of this table indicates that the price of some product was changed to a new price at some date.
Write a solution to find the prices of all products on 2019-08-16. Assume the price of all products before any change is 10.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Products table:
+------------+-----------+-------------+
| product_id | new_price | change_date |
+------------+-----------+-------------+
| 1 | 20 | 2019-08-14 |
| 2 | 50 | 2019-08-14 |
| 1 | 30 | 2019-08-15 |
| 1 | 35 | 2019-08-16 |
| 2 | 65 | 2019-08-17 |
| 3 | 20 | 2019-08-18 |
+------------+-----------+-------------+
Output:
+------------+-------+
| product_id | price |
+------------+-------+
| 2 | 50 |
| 1 | 35 |
| 3 | 10 |
+------------+-------+
Solution
Tags: SQL Grouping Divide and Conquer
Code (MySQL)
-- Find all prices where change_date is before '2019-08-16'.
-- GROUP BY product_id and ORDER BY change_date
WITH p AS (
SELECT
ROW_NUMBER() OVER (
PARTITION BY p2.product_id
ORDER BY p2.change_date DESC
) row_num,
p2.product_id,
p2.new_price,
p2.change_date
FROM Products p2
WHERE p2.change_date <= '2019-08-16'
)
-- Find the latest record
SELECT p.product_id, p.new_price AS price
FROM p
WHERE row_num = 1
UNION
-- Find products where change_date is after '2019-08-16'
SELECT p1.product_id, 10 AS price
FROM Products AS p1
WHERE NOT EXISTS (
SELECT 1
FROM p AS p2
WHERE p2.product_id = p1.product_id
);
1174. Immediate Food Delivery II
Desciption of Problem
Table: Delivery
+-----------------------------+---------+
| Column Name | Type |
+-----------------------------+---------+
| delivery_id | int |
| customer_id | int |
| order_date | date |
| customer_pref_delivery_date | date |
+-----------------------------+---------+
delivery_id is the column of unique values of this table.
The table holds information about food delivery to customers that make orders at some date and specify a preferred delivery date (on the same order date or after it).
If the customer's preferred delivery date is the same as the order date, then the order is called immediate; otherwise, it is called scheduled.
The first order of a customer is the order with the earliest order date that the customer made. It is guaranteed that a customer has precisely one first order.
Write a solution to find the percentage of immediate orders in the first orders of all customers, rounded to 2 decimal places.
The result format is in the following example.
Example 1:
Input:
Delivery table:
+-------------+-------------+------------+-----------------------------+
| delivery_id | customer_id | order_date | customer_pref_delivery_date |
+-------------+-------------+------------+-----------------------------+
| 1 | 1 | 2019-08-01 | 2019-08-02 |
| 2 | 2 | 2019-08-02 | 2019-08-02 |
| 3 | 1 | 2019-08-11 | 2019-08-12 |
| 4 | 3 | 2019-08-24 | 2019-08-24 |
| 5 | 3 | 2019-08-21 | 2019-08-22 |
| 6 | 2 | 2019-08-11 | 2019-08-13 |
| 7 | 4 | 2019-08-09 | 2019-08-09 |
+-------------+-------------+------------+-----------------------------+
Output:
+----------------------+
| immediate_percentage |
+----------------------+
| 50.00 |
+----------------------+
Explanation:
The customer id 1 has a first order with delivery id 1 and it is scheduled.
The customer id 2 has a first order with delivery id 2 and it is immediate.
The customer id 3 has a first order with delivery id 5 and it is scheduled.
The customer id 4 has a first order with delivery id 7 and it is immediate.
Hence, half the customers have immediate first orders.
Solution
Tags: SQL Grouping Advanced Select
Code (MySQL) - Using ROW_NUMBER() and PARTITION BY
-- Write your MySQL query statement below
WITH t AS (
SELECT
ROW_NUMBER() OVER (
PARTITION BY customer_id
ORDER BY order_date ASC
) AS row_num, d.*
FROM Delivery d
)
SELECT
ROUND(
AVG(order_date = customer_pref_delivery_date) * 100,
2
) AS immediate_percentage
FROM t
WHERE row_num = 1;
1193. Monthly Transactions I
Description of Problem
Table: Transactions
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| country | varchar |
| state | enum |
| amount | int |
| trans_date | date |
+---------------+---------+
id is the primary key of this table.
The table has information about incoming transactions.
The state column is an enum of type ["approved", "declined"].
Write an SQL query to find for each month and country, the number of transactions and their total amount, the number of approved transactions and their total amount.
Return the result table in any order.
The query result format is in the following example.
Example 1:
Input:
Transactions table:
+------+---------+----------+--------+------------+
| id | country | state | amount | trans_date |
+------+---------+----------+--------+------------+
| 121 | US | approved | 1000 | 2018-12-18 |
| 122 | US | declined | 2000 | 2018-12-19 |
| 123 | US | approved | 2000 | 2019-01-01 |
| 124 | DE | approved | 2000 | 2019-01-07 |
+------+---------+----------+--------+------------+
Output:
+----------+---------+-------------+----------------+--------------------+-----------------------+
| month | country | trans_count | approved_count | trans_total_amount | approved_total_amount |
+----------+---------+-------------+----------------+--------------------+-----------------------+
| 2018-12 | US | 2 | 1 | 3000 | 1000 |
| 2019-01 | US | 1 | 1 | 2000 | 2000 |
| 2019-01 | DE | 1 | 1 | 2000 | 2000 |
+----------+---------+-------------+----------------+--------------------+-----------------------+
Solution
Tags: SQL Aggregate Functions Grouping
Explanation
Hints: Make month a new column and use GROUP BY.
Code (MySQL)
SELECT
CONCAT(YEAR(trans_date),'-',LPAD(MONTH(trans_date),2,'0')) AS month,
country,
COUNT(1) AS trans_count,
SUM(state = 'approved') AS approved_count,
SUM(amount) AS trans_total_amount,
SUM(IF(state = 'approved', amount,0)) AS approved_total_amount
FROM Transactions
GROUP BY month, country;
1204. Last Person to Fit in the Bus
Description of Problem
Table: Queue
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| person_id | int |
| person_name | varchar |
| weight | int |
| turn | int |
+-------------+---------+
person_id column contains unique values.
This table has the information about all people waiting for a bus.
The person_id and turn columns will contain all numbers from 1 to n, where n is the number of rows in the table.
turn determines the order of which the people will board the bus, where turn=1 denotes the first person to board and turn=n denotes the last person to board.
weight is the weight of the person in kilograms.
There is a queue of people waiting to board a bus. However, the bus has a weight limit of 1000 kilograms, so there may be some people who cannot board.
Write a solution to find the person_name of the last person that can fit on the bus without exceeding the weight limit. The test cases are generated such that the first person does not exceed the weight limit.
The result format is in the following example.
Example 1:
Input:
Queue table:
+-----------+-------------+--------+------+
| person_id | person_name | weight | turn |
+-----------+-------------+--------+------+
| 5 | Alice | 250 | 1 |
| 4 | Bob | 175 | 5 |
| 3 | Alex | 350 | 2 |
| 6 | John Cena | 400 | 3 |
| 1 | Winston | 500 | 6 |
| 2 | Marie | 200 | 4 |
+-----------+-------------+--------+------+
Output:
+-------------+
| person_name |
+-------------+
| John Cena |
+-------------+
Explanation: The folowing table is ordered by the turn for simplicity.
+------+----+-----------+--------+--------------+
| Turn | ID | Name | Weight | Total Weight |
+------+----+-----------+--------+--------------+
| 1 | 5 | Alice | 250 | 250 |
| 2 | 3 | Alex | 350 | 600 |
| 3 | 6 | John Cena | 400 | 1000 | (last person to board)
| 4 | 2 | Marie | 200 | 1200 | (cannot board)
| 5 | 4 | Bob | 175 | ___ |
| 6 | 1 | Winston | 500 | ___ |
+------+----+-----------+--------+--------------+
Solution
Tags: SQL Advanced Select Grouping Aggregate Functions
Code (MySQL)
-- Write your MySQL query statement below
WITH p AS (
SELECT
q.turn,
q.person_name,
SUM(q.weight) OVER (ORDER BY q.turn) AS total_weight
FROM Queue q
)
SELECT p.person_name
FROM p
WHERE p.total_weight <= 1000
ORDER BY p.total_weight DESC
LIMIT 1;
1268. Search Suggestions System
Description of Problem
You are given an array of strings products and a string searchWord.
Design a system that suggests at most three product names from products after each character of searchWord is typed. Suggested products should have common prefix with searchWord. If there are more than three products with a common prefix return the three lexicographically minimums products.
Return a list of lists of the suggested products after each character of searchWord is typed.
Example 1:
Input: products = ["mobile","mouse","moneypot","monitor","mousepad"], searchWord = "mouse"
Output: [["mobile","moneypot","monitor"],["mobile","moneypot","monitor"],["mouse","mousepad"],["mouse","mousepad"],["mouse","mousepad"]]
Explanation: products sorted lexicographically = ["mobile","moneypot","monitor","mouse","mousepad"].
After typing m and mo all products match and we show user ["mobile","moneypot","monitor"].
After typing mou, mous and mouse the system suggests ["mouse","mousepad"].
Example 2:
Input: products = ["havana"], searchWord = "havana"
Output: [["havana"],["havana"],["havana"],["havana"],["havana"],["havana"]]
Explanation: The only word "havana" will be always suggested while typing the search word.
Constraints:
1 <= products.length <= 10001 <= products[i].length <= 30001 <= sum(products[i].length) <= 2 * 10^4- All the strings of
productsare unique. products[i]consists of lowercase English letters.1 <= searchWord.length <= 1000searchWordconsists of lowercase English letters.
Solution
Tags: Functional Programming
Code
impl Solution {
pub fn suggested_products(products: Vec<String>, search_word: String) -> Vec<Vec<String>> {
let mut products = products;
products.sort();
let mut v = vec![];
let n = search_word.len();
for j in 1..=n{
let mut product : Vec<_> = products
.iter()
.filter(|&s| s.starts_with(&search_word[..j]))
.take(3)
.cloned()
.collect();
v.push(product);
}
return v;
}
}
1286. Iterator for Combination
Description of Problem
Design the CombinationIterator class:
CombinationIterator(string characters, int combinationLength)Initializes the object with a stringcharactersof sorted distinct lowercase English letters and a numbercombinationLengthas arguments.next()Returns the next combination of lengthcombinationLengthin lexicographical order.hasNext()Returnstrueif and only if there exists a next combination.
Example 1:
Input
["CombinationIterator", "next", "hasNext", "next", "hasNext", "next", "hasNext"]
[["abc", 2], [], [], [], [], [], []]
Output
[null, "ab", true, "ac", true, "bc", false]
Explanation
CombinationIterator itr = new CombinationIterator("abc", 2);
itr.next(); // return "ab"
itr.hasNext(); // return True
itr.next(); // return "ac"
itr.hasNext(); // return True
itr.next(); // return "bc"
itr.hasNext(); // return False
Constraints:
1 <= combinationLength <= characters.length <= 15- All the characters of
charactersare unique. - At most
10^4calls will be made tonextandhasNext. - It is guaranteed that all calls of the function
nextare valid.
Solution
Tags: Permutation and Combination
Explanation
We can reduce combination problems to permutation problems since choosing k elements from n elements can be treated as permutating list of 0 and 1 where the number of 1 equals to k and of 0 equals to n-k.
For example, choosing 3 elements from [1,2,3,4,5], we have [1,2,3] ([1,1,1,0,0]), [1,2,4] ([1,1,0,1,0]) and so on.
Therefore, we can reuse the solution from [46. Permutations]
Code (Rust)
struct CombinationIterator {
characters : Vec<char>,
perm_iter : PermutationIteratorReverse<bool>,
}
impl CombinationIterator {
fn new(characters: String, length: i32) -> Self {
let mut state = vec![false ; characters.len()];
for i in 0..length as usize {
state[i] = true;
}
CombinationIterator {
characters : characters.chars().collect(),
perm_iter : PermutationIteratorReverse::new(state),
}
}
fn next(&mut self) -> String {
use std::iter::zip;
zip(
&self.characters,
&self.perm_iter.next().unwrap()
).into_iter()
.filter(|(_,b)| {
**b
})
.map(|(c,_)| *c)
.collect()
}
fn has_next(&self) -> bool {
self.perm_iter.has_next()
}
}
Appendix A1 - PermutationIteratorReverse
pub struct PermutationIteratorReverse<T : Ord + Clone>(Option<Vec<T>>);
impl<T : Ord + Clone> PermutationIteratorReverse<T> {
pub fn new(mut elements : Vec<T>) -> Self {
elements.sort();
elements.reverse();
PermutationIteratorReverse(Some(elements))
}
pub fn has_next(&self) -> bool {
self.0.is_some()
}
fn next_permutation(&mut self) -> Option<Vec<T>> {
let res = self.0.clone();
self.0 = self.0.take().and_then(|mut v|{
let i = Self::find_pivot(&v)?;
let j = Self::find_target(&mut v, i);
v.swap(i,j);
let _ = &mut v[i+1..].reverse();
Some(v)
});
return res;
}
fn find_pivot(elements : &[T]) -> Option<usize> {
if elements.len() < 2 {
return None;
}
let (mut i, mut j) = (elements.len() - 2, elements.len() - 1);
while /* i >= 0 && */ j >= 1 {
if elements[i] > elements[j] {
return Some(i);
}
i = i.checked_sub(1).unwrap_or(0);
j = j.checked_sub(1).unwrap_or(0);
}
return None;
}
fn find_target(elements : &mut [T], pivot : usize) -> usize {
let pivot_value = &elements[pivot];
let mut target_index = pivot+1;
let mut target_value = &elements[target_index];
for j in pivot+2..elements.len() {
let v = &elements[j];
if v < pivot_value && v >= target_value {
target_value = v;
target_index = j;
}
}
return target_index;
}
}
impl<T : Ord + Clone> Iterator for PermutationIteratorReverse<T> {
type Item = Vec<T>;
fn next(&mut self) -> Option<Self::Item> {
self.next_permutation()
}
}
1318. Minimum Flips to Make a OR b Equal to c
Description of Problem
Given 3 positives numbers a, b and c. Return the minimum flips required in some bits of a and b to make ( a OR b == c ). (bitwise OR operation).
Flip operation consists of change any single bit 1 to 0 or change the bit 0 to 1 in their binary representation.
Example 1:
Input: a = 2, b = 6, c = 5
Output: 3
Explanation: After flips a = 1 , b = 4 , c = 5 such that (a OR b == c)
Example 2:
Input: a = 4, b = 2, c = 7
Output: 1
Example 3:
Input: a = 1, b = 2, c = 3
Output: 0
Constraints:
1 <= a <= 10^91 <= b <= 10^91 <= c <= 10^9
Solution
Tags: Bit Manipulation
Explanation - "Truth Table"
We can consider all combinations of each 3-bit by "truth table". Error occur if and only if (a|b) != c. Find those rows in truth table and calculate the number of bits need to be flipped.
"Truth table":
a b c #flips needs
----------------------
0 0 0 0
0 0 1 1
0 1 0 1
0 1 1 0
1 0 0 1
1 0 1 0
1 1 0 2
1 1 1 0
Code (Rust)
impl Solution {
pub fn min_flips(a: i32, b: i32, c: i32) -> i32 {
let (mut a, mut b, mut c) = (a,b,c);
let mut count = 0;
while a > 0 || b > 0 || c > 0 {
match (a%2, b%2, c%2) {
(0,0,1) | (0,1,0) | (1,0,0) => {count+=1;},
(1,1,0) => {count+=2;},
_ => {},
}
a = a >> 1;
b = b >> 1;
c = c >> 1;
}
return count;
}
}
Complexity
- let x, y and z be length of
a's,b's andc's binary representation
Time Complexity
- \(T(n) = O(\max(x,y,z))\)
Auxiliary Space
- \(S(n) = O(1)\)
1321. Restaurant Growth
Description of Problem
Table: Customer
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| customer_id | int |
| name | varchar |
| visited_on | date |
| amount | int |
+---------------+---------+
In SQL,(customer_id, visited_on) is the primary key for this table.
This table contains data about customer transactions in a restaurant.
visited_on is the date on which the customer with ID (customer_id) has visited the restaurant.
amount is the total paid by a customer.
You are the restaurant owner and you want to analyze a possible expansion (there will be at least one customer every day).
Compute the moving average of how much the customer paid in a seven days window (i.e., current day + 6 days before). average_amount should be rounded to two decimal places.
Return the result table ordered by visited_on in ascending order.
The result format is in the following example.
Example 1:
Input:
Customer table:
+-------------+--------------+--------------+-------------+
| customer_id | name | visited_on | amount |
+-------------+--------------+--------------+-------------+
| 1 | Jhon | 2019-01-01 | 100 |
| 2 | Daniel | 2019-01-02 | 110 |
| 3 | Jade | 2019-01-03 | 120 |
| 4 | Khaled | 2019-01-04 | 130 |
| 5 | Winston | 2019-01-05 | 110 |
| 6 | Elvis | 2019-01-06 | 140 |
| 7 | Anna | 2019-01-07 | 150 |
| 8 | Maria | 2019-01-08 | 80 |
| 9 | Jaze | 2019-01-09 | 110 |
| 1 | Jhon | 2019-01-10 | 130 |
| 3 | Jade | 2019-01-10 | 150 |
+-------------+--------------+--------------+-------------+
Output:
+--------------+--------------+----------------+
| visited_on | amount | average_amount |
+--------------+--------------+----------------+
| 2019-01-07 | 860 | 122.86 |
| 2019-01-08 | 840 | 120 |
| 2019-01-09 | 840 | 120 |
| 2019-01-10 | 1000 | 142.86 |
+--------------+--------------+----------------+
Explanation:
1st moving average from 2019-01-01 to 2019-01-07 has an average_amount of (100 + 110 + 120 + 130 + 110 + 140 + 150)/7 = 122.86
2nd moving average from 2019-01-02 to 2019-01-08 has an average_amount of (110 + 120 + 130 + 110 + 140 + 150 + 80)/7 = 120
3rd moving average from 2019-01-03 to 2019-01-09 has an average_amount of (120 + 130 + 110 + 140 + 150 + 80 + 110)/7 = 120
4th moving average from 2019-01-04 to 2019-01-10 has an average_amount of (130 + 110 + 140 + 150 + 80 + 110 + 130 + 150)/7 = 142.86
Solution
Tags: SQL Aggregate Functions, Advanced Select
Code
# Write your MySQL query statement below
WITH p AS (
SELECT visited_on, SUM(amount) AS amount
FROM Customer
GROUP BY visited_on
)
SELECT
visited_on,
SUM(amount) OVER(
ORDER BY visited_on DESC
ROWS BETWEEN CURRENT ROW AND 6 FOLLOWING
) as amount,
ROUND(
AVG(amount) OVER(
ORDER BY visited_on DESC
ROWS BETWEEN CURRENT ROW AND 6 FOLLOWING
),
2
) as average_amount
FROM p
ORDER BY visited_on ASC
-- ignore first 6 rows
LIMIT 18446744073709551615 OFFSET 6
;
Reference
1341. Movie Rating
Description of Problem
Table: Movies
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| movie_id | int |
| title | varchar |
+---------------+---------+
movie_id is the primary key (column with unique values) for this table.
title is the name of the movie.
Table: Users
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| user_id | int |
| name | varchar |
+---------------+---------+
user_id is the primary key (column with unique values) for this table.
Table: MovieRating
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| movie_id | int |
| user_id | int |
| rating | int |
| created_at | date |
+---------------+---------+
(movie_id, user_id) is the primary key (column with unique values) for this table.
This table contains the rating of a movie by a user in their review.
created_at is the user's review date.
Write a solution to:
- Find the name of the user who has rated the greatest number of movies. In case of a tie, return the lexicographically smaller user name.
- Find the movie name with the highest average rating in
February 2020. In case of a tie, return the lexicographically smaller movie name.
The result format is in the following example.
Example 1:
Input:
Movies table:
+-------------+--------------+
| movie_id | title |
+-------------+--------------+
| 1 | Avengers |
| 2 | Frozen 2 |
| 3 | Joker |
+-------------+--------------+
Users table:
+-------------+--------------+
| user_id | name |
+-------------+--------------+
| 1 | Daniel |
| 2 | Monica |
| 3 | Maria |
| 4 | James |
+-------------+--------------+
MovieRating table:
+-------------+--------------+--------------+-------------+
| movie_id | user_id | rating | created_at |
+-------------+--------------+--------------+-------------+
| 1 | 1 | 3 | 2020-01-12 |
| 1 | 2 | 4 | 2020-02-11 |
| 1 | 3 | 2 | 2020-02-12 |
| 1 | 4 | 1 | 2020-01-01 |
| 2 | 1 | 5 | 2020-02-17 |
| 2 | 2 | 2 | 2020-02-01 |
| 2 | 3 | 2 | 2020-03-01 |
| 3 | 1 | 3 | 2020-02-22 |
| 3 | 2 | 4 | 2020-02-25 |
+-------------+--------------+--------------+-------------+
Output:
+--------------+
| results |
+--------------+
| Daniel |
| Frozen 2 |
+--------------+
Explanation:
Daniel and Monica have rated 3 movies ("Avengers", "Frozen 2" and "Joker") but Daniel is smaller lexicographically.
Frozen 2 and Joker have a rating average of 3.5 in February but Frozen 2 is smaller lexicographically.
Solution
Tags: SQL Advanced Select
Code (MySQL)
-- Write your MySQL query statement below
(
SELECT u.name as results
FROM MovieRating r
INNER JOIN Users u
ON r.user_id = u.user_id
GROUP BY r.user_id
ORDER BY COUNT(1) DESC, u.name ASC
LIMIT 1
)
UNION ALL
(
SELECT m.title as results
FROM MovieRating r
INNER JOIN Movies m
ON r.movie_id = m.movie_id
WHERE r.created_at BETWEEN '2020-02-01' AND '2020-02-29'
GROUP BY r.movie_id
ORDER BY AVG(r.rating) DESC, m.title ASC
LIMIT 1
);
1393. Capital Gain/Loss
Description of Problem
Table: Stocks
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| stock_name | varchar |
| operation | enum |
| operation_day | int |
| price | int |
+---------------+---------+
(stock_name, operation_day) is the primary key (combination of columns with unique values) for this table.
The operation column is an ENUM (category) of type ('Sell', 'Buy')
Each row of this table indicates that the stock which has stock_name had an operation on the day operation_day with the price.
It is guaranteed that each 'Sell' operation for a stock has a corresponding 'Buy' operation in a previous day. It is also guaranteed that each 'Buy' operation for a stock has a corresponding 'Sell' operation in an upcoming day.
Write a solution to report the Capital gain/loss for each stock.
The Capital gain/loss of a stock is the total gain or loss after buying and selling the stock one or many times.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Stocks table:
+---------------+-----------+---------------+--------+
| stock_name | operation | operation_day | price |
+---------------+-----------+---------------+--------+
| Leetcode | Buy | 1 | 1000 |
| Corona Masks | Buy | 2 | 10 |
| Leetcode | Sell | 5 | 9000 |
| Handbags | Buy | 17 | 30000 |
| Corona Masks | Sell | 3 | 1010 |
| Corona Masks | Buy | 4 | 1000 |
| Corona Masks | Sell | 5 | 500 |
| Corona Masks | Buy | 6 | 1000 |
| Handbags | Sell | 29 | 7000 |
| Corona Masks | Sell | 10 | 10000 |
+---------------+-----------+---------------+--------+
Output:
+---------------+-------------------+
| stock_name | capital_gain_loss |
+---------------+-------------------+
| Corona Masks | 9500 |
| Leetcode | 8000 |
| Handbags | -23000 |
+---------------+-------------------+
Explanation:
Leetcode stock was bought at day 1 for 1000$ and was sold at day 5 for 9000$. Capital gain = 9000 - 1000 = 8000$.
Handbags stock was bought at day 17 for 30000$ and was sold at day 29 for 7000$. Capital loss = 7000 - 30000 = -23000$.
Corona Masks stock was bought at day 1 for 10$ and was sold at day 3 for 1010$. It was bought again at day 4 for 1000$ and was sold at day 5 for 500$. At last, it was bought at day 6 for 1000$ and was sold at day 10 for 10000$. Capital gain/loss is the sum of capital gains/losses for each ('Buy' --> 'Sell') operation = (1010 - 10) + (500 - 1000) + (10000 - 1000) = 1000 - 500 + 9000 = 9500$.
Solution
Tags: SQL
Code
# Write your MySQL query statement below
SELECT
stock_name,
SUM(IF(operation = 'Sell', price, 0)) - SUM(IF(operation = 'Buy', price, 0)) AS capital_gain_loss
FROM Stocks
GROUP BY stock_name
1448. Count Good Nodes in Binary Tree
Description of Problem
Given a binary tree root, a node X in the tree is named good if in the path from root to X there are no nodes with a value greater than X.
Return the number of good nodes in the binary tree.
Example 1:
Input: root = [3,1,4,3,null,1,5]
Output: 4
Explanation: Nodes in blue are good.
Root Node (3) is always a good node.
Node 4 -> (3,4) is the maximum value in the path starting from the root.
Node 5 -> (3,4,5) is the maximum value in the path
Node 3 -> (3,1,3) is the maximum value in the path.
Example 2:
Input: root = [3,3,null,4,2]
Output: 3
Explanation: Node 2 -> (3, 3, 2) is not good, because "3" is higher than it.
Example 3:
Input: root = [1]
Output: 1
Explanation: Root is considered as good.
Constraints:
- The number of nodes in the binary tree is in the range
[1, 10^5]. - Each node's value is between
[-10^4, 10^4].
Solution
Tags: Binary Tree DFS
Explanation
When doing DFS, keep track the current maximum value of the path and the answer (count of good nodes).
Code
// Definition for a binary tree node.
// #[derive(Debug, PartialEq, Eq)]
// pub struct TreeNode {
// pub val: i32,
// pub left: Option<Rc<RefCell<TreeNode>>>,
// pub right: Option<Rc<RefCell<TreeNode>>>,
// }
//
// impl TreeNode {
// #[inline]
// pub fn new(val: i32) -> Self {
// TreeNode {
// val,
// left: None,
// right: None
// }
// }
// }
use std::rc::Rc;
use std::cell::RefCell;
impl Solution {
pub fn good_nodes(root: Option<Rc<RefCell<TreeNode>>>) -> i32 {
let mut count = 0;
Self::dfs(root, i32::MIN, &mut count);
return count;
}
fn dfs(node : Option<Rc<RefCell<TreeNode>>>, max : i32, count : &mut i32){
if let Some(n) = node {
let n = n.borrow();
if n.val >= max {
*count += 1;
}
let max = max.max(n.val);
Self::dfs(n.left.clone(), max, count);
Self::dfs(n.right.clone(), max, count);
}
}
}
Complexity
- n is the number of nodes in the tree
- h is the height of the tree
Time complexity:
- \( T(n) = \Theta(n) \)
Auxiliary Space:
- \( S(n) = O(h) \)
1456. Maximum Number of Vowels in a Substring of Given Length
Description of Problem
Given a string s and an integer k, return the maximum number of vowel letters in any substring of s with length k.
Vowel letters in English are 'a', 'e', 'i', 'o', and 'u'.
Example 1:
Input: s = "abciiidef", k = 3
Output: 3
Explanation: The substring "iii" contains 3 vowel letters.
Example 2:
Input: s = "aeiou", k = 2
Output: 2
Explanation: Any substring of length 2 contains 2 vowels.
Example 3:
Input: s = "leetcode", k = 3
Output: 2
Explanation: "lee", "eet" and "ode" contain 2 vowels.
Constraints:
1 <= s.length <= 10^5sconsists of lowercase English letters.1 <= k <= s.length
Solution
Tags: Sliding Window Two Pointers
Explanation
Imagine that there is a Double-linked list (deque) that store exactly k elements:
- When a new character comes, we push it into the back of the deque and count the number of vowels.
- When we move the window, we pop the element from the front of the deque.
Code
impl Solution {
pub fn max_vowels(s: String, k: i32) -> i32 {
let mut s = s.as_bytes();
let (n,k) = (s.len(), k as usize);
let mut count = 0;
let mut max_count = 0;
for i in 0..k {
let c = s[i];
match c {
97 | 101 | 105 | 111 | 117 => {
count+=1;
},
_ => {}
}
}
max_count = max_count.max(count);
for i in k..n{
let d = s[i-k];
match d {
97 | 101 | 105 | 111 | 117 => {
count-=1;
},
_ => {}
}
let c = s[i];
match c {
97 | 101 | 105 | 111 | 117 => {
count+=1;
},
_ => {}
}
max_count = max_count.max(count);
}
return max_count;
}
}
Complexity
- n is length of String
s
Time Complexity
- \( T(n) = \Theta(n) \)
Auxiliary Space
- \( S(n) = O(1) \)
1493. Longest Subarray of 1's After Deleting One Element
Description of Problem
Given a binary array nums, you should delete one element from it.
Return the size of the longest non-empty subarray containing only 1's in the resulting array. Return 0 if there is no such subarray.
Example 1:
Input: nums = [1,1,0,1]
Output: 3
Explanation: After deleting the number in position 2, [1,1,1] contains 3 numbers with value of 1's.
Example 2:
Input: nums = [0,1,1,1,0,1,1,0,1]
Output: 5
Explanation: After deleting the number in position 4, [0,1,1,1,1,1,0,1] longest subarray with value of 1's is [1,1,1,1,1].
Example 3:
Input: nums = [1,1,1]
Output: 2
Explanation: You must delete one element.
Constraints:
1 <= nums.length <= 10^5nums[i]is either0or1.
Solution
Tags: Sliding Window Two Pointers
Explanation
If we solve 1004. Max Consecutive Ones III, we can use same code to solve this problem.
Remember to minus 1 before giving the answer. If there is no zeros, we have to minus one. If there is a zero, we also have to minus one.
Code
impl Solution {
pub fn longest_subarray(nums: Vec<i32>) -> i32 {
let (n, k) = (nums.len(), 1 as usize);
let (mut i, mut j) = (0, 0);
let mut count_zeros = 0;
let mut max = 0;
while j < n {
if nums[j] == 0 {
count_zeros+=1;
}
while count_zeros > k {
if nums[i] == 0 { count_zeros-=1; }
i+=1;
}
max = max.max(j - i + 1);
j+=1;
}
return max as i32 - 1;
}
}
Complexity
- n is length of
nums
Time Complexity
- \( T(n) = O(n) \)
Auxiliary Space
- \( S(n) = O(1) \)
1657. Determine if Two Strings Are Close
Description of Problem
Two strings are considered close if you can attain one from the other using the following operations:
- Operation 1: Swap any two existing characters.
- For example,
abcde -> aecdb
- For example,
- Operation 2: Transform every occurrence of one existing character into another existing character, and do the same with the other character.
- For example,
aacabb -> bbcbaa(alla's turn intob's, and allb's turn intoa's) You can use the operations on either string as many times as necessary.
- For example,
Given two strings, word1 and word2, return true if word1 and word2 are close, and false otherwise.
Example 1:
Input: word1 = "abc", word2 = "bca"
Output: true
Explanation: You can attain word2 from word1 in 2 operations.
Apply Operation 1: "abc" -> "acb"
Apply Operation 1: "acb" -> "bca"
Example 2:
Input: word1 = "a", word2 = "aa"
Output: false
Explanation: It is impossible to attain word2 from word1, or vice versa, in any number of operations.
Example 3:
Input: word1 = "cabbba", word2 = "abbccc"
Output: true
Explanation: You can attain word2 from word1 in 3 operations.
Apply Operation 1: "cabbba" -> "caabbb"
Apply Operation 2: "caabbb" -> "baaccc"
Apply Operation 2: "baaccc" -> "abbccc"
Constraints:
1 <= word1.length, word2.length <= 10^5word1andword2contain only lowercase English letters.
Solution 1 - using HashSet+HashMap (Not Optimised)
Tags: HashSet/HashMap
Explanation
Intutive Explanation
Two strings are close if and only if they have the same set of characters and the same list of number of occurrences unorderly.
Explanation by String Compression
By operation 1, orders of two strings do not matter. Thus, we can compress string into (cN)* format where c is character and N is number of occurrences of c; cN is ordered by c in alphabetical order. For example, cabbba becomes a2b3c1 and abbccc becomes a1b2c3. Thus, Operation 2 is equivalent to swapping numbers in compressed string.
- If two strings have different set of characters, they are not close.
- If two strings have different list of number of occurrences of characters unorderly, they are not close
- Otherwise, we can keep swapping occurrences list until its order is the same as the another list. (e.g.
231->132->123). Therefore, they are close.
Code
impl Solution {
pub fn close_strings(word1: String, word2: String) -> bool {
use std::collections::HashMap;
use std::collections::HashSet;
if (word1.len() != word2.len()){
return false;
}
let mut m1 = HashMap::new();
let mut m2 = HashMap::new();
for ch in word1.chars() {
m1.entry(ch).and_modify(|counter| *counter += 1).or_insert(1);
}
for ch in word2.chars() {
m2.entry(ch).and_modify(|counter| *counter += 1).or_insert(1);
}
let mut k1 : HashSet<_> = m1.keys().map(|&v| v ).collect();
let mut k2 : HashSet<_> = m2.keys().map(|&v| v ).collect();
if (k1 != k2){
return false;
}
let mut m1 : Vec<_> = m1.values().map(|&v| v ).collect();
let mut m2 : Vec<_> = m2.values().map(|&v| v ).collect();
m1.sort(); m2.sort();
return m1 == m2;
}
}
Complexity
- m is length of
word1 - n is legnth of
word2 - The following calculation assume there is non-ASCII characters
Time Complexity
- \( T(m,n) = O( 3m + 3n + m \lg m + n \lg n + \min(m,n) ) = O( \min(m,n) \lg \min(m,n) ) \)
O(m + n): Create 2 HashMapsO(m + n): Create 2 HashSetsO(m + n): Create 2 Vectors for occurrence.O(m \lg m + n \lg n): Sort 2 VectorsO(min(m,n)): Compare 2 Vectors
Auxiliary Space
- \( S(m,n) = O( m + n ) \)
- For HashSets, HashMaps and Vectors
Solution 2 - using Array
Tags: HashSet/HashMap
Code
impl Solution {
pub fn close_strings(word1: String, word2: String) -> bool {
if word1.len() != word2.len() { return false; }
let (mut c1, mut c2) = (vec![ 0 ; 26 ], vec![ 0 ; 26 ]);
for ch in word1.chars(){ c1[ ch as usize - 97 ] +=1; }
for ch in word2.chars(){ c2[ ch as usize - 97 ] +=1; }
for i in 0..26{
if (c1[i] > 0) ^ (c2[i] > 0) {
return false;
}
}
c1.sort();c2.sort();
return c1==c2;
}
}
Complexity
- m is length of
word1 - n is legnth of
word2
Time Complexity
- \( T(m,n) = O(m+n) \)
- Only counting depends on the input size
Auxiliary Space
- \( S(m,n) = O(1) \)
1907. Count Salary Categories
Description of the Problem
Table: Accounts
+-------------+------+
| Column Name | Type |
+-------------+------+
| account_id | int |
| income | int |
+-------------+------+
account_id is the primary key (column with unique values) for this table.
Each row contains information about the monthly income for one bank account.
Write a solution to calculate the number of bank accounts for each salary category. The salary categories are:
"Low Salary": All the salaries strictly less than $20000.
"Average Salary": All the salaries in the inclusive range [$20000, $50000].
"High Salary": All the salaries strictly greater than $50000.
The result table must contain all three categories. If there are no accounts in a category, return 0.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Accounts table:
+------------+--------+
| account_id | income |
+------------+--------+
| 3 | 108939 |
| 2 | 12747 |
| 8 | 87709 |
| 6 | 91796 |
+------------+--------+
Output:
+----------------+----------------+
| category | accounts_count |
+----------------+----------------+
| Low Salary | 1 |
| Average Salary | 0 |
| High Salary | 3 |
+----------------+----------------+
Explanation:
Low Salary: Account 2.
Average Salary: No accounts.
High Salary: Accounts 3, 6, and 8.
Solution
Tags: SQL Joins
Code (MySQL)
# Write your MySQL query statement below
SELECT 'Low Salary' as category, COUNT(1) AS accounts_count
FROM Accounts
WHERE income < 20000
UNION
SELECT 'Average Salary' as category, COUNT(1) AS accounts_count
FROM Accounts
WHERE income BETWEEN 20000 AND 50000
UNION
SELECT 'High Salary' as category, COUNT(1) AS accounts_count
FROM Accounts
WHERE income > 50000
1926. Nearest Exit from Entrance in Maze
Description of Problem
You are given an m x n matrix maze (0-indexed) with empty cells (represented as '.') and walls (represented as '+'). You are also given the entrance of the maze, where entrance = [entrancerow, entrancecol] denotes the row and column of the cell you are initially standing at.
In one step, you can move one cell up, down, left, or right. You cannot step into a cell with a wall, and you cannot step outside the maze. Your goal is to find the nearest exit from the entrance. An exit is defined as an empty cell that is at the border of the maze. The entrance does not count as an exit.
Return the number of steps in the shortest path from the entrance to the nearest exit, or -1 if no such path exists.
Example 1:
Input: maze = [["+","+",".","+"],[".",".",".","+"],["+","+","+","."]], entrance = [1,2]
Output: 1
Explanation: There are 3 exits in this maze at [1,0], [0,2], and [2,3].
Initially, you are at the entrance cell [1,2].
- You can reach [1,0] by moving 2 steps left.
- You can reach [0,2] by moving 1 step up.
It is impossible to reach [2,3] from the entrance.
Thus, the nearest exit is [0,2], which is 1 step away.
Example 2:
Input: maze = [["+","+","+"],[".",".","."],["+","+","+"]], entrance = [1,0]
Output: 2
Explanation: There is 1 exit in this maze at [1,2].
[1,0] does not count as an exit since it is the entrance cell.
Initially, you are at the entrance cell [1,0].
- You can reach [1,2] by moving 2 steps right.
Thus, the nearest exit is [1,2], which is 2 steps away.
Example 3:
Input: maze = [[".","+"]], entrance = [0,0]
Output: -1
Explanation: There are no exits in this maze.
Constraints:
maze.length == mmaze[i].length == n1 <= m, n <= 100maze[i][j]is either'.'or'+'.entrance.length == 20 <= entrancerow < m0 <= entrancecol < nentrancewill always be an empty cell.
Solution
Tags: Breadth First Search
Code
#[derive(Clone, Copy, Debug, PartialEq)]
enum Colour{
White,
Gray,
Black,
}
use Colour::{White, Gray, Black};
impl Solution {
pub fn nearest_exit(maze: Vec<Vec<char>>, entrance: Vec<i32>) -> i32 {
use std::collections::VecDeque;
let m = maze.len();
let n = maze[0].len();
let mut colours = vec![ vec![White ;n];m ];
let (i, j) = (entrance[0] as usize, entrance[1] as usize);
colours[i][j] = Black;
let mut is_exit_found = false;
let mut depth = 0;
let mut queue1 = VecDeque::new();
let mut queue2 = VecDeque::new();
queue1.push_back((i,j));
while !queue1.is_empty() && !is_exit_found{
while let Some((i,j)) = queue1.pop_front(){
// Is this node an exit?
if colours[i][j] != Black && (i == 0 || i == m - 1 || j == 0 || j == n - 1) {
is_exit_found = true;
break;
}
// UP
if Self::is_available(&maze, &colours, i-1, j, m, n) {
colours[i-1][j] = Gray;
queue2.push_back((i-1 as usize, j as usize));
}
// LEFT
if Self::is_available(&maze, &colours, i, j-1, m, n) {
colours[i][j-1] = Gray;
queue2.push_back((i as usize,j-1 as usize));
}
// RIGHT
if Self::is_available(&maze, &colours, i, j+1, m, n) {
colours[i][j+1] = Gray;
queue2.push_back((i as usize,j+1 as usize));
}
// BOTTOM
if Self::is_available(&maze, &colours, i+1, j, m, n) {
colours[i+1][j] = Gray;
queue2.push_back((i+1 as usize,j as usize));
}
// Finish the exploration of the node
colours[i][j] = Black;
}
depth+=1;
let temp = queue1;
queue1 = queue2;
queue2 = temp;
}
return if is_exit_found {depth - 1} else {-1};
}
#[inline(always)]
fn is_available(
maze: &Vec<Vec<char>>,
colours : &Vec<Vec<Colour>>,
i : usize,
j : usize,
m : usize,
n : usize
) -> bool {
return
0 <= i && i < m
&& 0 <= j && j < n
&& maze[i][j] == '.'
&& colours[i][j] == White
;
}
}
Complexity
- \(|V|\) is the number of non-wall nodes in graph
- \(|E|\) is the number of edges linked non-wall nodes in graph
Time Complexity
- \(T(|V|,|E|) = O(|V|)\)
1934. Confirmation Rate
Description of Problem
Table: Signups
+----------------+----------+
| Column Name | Type |
+----------------+----------+
| user_id | int |
| time_stamp | datetime |
+----------------+----------+
user_id is the column of unique values for this table.
Each row contains information about the signup time for the user with ID user_id.
Table: Confirmations
+----------------+----------+
| Column Name | Type |
+----------------+----------+
| user_id | int |
| time_stamp | datetime |
| action | ENUM |
+----------------+----------+
(user_id, time_stamp) is the primary key (combination of columns with unique values) for this table.
user_id is a foreign key (reference column) to the Signups table.
action is an ENUM (category) of the type ('confirmed', 'timeout')
Each row of this table indicates that the user with ID user_id requested a confirmation message at time_stamp and that confirmation message was either confirmed ('confirmed') or expired without confirming ('timeout').
The confirmation rate of a user is the number of 'confirmed' messages divided by the total number of requested confirmation messages. The confirmation rate of a user that did not request any confirmation messages is 0. Round the confirmation rate to two decimal places.
Write a solution to find the confirmation rate of each user.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Signups table:
+---------+---------------------+
| user_id | time_stamp |
+---------+---------------------+
| 3 | 2020-03-21 10:16:13 |
| 7 | 2020-01-04 13:57:59 |
| 2 | 2020-07-29 23:09:44 |
| 6 | 2020-12-09 10:39:37 |
+---------+---------------------+
Confirmations table:
+---------+---------------------+-----------+
| user_id | time_stamp | action |
+---------+---------------------+-----------+
| 3 | 2021-01-06 03:30:46 | timeout |
| 3 | 2021-07-14 14:00:00 | timeout |
| 7 | 2021-06-12 11:57:29 | confirmed |
| 7 | 2021-06-13 12:58:28 | confirmed |
| 7 | 2021-06-14 13:59:27 | confirmed |
| 2 | 2021-01-22 00:00:00 | confirmed |
| 2 | 2021-02-28 23:59:59 | timeout |
+---------+---------------------+-----------+
Output:
+---------+-------------------+
| user_id | confirmation_rate |
+---------+-------------------+
| 6 | 0.00 |
| 3 | 0.00 |
| 7 | 1.00 |
| 2 | 0.50 |
+---------+-------------------+
Explanation:
User 6 did not request any confirmation messages. The confirmation rate is 0.
User 3 made 2 requests and both timed out. The confirmation rate is 0.
User 7 made 3 requests and all were confirmed. The confirmation rate is 1.
User 2 made 2 requests where one was confirmed and the other timed out. The confirmation rate is 1 / 2 = 0.5.
Solution
Tags: SQL Aggregate Functions
Code 1 (MySQL)
-- Write your MySQL query statement below
SELECT s.user_id,
ROUND(
IF(
c.user_id IS NULL,
0,
SUM(IF(action = 'confirmed',1,0)) / COUNT(1)
),
2
) AS confirmation_rate
FROM Signups s
LEFT JOIN Confirmations c
ON s.user_id = c.user_id
GROUP BY s.user_id;
Code 2 (MySQL) - Optimised
-- Write your MySQL query statement below
SELECT s.user_id, ROUND(AVG(IF(action = 'confirmed',1,0)), 2) AS confirmation_rate
FROM Signups s
LEFT JOIN Confirmations c
ON s.user_id = c.user_id
GROUP BY s.user_id;
2095. Delete the Middle Node of a Linked List
Description of the Problem
You are given the head of a linked list. Delete the middle node, and return the head of the modified linked list.
The middle node of a linked list of size n is the ⌊n / 2⌋th node from the start using 0-based indexing, where ⌊x⌋ denotes the largest integer less than or equal to x.
For n = 1, 2, 3, 4, and 5, the middle nodes are 0, 1, 1, 2, and 2, respectively.
Example 1:
Input: head = [1,3,4,7,1,2,6]
Output: [1,3,4,1,2,6]
Explanation:
The above figure represents the given linked list. The indices of the nodes are written below.
Since n = 7, node 3 with value 7 is the middle node, which is marked in red.
We return the new list after removing this node.
Example 2:
Input: head = [1,2,3,4]
Output: [1,2,4]
Explanation:
The above figure represents the given linked list.
For n = 4, node 2 with value 3 is the middle node, which is marked in red.
Example 3:
Input: head = [2,1]
Output: [2]
Explanation:
The above figure represents the given linked list.
For n = 2, node 1 with value 1 is the middle node, which is marked in red.
Node 0 with value 2 is the only node remaining after removing node 1.
Constraints:
- The number of nodes in the list is in the range [1, 10^5].
- 1 <= Node.val <= 10^5
Solution
Tags: Fast-Slow Pointer
Explanation
It is almost the same as 876. Middle of the Linked List except we want both pointers move to left by 1 for deletion at the end of the loop.
To acheive this, we have to make sure that there is at least 3 nodes after the faster pointer before an iteration of loop. Hence, at the termination of the loop, the number of node must less than 3. The slow pointer always point to the previous node of the middle node.
Code (Java)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode deleteMiddle(ListNode head){
if (head == null || head.next == null)
return null;
ListNode slow = head;
ListNode fast = head;
while (fast.next != null && fast.next.next != null && fast.next.next.next != null){
slow = slow.next;
fast = fast.next.next;
}
slow.next = slow.next.next;
return head;
}
}
Code (C++)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteMiddle(ListNode* head) {
if (head == nullptr || head->next == nullptr)
return nullptr;
ListNode * slow = head;
ListNode * fast = head;
while (
fast->next != nullptr
&& fast->next->next != nullptr
&& fast->next->next->next != nullptr
){
slow = slow->next;
fast = fast->next->next;
}
slow->next = slow->next->next;
return head;
}
};
Complexity
Time complexity:
- \(T(n) = O(n/2)\)
Auxiliary Space:
- \(S(n) = O(1)\)
2130. Maximum Twin Sum of a Linked List
Description of Problem
In a linked list of size n, where n is even, the ith node (0-indexed) of the linked list is known as the twin of the (n-1-i)th node, if 0 <= i <= (n / 2) - 1.
- For example, if
n = 4, then node 0 is the twin of node3, and node 1`` is the twin of node2. These are the only nodes with twins forn = 4.
The twin sum is defined as the sum of a node and its twin.
Given the head of a linked list with even length, return the maximum twin sum of the linked list.
Example 1:
Input: head = [5,4,2,1]
Output: 6
Explanation:
Nodes 0 and 1 are the twins of nodes 3 and 2, respectively. All have twin sum = 6.
There are no other nodes with twins in the linked list.
Thus, the maximum twin sum of the linked list is 6.
Example 2:
Input: head = [4,2,2,3]
Output: 7
Explanation:
The nodes with twins present in this linked list are:
- Node 0 is the twin of node 3 having a twin sum of 4 + 3 = 7.
- Node 1 is the twin of node 2 having a twin sum of 2 + 2 = 4.
Thus, the maximum twin sum of the linked list is max(7, 4) = 7.
Example 3:
Input: head = [1,100000]
Output: 100001
Explanation:
There is only one node with a twin in the linked list having twin sum of 1 + 100000 = 100001.
Constraints:
- The number of nodes in the list is an even integer in the range
[2, 105]. 1 <= Node.val <= 10^5
Solution 1 - using extra space
Tags: LinkedList
Explanation
- Calculate the length of the linkedlist.
- Loop over the first-half list: store values into the stack.
- Loop over the second-half list:
- Remove values from the top of the stack.
- Calculate the sum of the value from the stack and current value.
- Calculate maximum sum.
Code
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
int pairSum(ListNode* head) {
int length = 0;
ListNode * curr = head;
while(curr != nullptr){
length++;
curr = curr->next;
}
int ans = INT_MIN;
int halfLength = length / 2;
vector<int> v;
curr = head;
while(curr != nullptr){
if (length <= halfLength){
ans = max(ans, curr->val + v.back());
v.pop_back();
}else{
v.push_back(curr->val);
}
length--;
curr = curr->next;
}
return ans;
}
};
Complexity
- n is length of the linkedlist
Time Complexity
- \(T(n) = \Theta(n) \)
Auxiliary Space
- \(S(n) = \Theta(n) \)
Solution 2 - Cut, Reverse and Combine
Tags: LinkedList Two Pointers
Code
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
int pairSum(ListNode* head) {
ListNode * slow = head;
ListNode * fast = head;
// Cut the list
while(fast->next != nullptr && fast->next->next != nullptr){
slow = slow->next;
fast = fast->next->next;
}
fast = slow->next;
slow->next = nullptr;
// Reverse the second-half list
ListNode * prev = nullptr;
ListNode * curr = fast;
ListNode * node;
while( (node = curr) != nullptr ){
curr = node->next;
node->next = prev;
prev = node;
}
// Combine two lists
ListNode * h1 = head;
ListNode * h2 = prev;
int ans = INT_MIN;
while (h1 != nullptr && h2 != nullptr){
ans = max(ans, h1->val + h2->val);
h1 = h1->next;
h2 = h2->next;
}
return ans;
}
};
Complexity
- n is length of the linkedlist
Time Complexity
- \(T(n) = \Theta(n) \)
Auxiliary Space
- \(S(n) = O(1) \)
2336. Smallest Number in Infinite Set
Description of Problem
You have a set which contains all positive integers [1, 2, 3, 4, 5, ...].
Implement the SmallestInfiniteSet class:
SmallestInfiniteSet()Initializes the SmallestInfiniteSet object to contain all positive integers.int popSmallest()Removes and returns the smallest integer contained in the infinite set.void addBack(int num)Adds a positive integernumback into the infinite set, if it is not already in the infinite set.
Example 1:
Input
["SmallestInfiniteSet", "addBack", "popSmallest", "popSmallest", "popSmallest", "addBack", "popSmallest", "popSmallest", "popSmallest"]
[[], [2], [], [], [], [1], [], [], []]
Output
[null, null, 1, 2, 3, null, 1, 4, 5]
Explanation
SmallestInfiniteSet smallestInfiniteSet = new SmallestInfiniteSet();
smallestInfiniteSet.addBack(2); // 2 is already in the set, so no change is made.
smallestInfiniteSet.popSmallest(); // return 1, since 1 is the smallest number, and remove it from the set.
smallestInfiniteSet.popSmallest(); // return 2, and remove it from the set.
smallestInfiniteSet.popSmallest(); // return 3, and remove it from the set.
smallestInfiniteSet.addBack(1); // 1 is added back to the set.
smallestInfiniteSet.popSmallest(); // return 1, since 1 was added back to the set and
// is the smallest number, and remove it from the set.
smallestInfiniteSet.popSmallest(); // return 4, and remove it from the set.
smallestInfiniteSet.popSmallest(); // return 5, and remove it from the set.
Constraints:
1 <= num <= 1000- At most
1000calls will be made in total topopSmallestandaddBack.
Solution
Tags: BTree,Divide and Conquer
Explanation
Divide the data strcture into two parts: finite set (using BTree) and infinite set (using current smallest integer).
Code (Rust)
use std::collections::{BTreeSet,HashSet};
use std::cmp::Reverse;
struct SmallestInfiniteSet {
tree_in_finite : BTreeSet<i32>,
smallest_in_infinite : i32,
}
/**
* `&self` means the method takes an immutable reference.
* If you need a mutable reference, change it to `&mut self` instead.
*/
impl SmallestInfiniteSet {
fn new() -> Self {
SmallestInfiniteSet {
tree_in_finite : BTreeSet::new(),
smallest_in_infinite : 1,
}
}
fn pop_smallest(&mut self) -> i32 {
if let Some(smallest) = self.tree_in_finite.pop_first() {
return smallest;
}
else{
let smallest = self.smallest_in_infinite;
self.smallest_in_infinite += 1;
return smallest;
}
}
fn add_back(&mut self, num: i32) {
if num >= self.smallest_in_infinite {
// ignore the number
}else {
// put the number into finite_part
self.tree_in_finite.insert(num);
}
}
}
/**
* Your SmallestInfiniteSet object will be instantiated and called as such:
* let obj = SmallestInfiniteSet::new();
* let ret_1: i32 = obj.pop_smallest();
* obj.add_back(num);
*/
2352. Equal Row and Column Pairs
Description of Problem
Given a 0-indexed n x n integer matrix grid, return the number of pairs (ri, cj) such that row ri and column cj are equal.
A row and column pair is considered equal if they contain the same elements in the same order (i.e., an equal array).
Example 1:
Input: grid = [[3,2,1],[1,7,6],[2,7,7]]
Output: 1
Explanation: There is 1 equal row and column pair:
- (Row 2, Column 1): [2,7,7]
Example 2:
Input: grid = [[3,1,2,2],[1,4,4,5],[2,4,2,2],[2,4,2,2]]
Output: 3
Explanation: There are 3 equal row and column pairs:
- (Row 0, Column 0): [3,1,2,2]
- (Row 2, Column 2): [2,4,2,2]
- (Row 3, Column 2): [2,4,2,2]
Constraints:
n == grid.length == grid[i].length1 <= n <= 2001 <= grid[i][j] <= 10^5
Solution
Code (Rust)
impl Solution {
pub fn equal_pairs(grid: Vec<Vec<i32>>) -> i32 {
use std::collections::HashMap;
let n = grid.len();
let mut map = HashMap::new();
for j in 0..n{
let mut v = Vec::new();
for k in 0..n{
v.push(grid[k][j]);
}
if let Some(c) = map.get_mut(&v){
*c +=1;
}else{
map.insert(v, 1);
}
}
let mut count = 0;
for row in grid.iter() {
if let Some(&c) = map.get(row){
count+=c;
}
}
return count;
}
}
Complexity
- Assume hash query costs constant time
Time Complexity
- \(T(n) = \Theta(n)\)
Auxiliary Space
- \(S(n) = O(1)\)
2390. Removing Stars From a String
Description
You are given a string s, which contains stars *.
In one operation, you can:
- Choose a star in
s. - Remove the closest non-star character to its left, as well as remove the star itself. Return the string after all stars have been removed.
Note:
- The input will be generated such that the operation is always possible.
- It can be shown that the resulting string will always be unique.
Example 1:
Input: s = "leet**cod*e"
Output: "lecoe"
Explanation: Performing the removals from left to right:
- The closest character to the 1st star is 't' in "leet**cod*e". s becomes "lee*cod*e".
- The closest character to the 2nd star is 'e' in "lee*cod*e". s becomes "lecod*e".
- The closest character to the 3rd star is 'd' in "lecod*e". s becomes "lecoe".
There are no more stars, so we return "lecoe".
Example 2:
Input: s = "erase*****"
Output: ""
Explanation: The entire string is removed, so we return an empty string.
Constraints:
1 <= s.length <= 10^5sconsists of lowercase English letters and stars*.- The operation above can be performed on
s.
Solution
Code (Rust)
impl Solution {
pub fn remove_stars(s: String) -> String {
let mut v = vec![];
for &b in s.as_bytes(){
if b == 42 {
v.pop();
}else{
v.push(b);
}
}
return String::from_utf8(v).unwrap();
}
}
Complexity
- n the length of
s
Time Complexity
- \(T(n) = \Theta(n)\)
Auxiliary Space
- \(S(n) = O(1)\)
- The stack will be consumed by the returned string. Therefore, cost constant space.
2807. Insert Greatest Common Divisors in Linked List
Description of the Problem
Given the head of a linked list head, in which each node contains an integer value.
Between every pair of adjacent nodes, insert a new node with a value equal to the greatest common divisor of them.
Return the linked list after insertion.
The greatest common divisor of two numbers is the largest positive integer that evenly divides both numbers.
Example 1:
Input: head = [18,6,10,3]
Output: [18,6,6,2,10,1,3]
Explanation: The 1st diagram denotes the initial linked list and the 2nd diagram denotes the linked list after inserting the new nodes (nodes in blue are the inserted nodes).
- We insert the greatest common divisor of 18 and 6 = 6 between the 1st and the 2nd nodes.
- We insert the greatest common divisor of 6 and 10 = 2 between the 2nd and the 3rd nodes.
- We insert the greatest common divisor of 10 and 3 = 1 between the 3rd and the 4th nodes.
There are no more adjacent nodes, so we return the linked list.
Example 2:
Input: head = [7]
Output: [7]
Explanation: The 1st diagram denotes the initial linked list and the 2nd diagram denotes the linked list after inserting the new nodes.
There are no pairs of adjacent nodes, so we return the initial linked list.
Constraints:
- The number of nodes in the list is in the range
[1, 5000]. 1 <= Node.val <= 1000
Solution
Code (C++)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* insertGreatestCommonDivisors(ListNode* head) {
if (head == nullptr || head->next == nullptr){
return head;
}
ListNode* p1 = head;
ListNode* p2 = head->next;
while(p1!= nullptr && p2!=nullptr){
int val = gcd(p1->val, p2->val);
ListNode* gcdNode = new ListNode(val);
p1->next = gcdNode;
gcdNode->next = p2;
p1 = p2;
p2 = p2->next;
}
return head;
}
inline int gcd(int a, int b){
while (b != 0){
int temp = a % b;
a = b;
b = temp;
}
return a;
}
};
Complexity
- n is number of elements in the LinkedList
Time complexity:
- \( O(n) \)
Auxiliary Space:
- \( O(1) \)
3220. Odd and Even Transactions
Description of Problem
Table: transactions
+------------------+------+
| Column Name | Type |
+------------------+------+
| transaction_id | int |
| amount | int |
| transaction_date | date |
+------------------+------+
The transactions_id column uniquely identifies each row in this table.
Each row of this table contains the transaction id, amount and transaction date.
Write a solution to find the sum of amounts for odd and even transactions for each day. If there are no odd or even transactions for a specific date, display as 0.
Return the result table ordered by transaction_date in ascending order.
The result format is in the following example.
Solution
Tags: SQL
Code (MySQL)
SELECT
transaction_date,
SUM( IF( MOD(amount, 2) = 1, amount, 0) ) AS odd_sum,
SUM( IF( MOD(amount, 2) = 0, amount, 0) ) AS even_sum
FROM transactions
GROUP BY transaction_date
ORDER BY transaction_date
60. Permutation Sequence
Description of the Problem
The set [1, 2, 3, ..., n] contains a total of n! unique permutations.
By listing and labeling all of the permutations in order, we get the following sequence for n = 3:
"123""132""213""231""312""321"
Given n and k, return the kth permutation sequence.
Example 1:
Input: n = 3, k = 3
Output: "213"
Example 2:
Input: n = 4, k = 9
Output: "2314"
Example 3:
Input: n = 3, k = 1
Output: "123"
Constraints:
1 <= n <= 91 <= k <= n!
Solution
Tags: Permutation and Combination
*The following explanation assume 0-based indexing which is different from the problem*
Explanation
\[ n! = \underbrace{n}_{\text{#possible choices for 1st element}} \cdot \underbrace{(n-1)!} _ {\text{#permutation start with specific element}} \]
Example: n = 4, k = 13
0: 1234 6: 2134 12: 3124 18: 4123
1: 1243 7: 2143 13: 3142 19: 4132
2: 1324 8: 2314 14: 3214 20: 4213
3: 1342 9: 2341 15: 3241 21: 4231
4: 1423 10: 2413 16: 3412 22: 4312
5: 1432 11: 2431 17: 3421 23: 4321
Solution: 3142
Because:
\[
\underbrace{2} _{3!\text{: choose arr[2] from[1,2,3,4]}} \
\underbrace{0} _{2!\text{: choose arr[0] from[1,2,4]}} \
\underbrace{1} _{1!\text{: choose arr[1] from[2,4]}} \
\underbrace{0} _{0!\text{: choose arr[0] from[2]}}
\]
As we see, there are \( (n−1)! \) permutations start with some particular element.
Thus, the element we want to find is in position \(\left \lfloor \frac{index}{(n-1)!} \right \rfloor\) in sorted array.
For the permutation of remaining (n-1) elements, the index for this sub-permutation will be \( \text{index} \ mod (n−1)! \) because \(divisor \cdot quotient + remainder = original \ number\).
Therefore, we can use the same method for (\(n-1)\) elements with \(\text{index′}=\text{index} \ mod (n−1)! \)
Code (Rust)
impl Solution {
fn fact(n: usize) -> usize{
if n <= 1 {
1
}else{
(2..=n).product()
}
}
fn dfs( choice : Vec<usize>, index: usize) -> String{
if choice.is_empty() {
return String::from("");
}
if index == 0 {
return choice.into_iter().map(|x| x.to_string()).collect::<String>();
}
let mut choice = choice;
let group_size = Solution::fact(choice.len() - 1);
let group_index = index / group_size;
let subgroup_index = index % group_size;
let left = choice.remove(group_index).to_string();
let right = Solution::dfs(choice,subgroup_index);
return [left, right].join("");
}
pub fn get_permutation(n: i32, k: i32) -> String{
let n = n as usize;
let k = k as usize;
let mut choice = (1..=n).collect::<Vec<usize>>();
return Solution::dfs(choice, k - 1);
}
}
Complexity
Time Complexity
- \(T(n) = \mathcal{\Theta(n)}\)
Auxiliary Space
- \(S(n) = \mathcal{\Theta(n)}\)
65. Valid Number
Description of the Problem
A valid number can be split up into these components (in order):
- A decimal number or an integer.
- (Optional) An
'e'or'E', followed by an integer.
A decimal number can be split up into these components (in order):
- (Optional) A sign character (either
'+'or'-'). - One of the following formats:
- One or more digits, followed by a dot
'.'. - One or more digits, followed by a dot
'.', followed by one or more digits. - A dot
'.', followed by one or more digits.
- One or more digits, followed by a dot
An integer can be split up into these components (in order):
- (Optional) A sign character (either
'+'or'-'). - One or more digits.
For example, all the following are valid numbers: ["2", "0089", "-0.1", "+3.14", "4.", "-.9", "2e10", "-90E3", "3e+7", "+6e-1", "53.5e93", "-123.456e789"], while the following are not valid numbers: ["abc", "1a", "1e", "e3", "99e2.5", "--6", "-+3", "95a54e53"].
Given a string s, return true if s is a valid number.
Example 1:
Input: s = "0"
Output: true
Example 2:
Input: s = "e"
Output: false
Example 3:
Input: s = "."
Output: false
Constraints:
1 <= s.length <= 20sconsists of only English letters (both uppercase and lowercase), digits (0-9), plus'+', minus'-', or dot'.'.
Solution
Tags: Parsing
For any problem about format. I suggest every one first to write a Extended Backus-Naur Form or Regular Expression to represent correct format.
We can split the string by special char such as e, E and . and check the validity of substrings.
Explanation
Extended Backus-Naur Form of Valid Number
\( \langle goal \rangle ::= (\text{'+'} | \text{'-'})? \langle base \rangle ((\text{'e'}|\text{'E'})?\langle expo \rangle )? \)
\(\langle expo \rangle ::= (\text{'+'} | \text{'-'})? \langle digits \rangle \)
\(\langle base \rangle ::= \langle digits \rangle \)
\( \ | \langle digits \rangle \text{'.'} \)
\( \ | \ \text{'.'} \langle digits \rangle \)
\( \ | \langle digits \rangle \text{'.'} \langle digits \rangle \)
\( \langle digits \rangle ::= (\text{'0'} | \text{'1'} | ... | \text{'9'})^+ \)
Code (Rust)
impl Solution {
fn split_at_char(s: &str, v : char) -> (&str, &str){
let option_index = s.find(v);
return match option_index {
Some(index) => {
let len = s.len();
// Exclude the character we found
return (&s[0..index], &s[index+1..len]);
},
None => (s, &""),
}
}
#[inline]
fn process_first_char( s : &str) -> &str{
return if s.len() > 0 {
if s[0..1].find("+").is_some() || s[0..1].find("-").is_some() {&s[1..]} else {s}
}
else {
s
};
}
fn is_digits(s: &str, is_empty_true : bool) -> bool{
for c in s.chars() {
match c {
'0'..='9' => {},
_ => {return false;},
}
}
return if s == "" { is_empty_true } else { true };
}
fn is_signed_digits(s: &str, is_empty_true : bool) -> bool{
let s = Solution::process_first_char(s);
return Solution::is_digits(s, is_empty_true);
}
// Principal function of Solution
pub fn is_number(s: String) -> bool {
if s.len() == 0 {
return false;
}
let s = Solution::process_first_char(&s);
// Determine 'e' or 'E'
let char_e = match ( s.find('e'), s.find('E') ) {
(None,None) => { '\0' }, // dummy value
(None,Some(_)) => { 'E' },
(Some(_),None) => { 'e' },
(Some(_),Some(_)) => { 'e' },
};
let (base, expo) = Solution::split_at_char(s, char_e);
let (lhs, rhs) = Solution::split_at_char(base, '.');
let (has_dot, has_e) = (
s.find('.').is_some(),
s.find('e').is_some() || s.find('E').is_some()
);
return match (has_dot, has_e) {
// Case: <base> ('e'|'E') <expo>
(true, true) =>
(lhs.len() > 0 || rhs.len() > 0) &&
Solution::is_digits(lhs, true) &&
Solution::is_digits(rhs, true) &&
Solution::is_signed_digits(expo, false),
// Case: <lhs>? '.' <rhs>?
// => <lhs> '.' <rhs>
// => '.' <rhs>
// => <lhs> '.'
(true, false) =>
(lhs.len() > 0 || rhs.len() >0) &&
Solution::is_digits(lhs, true) &&
Solution::is_digits(rhs, true),
// Case: <base> ('e'|'E') <expo>
(false, true) =>
Solution::is_digits(lhs, false) &&
Solution::is_signed_digits(expo, false),
// Case: <base>
(false, false) => Solution::is_digits(lhs, false),
};
}
}
Complexity (n is the length of string)
Time complexity:
- \( T(n) = \Theta(n) \)
Auxiliary Space:
- \( S(n) = O(1) \)
Further Discussion
It is not difficult to see that this type of problems (i.e. Parsing) can be easily to solved by Haskell (Especially if we use Parser library such as ParSec). If I were an interviewee I would argue that it is suitable to use functional programming language instead of the imperative one.
185. Department Top Three Salaries
Description of Problem
Table: Employee
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| id | int |
| name | varchar |
| salary | int |
| departmentId | int |
+--------------+---------+
id is the primary key (column with unique values) for this table.
departmentId is a foreign key (reference column) of the ID from the Department table.
Each row of this table indicates the ID, name, and salary of an employee. It also contains the ID of their department.
Table: Department
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| name | varchar |
+-------------+---------+
id is the primary key (column with unique values) for this table.
Each row of this table indicates the ID of a department and its name.
A company's executives are interested in seeing who earns the most money in each of the company's departments. A high earner in a department is an employee who has a salary in the top three unique salaries for that department.
Write a solution to find the employees who are high earners in each of the departments.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Employee table:
+----+-------+--------+--------------+
| id | name | salary | departmentId |
+----+-------+--------+--------------+
| 1 | Joe | 85000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
| 7 | Will | 70000 | 1 |
+----+-------+--------+--------------+
Department table:
+----+-------+
| id | name |
+----+-------+
| 1 | IT |
| 2 | Sales |
+----+-------+
Output:
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| IT | Joe | 85000 |
| IT | Randy | 85000 |
| IT | Will | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
+------------+----------+--------+
Explanation:
In the IT department:
- Max earns the highest unique salary
- Both Randy and Joe earn the second-highest unique salary
- Will earns the third-highest unique salary
In the Sales department:
- Henry earns the highest salary
- Sam earns the second-highest salary
- There is no third-highest salary as there are only two employees
Solution 1 - Using ROW_NUMBER() and PARTITION BY
Tags: SQL Grouping Joins
-- Write your MySQL query statement below
WITH p AS (
SELECT
ROW_NUMBER() OVER (
PARTITION BY departmentId
ORDER BY salary DESC
) AS row_num,
salary,
departmentId
FROM Employee
GROUP BY departmentId, salary
)
SELECT
(SELECT name FROM Department d WHERE d.id = e.departmentId) AS Department,
e.name AS Employee,
e.salary AS Salary
FROM Employee e
INNER JOIN p
ON e.departmentId = p.departmentId
AND e.salary = p.salary
WHERE row_num <= 3
;
Solution 2 - Using Subquery
Tags: SQL Subquery
-- Write your MySQL query statement below
SELECT
(SELECT d.name FROM Department d WHERE d.id = e1.departmentId) AS Department,
e1.name AS Employee,
e1.salary AS Salary
FROM Employee e1
-- The count of "higher salary in the same department" is smaller than 3
WHERE 3 > (
SELECT COUNT(DISTINCT e2.salary)
FROM Employee e2
WHERE e1.salary < e2.salary
AND e1.departmentId = e2.departmentId
);
239. Sliding Window Maximum
Description of the Problem
You are given an array of integers nums, there is a sliding window of size k which is moving from the very left of the array to the very right. You can only see the k numbers in the window. Each time the sliding window moves right by one position.
Return the max sliding window.
Example 1:
Input: nums = [1,3,-1,-3,5,3,6,7], k = 3
Output: [3,3,5,5,6,7]
Explanation:
Window position Max
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7
Example 2:
Input: nums = [1], k = 1
Output: [1]
Constraints:
1 <= nums.length <= 10^5-10^4 <= nums[i] <= 10^41 <= k <= nums.length
Solution
Tags: Sliding Window Deque
The idea of solution is not largely come from myself. However, I would provide my explanation to show the correctness of the method.
Explanation
Use Deque with some constrains
Without loss of generality, assume the Deque stores tuples (i, x) where i is the index of x in array nums
Loop Invariant of the Deque \(d\): In j-th iteration, if the Deque \(d\) is not empty, then the following must be true
- \( j \le d.head \land d.tail \lt j + k \ \) where \(k\) is the size of window
- For any pair of tuples \((i, x)\), \((j, y)\) in the Deque \(d\): If \((i, x)\) is stored before \((j, y)\), then \(x\) must greater than \(y\). In other word, the Deque stores elements in descending order.
(1) is to ensure the values in the Deque are in the current window.
(2) is to ensure that the head of the Deque is always the largest element.
To make (1) true, remove 1 element from the head when moving window to the right
To make (2) true, before inserting the right-most element, remove all smaller elements from the tail.
Code (Java)
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
int n = nums.length;
int [] ans = new int[ n - k + 1 ];
Deque<Integer> q = new LinkedList<>();
for(int j = 0; j < k; j++){
while(q.size() != 0 && nums[q.peekLast()] < nums[j]){
q.pollLast();
}
q.offerLast(j);
}
ans[0] = nums[q.peekFirst()];
for(int i = 1; i <= n - k; i++){
while(q.size() != 0 && q.peekFirst() < i){
q.pollFirst();
}
while(q.size() != 0 && nums[q.peekLast()] < nums[i + k - 1]){
q.pollLast();
}
q.offerLast(i + k - 1);
ans[i] = nums[q.peekFirst()];
}
return ans;
}
}
262. Trips and Users
Description of Problem
Table: Trips
+-------------+----------+
| Column Name | Type |
+-------------+----------+
| id | int |
| client_id | int |
| driver_id | int |
| city_id | int |
| status | enum |
| request_at | varchar |
+-------------+----------+
id is the primary key (column with unique values) for this table.
The table holds all taxi trips. Each trip has a unique id, while client_id and driver_id are foreign keys to the users_id at the Users table.
Status is an ENUM (category) type of ('completed', 'cancelled_by_driver', 'cancelled_by_client').
Table: Users
+-------------+----------+
| Column Name | Type |
+-------------+----------+
| users_id | int |
| banned | enum |
| role | enum |
+-------------+----------+
users_id is the primary key (column with unique values) for this table.
The table holds all users. Each user has a unique users_id, and role is an ENUM type of ('client', 'driver', 'partner').
banned is an ENUM (category) type of ('Yes', 'No').
The cancellation rate is computed by dividing the number of canceled (by client or driver) requests with unbanned users by the total number of requests with unbanned users on that day.
Write a solution to find the cancellation rate of requests with unbanned users (both client and driver must not be banned) each day between "2013-10-01" and "2013-10-03". Round Cancellation Rate to two decimal points.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input:
Trips table:
+----+-----------+-----------+---------+---------------------+------------+
| id | client_id | driver_id | city_id | status | request_at |
+----+-----------+-----------+---------+---------------------+------------+
| 1 | 1 | 10 | 1 | completed | 2013-10-01 |
| 2 | 2 | 11 | 1 | cancelled_by_driver | 2013-10-01 |
| 3 | 3 | 12 | 6 | completed | 2013-10-01 |
| 4 | 4 | 13 | 6 | cancelled_by_client | 2013-10-01 |
| 5 | 1 | 10 | 1 | completed | 2013-10-02 |
| 6 | 2 | 11 | 6 | completed | 2013-10-02 |
| 7 | 3 | 12 | 6 | completed | 2013-10-02 |
| 8 | 2 | 12 | 12 | completed | 2013-10-03 |
| 9 | 3 | 10 | 12 | completed | 2013-10-03 |
| 10 | 4 | 13 | 12 | cancelled_by_driver | 2013-10-03 |
+----+-----------+-----------+---------+---------------------+------------+
Users table:
+----------+--------+--------+
| users_id | banned | role |
+----------+--------+--------+
| 1 | No | client |
| 2 | Yes | client |
| 3 | No | client |
| 4 | No | client |
| 10 | No | driver |
| 11 | No | driver |
| 12 | No | driver |
| 13 | No | driver |
+----------+--------+--------+
Output:
+------------+-------------------+
| Day | Cancellation Rate |
+------------+-------------------+
| 2013-10-01 | 0.33 |
| 2013-10-02 | 0.00 |
| 2013-10-03 | 0.50 |
+------------+-------------------+
Explanation:
On 2013-10-01:
- There were 4 requests in total, 2 of which were canceled.
- However, the request with Id=2 was made by a banned client (User_Id=2), so it is ignored in the calculation.
- Hence there are 3 unbanned requests in total, 1 of which was canceled.
- The Cancellation Rate is (1 / 3) = 0.33
On 2013-10-02:
- There were 3 requests in total, 0 of which were canceled.
- The request with Id=6 was made by a banned client, so it is ignored.
- Hence there are 2 unbanned requests in total, 0 of which were canceled.
- The Cancellation Rate is (0 / 2) = 0.00
On 2013-10-03:
- There were 3 requests in total, 1 of which was canceled.
- The request with Id=8 was made by a banned client, so it is ignored.
- Hence there are 2 unbanned request in total, 1 of which were canceled.
- The Cancellation Rate is (1 / 2) = 0.50
Solution
Tags: SQL
Explanation
Simple Math (An unbanned request means a request made by a client who is not banned): \[ \begin{align} \frac{ \text{#unbanned requests cancelled} }{ \text{#unbanned requests} } = & \frac{ \text{#unbanned requests cancelled by client} }{ \text{#unbanned requests} } \\ \text{} & + \frac{ \text{#unbanned requests cancelled by driver} }{ \text{#unbanned requests} } \end{align} \]
Code (MySQL)
WITH
d AS (
SELECT
request_at AS day,
SUM(IF(status = 'cancelled_by_driver', 1, 0)) / COUNT('X') AS cancel_rate
FROM Trips t
WHERE EXISTS (
SELECT 'X'
FROM Users u
WHERE u.users_id = t.driver_id
AND banned = 'No'
) AND EXISTS (
SELECT 'X'
FROM Users u
WHERE u.users_id = t.client_id
AND banned = 'No'
) AND request_at BETWEEN '2013-10-01' AND '2013-10-03'
GROUP BY request_at
),
c AS (
SELECT
request_at AS day,
SUM(IF(status = 'cancelled_by_client', 1, 0)) / COUNT('X') AS cancel_rate
FROM Trips t
WHERE EXISTS (
SELECT 'X'
FROM Users u
WHERE u.users_id = t.client_id
AND banned = 'No'
) AND request_at BETWEEN '2013-10-01' AND '2013-10-03'
GROUP BY request_at
)
SELECT
d.day AS 'Day',
ROUND(d.cancel_rate + c.cancel_rate,2) AS 'Cancellation Rate'
FROM d
INNER JOIN c ON d.day = c.day;
295. Find Median from Data Stream
Description of the Problem
The median is the middle value in an ordered integer list. If the size of the list is even, there is no middle value, and the median is the mean of the two middle values.
For example, for arr = [2,3,4], the median is 3.
For example, for arr = [2,3], the median is (2 + 3) / 2 = 2.5.
Implement the MedianFinder class:
MedianFinder() initializes the MedianFinder object.
void addNum(int num) adds the integer num from the data stream to the data structure.
double findMedian() returns the median of all elements so far. Answers within \(10^{-5}\) of the actual answer will be accepted.
Example 1:
Input
["MedianFinder", "addNum", "addNum", "findMedian", "addNum", "findMedian"]
[[], [1], [2], [], [3], []]
Output
[null, null, null, 1.5, null, 2.0]
Explanation
MedianFinder medianFinder = new MedianFinder();
medianFinder.addNum(1); // arr = [1]
medianFinder.addNum(2); // arr = [1, 2]
medianFinder.findMedian(); // return 1.5 (i.e., (1 + 2) / 2)
medianFinder.addNum(3); // arr[1, 2, 3]
medianFinder.findMedian(); // return 2.0
Constraints:
-10^5 <= num <= 10^5- There will be at least one element in the data structure before calling findMedian.
- At most
5 * 10^4calls will be made toaddNumandfindMedian.
Follow up:
- If all integer numbers from the stream are in the range
[0, 100], how would you optimize your solution? - If
99%of all integer numbers from the stream are in the range[0, 100], how would you optimize your solution?
Solution
Tags: Heap
Explanation
Construct a self-balancing max-min heap such that all numbers are evenly distributed to left-max-heap and right-min-heap.
[_,_,_,...,max] [min,...,_,_,_]
The left-max-heap contains elements less than or equals to max, the right-min-heap contains elements greater than or equals to min.
If the difference of the size of two heaps is greater than one, then extract the element and put it into another heap.
Thus, the median can be found by extracting element(s) from heap(s).
Answer to follow-up question
First follow-up question:
For the first question, we use an array to count the number of occurrence of each number. Find the median by cumulative frequency of numbers.
For instance, Frequency of [0,1,2,3] is [12,4,5,10]. The total frequency is 31. The cumulative frequency is [12,16,21,31]. Hence, 2 is the median.
Second follow-up question:
For the second question, we use an array to count the number of occurrence of each number in [0, 100] and variables to count the number of occurrence of number that less than 0 and greater than 100. Again, use the cumulative frequency to find the median.
Code (Java)
class MedianFinder {
private final PriorityQueue<Integer> leftMaxHeap;
private final PriorityQueue<Integer> rightMinHeap;
public MedianFinder() {
leftMaxHeap = new PriorityQueue<Integer>(Collections.reverseOrder());
rightMinHeap = new PriorityQueue<Integer>();
}
public void addNum(int num) {
Integer leftMax = leftMaxHeap.peek();
if (leftMax != null && num <= leftMax){
leftMaxHeap.add(num);
if (leftMaxHeap.size() - rightMinHeap.size() > 1 ){
rightMinHeap.add(leftMaxHeap.poll());
}
}else {
rightMinHeap.add(num);
if (rightMinHeap.size() - leftMaxHeap.size() > 1 ){
leftMaxHeap.add(rightMinHeap.poll());
}
}
}
public double findMedian() {
if ( (leftMaxHeap.size() + rightMinHeap.size()) % 2 == 0){
return leftMaxHeap.peek() / 2.0 + rightMinHeap.peek() / 2.0;
}else if (leftMaxHeap.size() > rightMinHeap.size()){
return leftMaxHeap.peek() * 1.0;
}else{
return rightMinHeap.peek() * 1.0;
}
}
}
/**
* Your MedianFinder object will be instantiated and called as such:
* MedianFinder obj = new MedianFinder();
* obj.addNum(num);
* double param_2 = obj.findMedian();
*/
Complexity
nis the total number of elements input into self-balancing heap.
Time Complexity
- \( T(n) = O(n\lg n + 1) \)
- The time complexity of
findMedianis constant. - The time complexity of
addNumis bounded by \( \lg(k) \) where \(k\) is the current size of the heap plus 1.- Insertion costs \( \lg(k) \)
- Self-balancing costs \( \lg(k) \) (Popping element and push the element)
- Total: \( c+c \lg 2 + c \lg 3 + ... + c \lg n \lt O(n \lg n + 1) \)
- The time complexity of
Auxiliary Space
- \( S(n) = O(n) \)
- Store n elements
601. Human Traffic of Stadium
Description of Problem
Table: Stadium
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| visit_date | date |
| people | int |
+---------------+---------+
visit_date is the column with unique values for this table.
Each row of this table contains the visit date and visit id to the stadium with the number of people during the visit.
As the id increases, the date increases as well.
Write a solution to display the records with three or more rows with consecutive id's, and the number of people is greater than or equal to 100 for each.
Return the result table ordered by visit_date in ascending order.
The result format is in the following example.
Example 1:
Input:
Stadium table:
+------+------------+-----------+
| id | visit_date | people |
+------+------------+-----------+
| 1 | 2017-01-01 | 10 |
| 2 | 2017-01-02 | 109 |
| 3 | 2017-01-03 | 150 |
| 4 | 2017-01-04 | 99 |
| 5 | 2017-01-05 | 145 |
| 6 | 2017-01-06 | 1455 |
| 7 | 2017-01-07 | 199 |
| 8 | 2017-01-09 | 188 |
+------+------------+-----------+
Output:
+------+------------+-----------+
| id | visit_date | people |
+------+------------+-----------+
| 5 | 2017-01-05 | 145 |
| 6 | 2017-01-06 | 1455 |
| 7 | 2017-01-07 | 199 |
| 8 | 2017-01-09 | 188 |
+------+------------+-----------+
Explanation:
The four rows with ids 5, 6, 7, and 8 have consecutive ids and each of them has >= 100 people attended. Note that row 8 was included even though the visit_date was not the next day after row 7.
The rows with ids 2 and 3 are not included because we need at least three consecutive ids.
Solution
Tags: SQL GROUP BY
Explanation
Consider the following example: \[ \begin{matrix} id: & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10 \\ \text{Greater than or equals to 100}: & No & No & Yes & Yes & Yes & Yes & No & Yes & Yes & No \\ \end{matrix} \]
After filtering and assigning ROW_NUMBER(), we get:
\[
\begin{align}
id: & [\text{3 4 5 6 8 9}] \\
rowNumber: & [\text{1 2 3 4 5 6}] \\
groupNumber: & [\text{2 2 2 2 3 3}] \\
\end{align}
\]
Finally, filter the group numbers by their occurrences (using HAVING)
\[
\begin{align}
id: & [\text{3 4 5 6}] \\
groupNumber: & [\text{2 2 2 2}] \\
\end{align}
\]
Code (MySQL)
WITH filtered_result AS (
SELECT *, id - ROW_NUMBER() OVER (ORDER BY id) AS group_number
FROM Stadium
WHERE people >= 100
)
SELECT t1.id, t1.visit_date, t1.people
FROM filtered_result t1
WHERE t1.group_number IN (
SELECT t2.group_number
FROM filtered_result t2
GROUP BY t2.group_number
HAVING COUNT(*) >= 3
)
ORDER BY t1.visit_date
Reference
1220. Count Vowels Permutation
Description of Problem
Given an integer n, your task is to count how many strings of length n can be formed under the following rules:
- Each character is a lower case vowel (
'a','e','i','o','u') - Each vowel
'a'may only be followed by an'e'. - Each vowel
'e'may only be followed by an'a'or an'i'. - Each vowel
'i'may not be followed by another'i'. - Each vowel
'o'may only be followed by an'i'or a'u'. - Each vowel
'u'may only be followed by an'a'. Since the answer may be too large, return it modulo10^9 + 7.
Example 1:
Input: n = 1
Output: 5
Explanation: All possible strings are: "a", "e", "i" , "o" and "u".
Example 2:
Input: n = 2
Output: 10
Explanation: All possible strings are: "ae", "ea", "ei", "ia", "ie", "io", "iu", "oi", "ou" and "ua".
**Example 3: **
Input: n = 5
Output: 68
Constraints:
1 <= n <= 2 * 10^4
Solution
Tags: Dynamic Programming Recurrence
Explanation
Very simple: A string end with a produces a string end with e and so on.
a -> e
e -> a i
i -> a e o u
o -> i u
u -> a
In other words
a' = e + i + u
e' = a + i
i' = e + o
o' = i
u' = i + o
[**]Remember to do modulo for each addition in order to prevent overflow.
[***] Most of answer written in Rust in LeetCode requires casting (from i64 to i32). This solution requires none.
Code (Rust) - Clean Code
impl Solution {
pub fn count_vowel_permutation(n: i32) -> i32 {
let modulo = 1_000_000_007;
let addition = |a,b|(a + b) % modulo ;
let mut a = 1;
let mut e = 1;
let mut i = 1;
let mut o = 1;
let mut u = 1;
let mut a_next = 1;
let mut e_next = 1;
let mut i_next = 1;
let mut o_next = 1;
let mut u_next = 1;
for _ in 2..=n {
a_next = [e, i, u].into_iter().fold(0, addition) % modulo;
e_next = (a + i) % modulo;
i_next = (e + o) % modulo;
o_next = i % modulo;
u_next = (i + o) % modulo;
// replace old values
a = a_next;
e = e_next;
i = i_next;
o = o_next;
u = u_next;
}
return [a_next, e_next, i_next, o_next, u_next].into_iter().fold(0, addition) % modulo;
}
}
Code (Rust) - Dirty Code but may be faster
impl Solution {
pub fn count_vowel_permutation(n: i32) -> i32 {
let modulo = 1_000_000_007;
let mut a = 1;
let mut e = 1;
let mut i = 1;
let mut o = 1;
let mut u = 1;
let mut a_next = 1;
let mut e_next = 1;
let mut i_next = 1;
let mut o_next = 1;
let mut u_next = 1;
for _ in 2..=n {
a_next = ( (e + i) % modulo + u ) % modulo;
e_next = ( a + i ) % modulo;
i_next = ( e + o ) % modulo;
o_next = ( i ) % modulo;
u_next = ( i + o ) % modulo;
// replace old values
a = a_next;
e = e_next;
i = i_next;
o = o_next;
u = u_next;
}
return (((((((a_next + e_next)% modulo) + i_next) % modulo) + o_next) % modulo) + u_next) % modulo;
}
}
Complexity
Time Complexity
- \(T(n) = \Theta(n)\)
Auxiliary Space
- \(S(n) = O(1)\)